
Kafka - Dive deep
1. Problems
- There are 2 problems:
-
Producer to Broker: delivery handled by acknowledge by the broker.
-
Consumer to Broker: Based on polling => consumer handle how many time to consume messages.
2. Producer to Broker
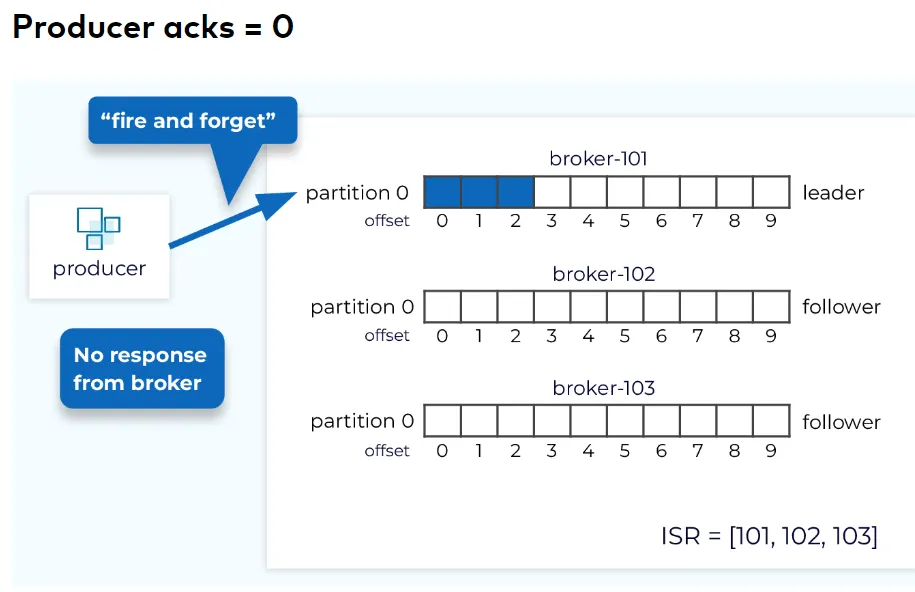
2.1. Fire and forget
-
Producer Setting: acks = 0
-
There is no durability guarantee. But It’s the fastest.
=> At-most-once delivery, as the messages may be lost but are not duplicated.
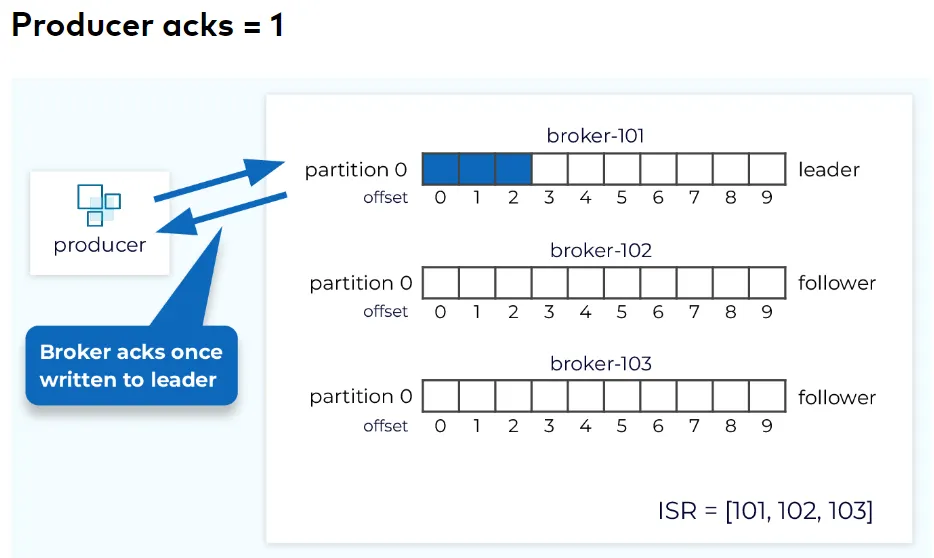
2.2. Only the Leader Broker acknowledged the message
-
Producer Setting: acks = 1
-
The durability is much more improved but there is a little chance that the message lost => when leader downtime.
