System Design - Rate Limiting
Here is implements low-level for rate limiting.
1. Low-level Design
import time
from collections import deque, defaultdict
class SlidingWindowRateLimiter:
def __init__(self, limit: int, window_size_sec: float):
"""
limit: maximum number of requests allowed per IP in a time window
window_size_sec: size of the sliding window in seconds
"""
self.limit = limit
self.window_size = window_size_sec
self.requests = defaultdict(deque) # maps IP → deque of timestamps
def allow_request(self, ip: str) -> bool:
"""
Returns True if the request from `ip` is allowed, False if rate-limited.
"""
now = time.time()
timestamps = self.requests[ip]
# Step 1️⃣: Shrink window — remove old timestamps
while timestamps and now - timestamps[0] > self.window_size:
timestamps.popleft()
# Step 2️⃣: Check limit
if len(timestamps) < self.limit:
timestamps.append(now)
return True
else:
return False
def remaining_requests(self, ip: str) -> int:
"""Optional helper — how many requests are left for this IP."""
now = time.time()
timestamps = self.requests[ip]
# Clean up old entries before counting
while timestamps and now - timestamps[0] > self.window_size:
timestamps.popleft()
return max(0, self.limit - len(timestamps))
2. High-level Design
2.1. Requirements
-
The system should identify clients by user ID, IP address, or API key to apply appropriate limits.
-
The system should limit HTTP requests based on configurable rules (e.g., 100 API requests per minute per user).
-
When limits are exceeded, the system should reject requests with HTTP 429 and include helpful headers (rate limit remaining, reset time).
2.2. Non-functional requirements
-
Performance: The system should introduce minimal latency overhead (< 10ms per request check).
-
High-availability: The system should be highly available. Eventual consistency is ok as slight delays in limit enforcement across nodes are acceptable.
-
Scalability: The system should handle 1M requests/second across 100M daily active users.