=> Exacly-once delivery.
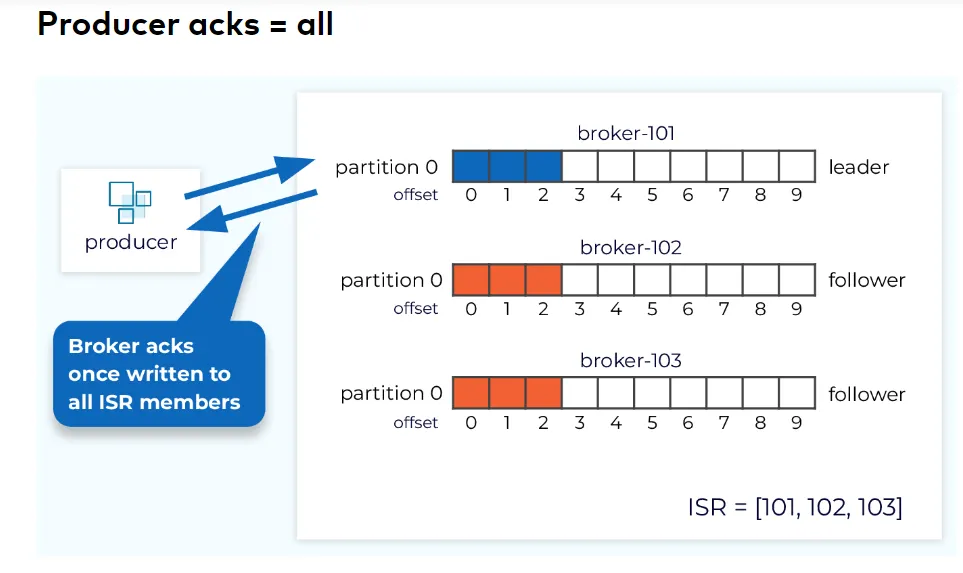
2.3. All the brokers acknowledged
-
Producer Setting: acks = all
-
The durability is strongest => The latency is about 2.5 times more than just leader.
=> At least one.
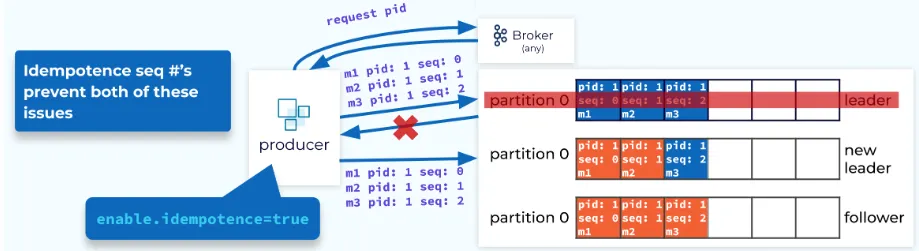
2.4. Issue 1: Producer send duplicated messages
- When a General doesn’t receive the acknowledgement, it doesn’t know if the message itself failed or if the acknowledgement failed
=> It sends the message multiple times leading to duplicate messages.
- Solution: Broker assigns each producer an ID and deduplicates messages using a sequence number.
3. Consumer to Broker
3.1. Offet:
- Kafka used offet to decide the order of message in a partition.
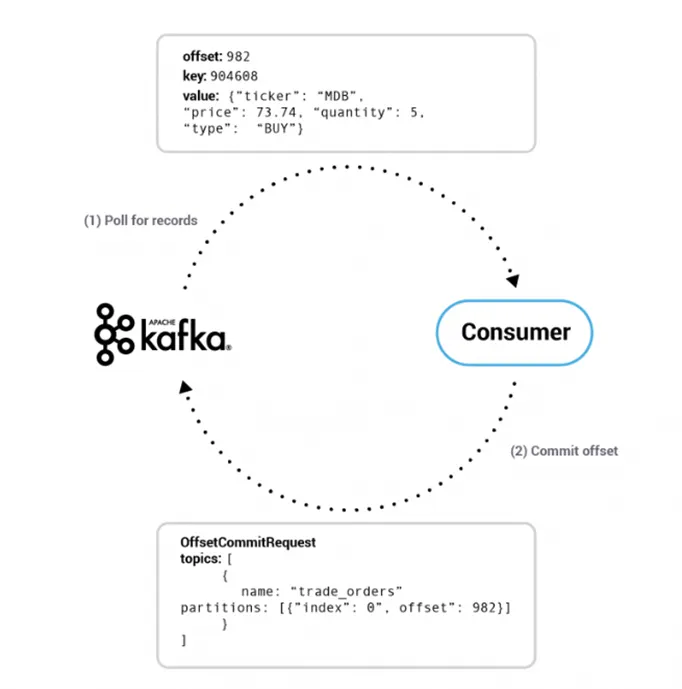
3.2. Broker:
- A leader partition 1 can belonged to Broker A.
=> Another follower partition 1 belonged to Broker B, Broker C.
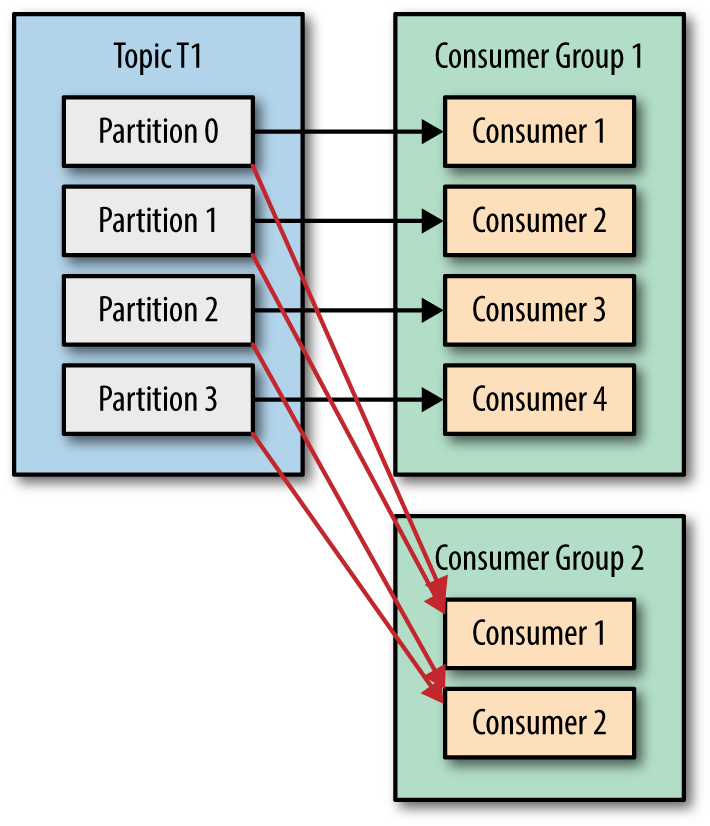
3.3. At most once — Messages may be lost but are never re-delivered.
- The same message is not read again even if the consumer crashes while processing.
3.4. At least once — Messages are never lost but may be redelivered.
3.4.1. Case 1: Bug in consumer application pulls message from broker
- Offset is committed before the messages are processed & the consumer application crashes before processing the directive.
=> Process lost messages.
3.4.2. Case 2: The message is processed but the application crashes before Offset is committed.
=> Process duplicate messages.
3.4.3. Case 3: Exactly once
-
The offsets are stored in an external data store rather than Kafka => identify by an id.
-
Implement an Idempotent logic in the application — this could be to store the offset of the message along with the data before processing it.
4. Master-followers in partitions and brokers, and topic.
- Master parition belong to broker 1, followers partition can belong to broker 2, broker 3.
Partition 0 (Leader: Broker1) --> followers: Broker2
Partition 1 (Leader: Broker2) --> followers: Broker3
Partition 2 (Leader: Broker3) --> followers: Broker1