2.3. High-level design
2.3.1. The system should identify clients by user ID, IP address, or API key to apply appropriate limits.
-
User ID: After loginned.
-
IP Address: Come from X-Forwarded-For header.
-
API Key: Common for developer APIs. Each key holder gets their own limits. Most typically, this is denoted in the X-API-Key header.
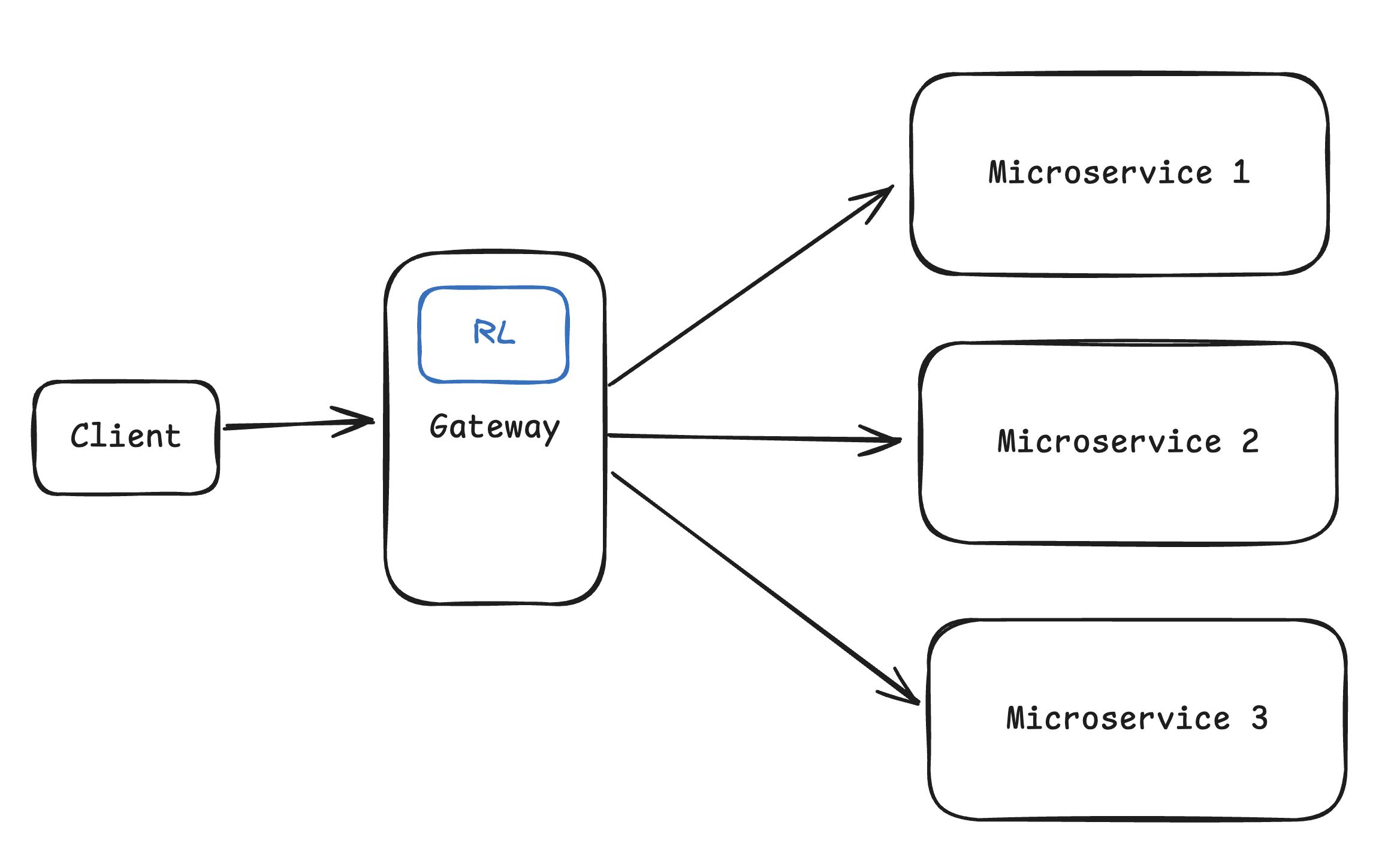
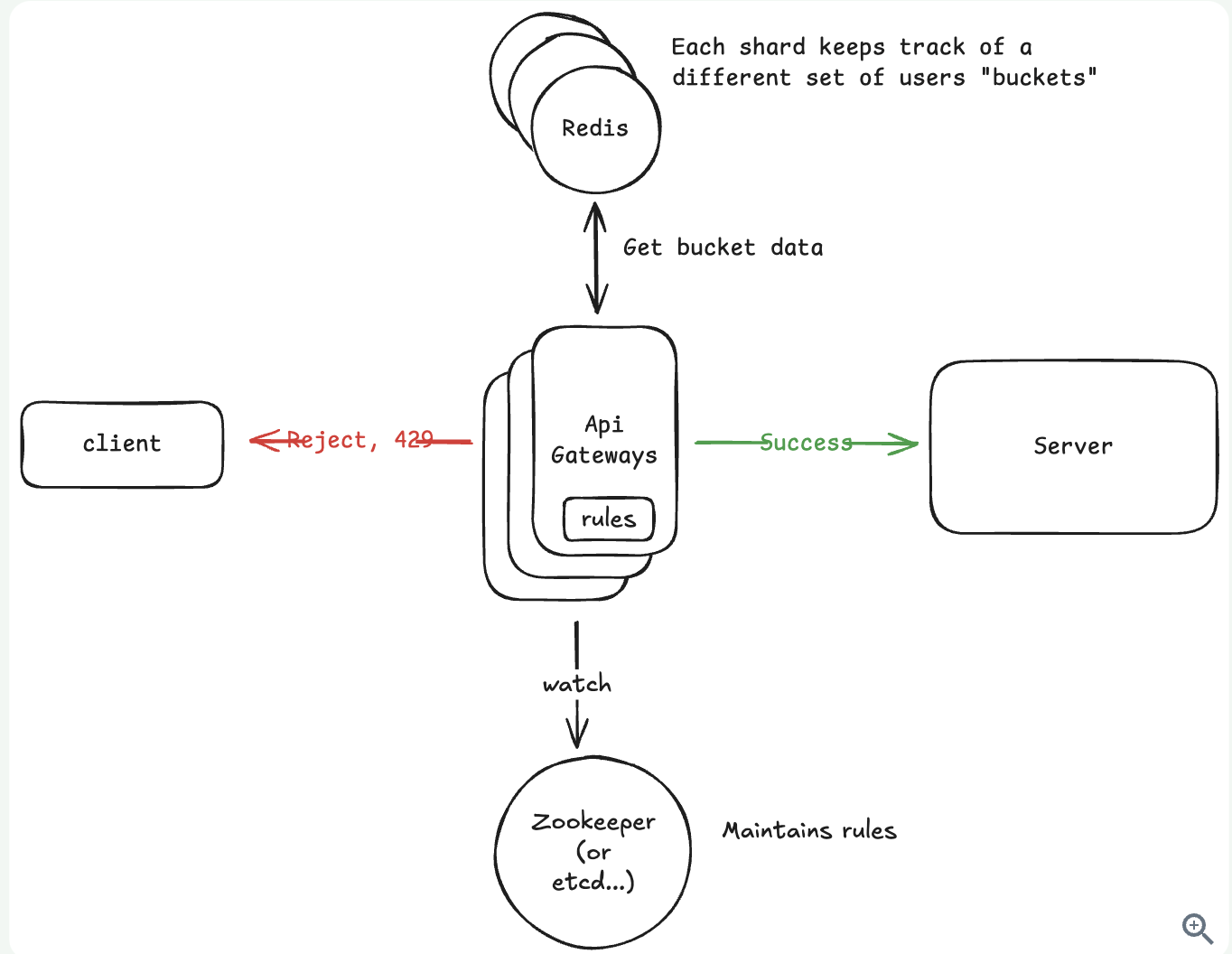
2.3.2. The system should limit requests based on configurable rules
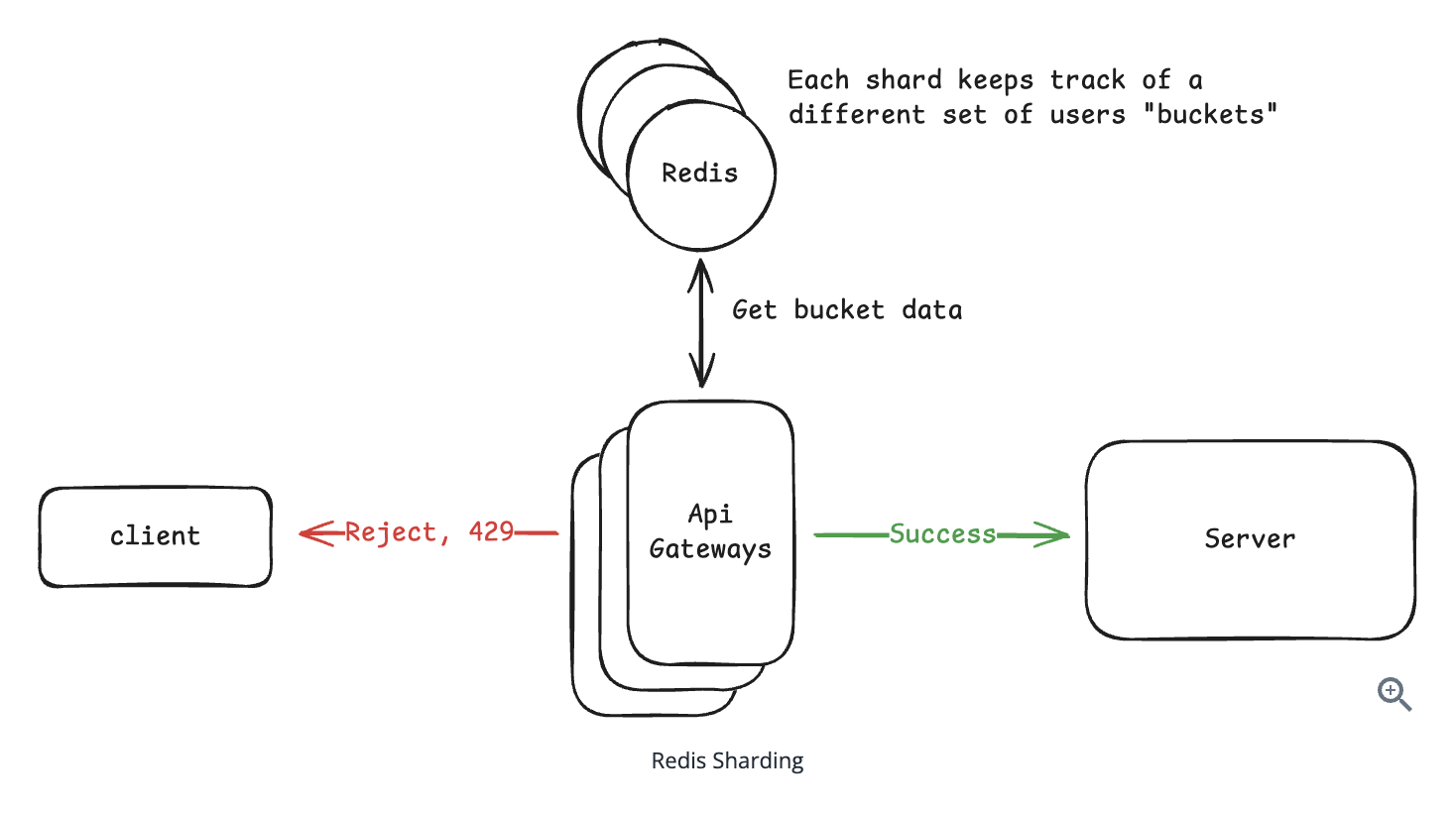
2.3.3. When limits are exceeded, the system should reject requests with HTTP 429 and include helpful headers (rate limit remaining, reset time).
HTTP/1.1 429 Too Many Requests
X-RateLimit-Limit: 100
X-RateLimit-Remaining: 0
X-RateLimit-Reset: 1640995200
Retry-After: 60
Content-Type: application/json
{
"error": "Rate limit exceeded",
"message": "You have exceeded the rate limit of 100 requests per minute. Try again in 60 seconds."
}
2.4. Dive deep
2.4.1. Scalability: The system should handle 1M requests/second across 100M daily active users.
Solution: Shard users by buckets + consistent hashing.
Notes: When a node failed, it shards to N4.
2.4.2. High-availability: The system should be highly available. Eventual consistency is ok as slight delays in limit enforcement across nodes are acceptable.
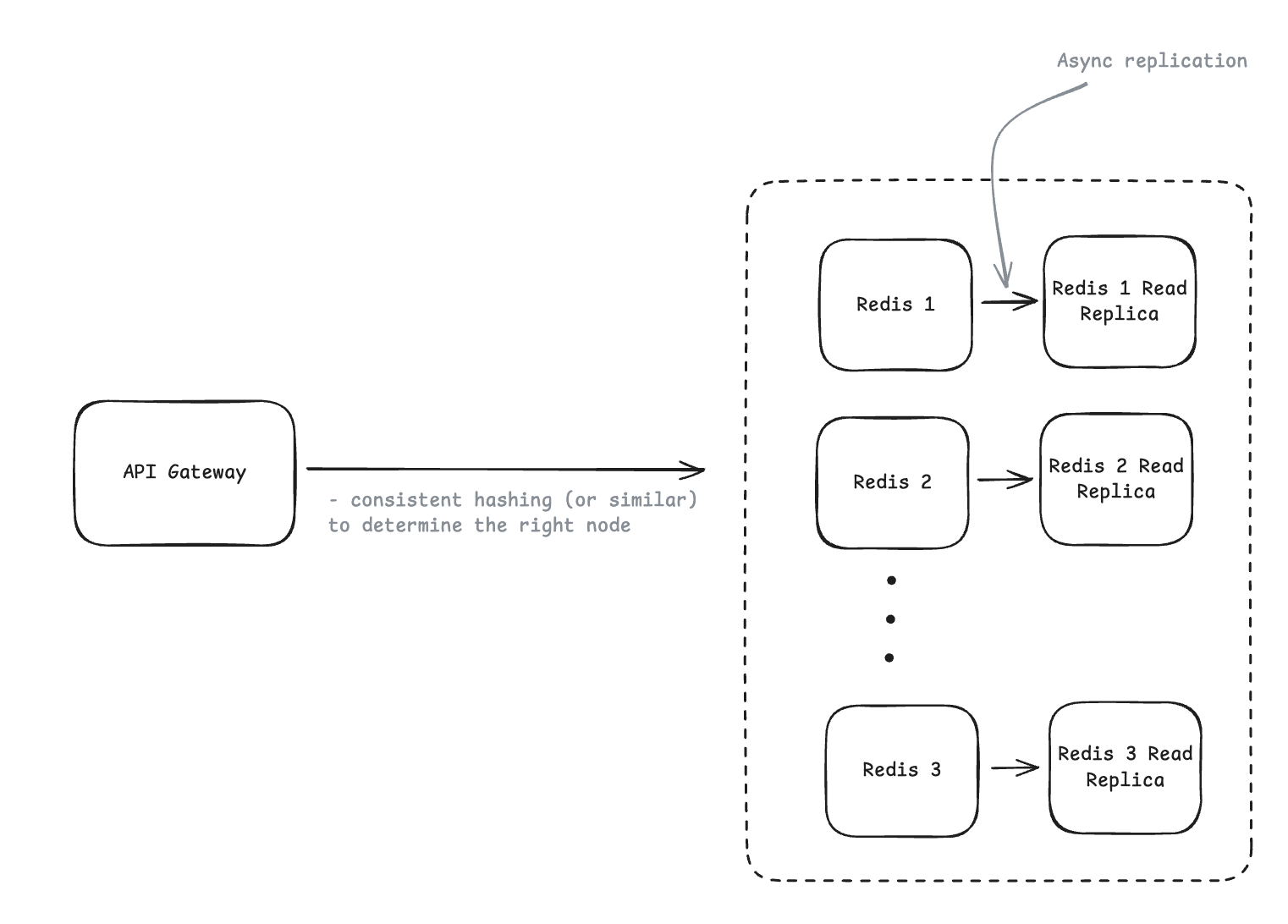
2.4.3. Performance: The system should introduce minimal latency overhead (< 10ms per request check).
- Geographic distribution provides the biggest latency wins.
=> Deploy your rate limiting infrastructure close to your users e.g. API gateways and Redis clusters in multiple regions
2.4.4. How do we handle hot keys (viral content scenarios)?
Solution: DDOS Layer > Rate Limiter > API Gateway.
2.4.5. How do we handle dynamic rule configuration?
Solution: Use ZooKeeper.