System Design: Streaming Music Platform - Spotify
Here is some concepts about system design of Streaming Music Platform - Spotify
1. Design
Link: https://blog.algomaster.io/p/15e25749-5569-4367-aec7-11da93ec1c7b
2. Database Design
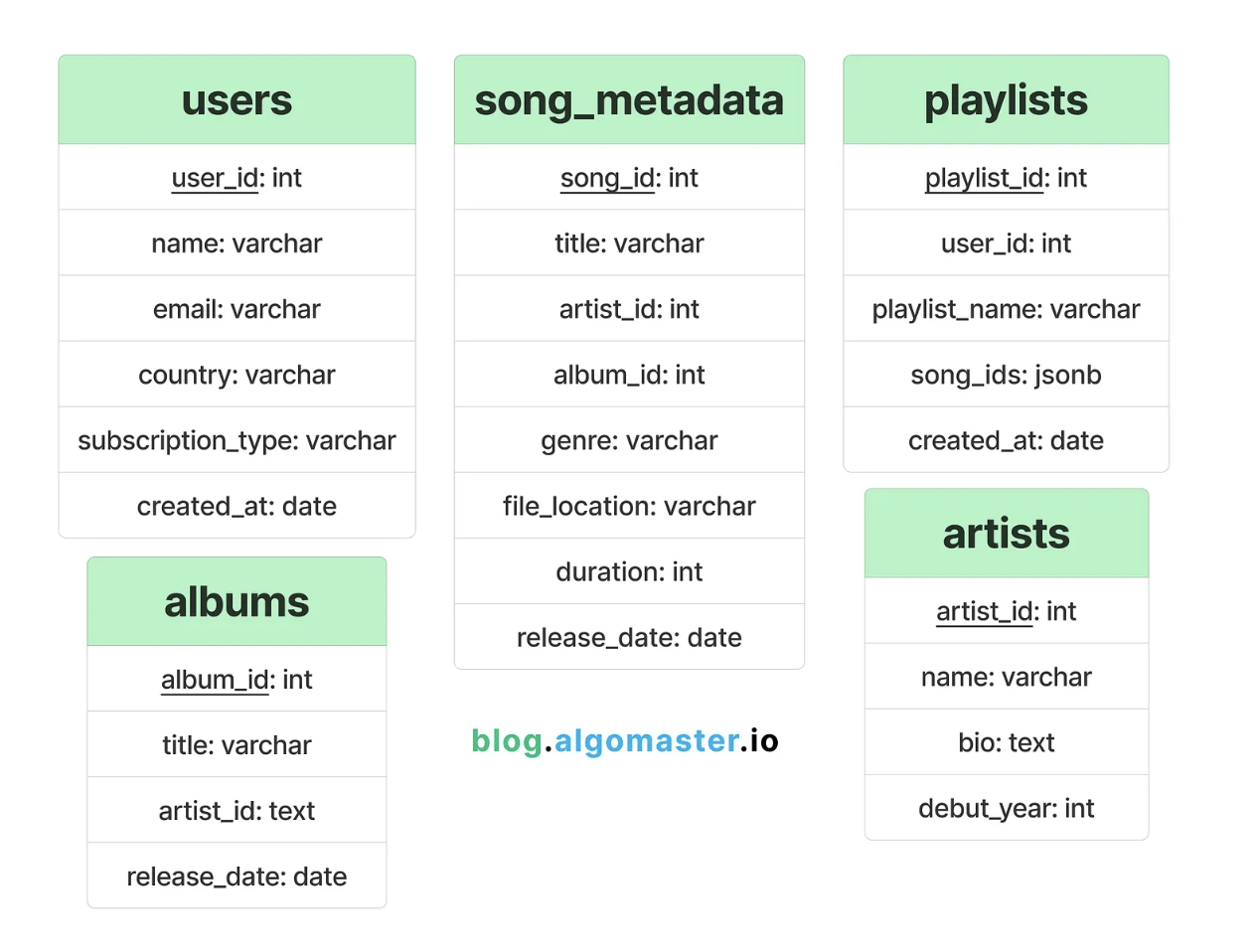
2.1. Relational Databases for Structured Data
To store highly structured data like user profiles, playlists, songs metadata, artists and albums, we can use a relational databases like PostgreSQL or MySQL.
2.2. NoSQL Databases for Unstructured Data
To store unstructured and semi-structured data, we can use NoSQL databases like MongoDB, Cassandra, or DynamoDB.
NoSQL databases provide flexibility and scalability, making them ideal for handling highly dynamic data such as recommendations, and search indices.

2.3. Search Index
Search indices are stored in NoSQL databases like Elasticsearch to allow quick, fuzzy search queries across songs, artists, and albums.

2.4. Distributed Storage System
To store large volumes of audio and ad files, we can use a distributed storage system like AWS S3.
S3 ensures high durability and availability, making it an ideal storage solution for serving large static files.
Example Storage Object:
-
File: https://s3.amazonaws.com/spotify/songs/blinding_lights.mp3
-
Metadata: File size: 4 MB, Bitrate: 128 kbps, Format: MP3
2.5. Content Delivery Network (CDN)
Original music files are stored in a distributed storage system (e.g., AWS S3). The CDN pulls from this origin storage when a song is requested for the first time and caches it for future requests.
Notes: Object storage used for storaging, back-up. CDN uses for querying.
2.6. Caching Layer
Caching frequently accessed data like user preferences, popular songs, or recommendations can improve performance.
A caching layer like Redis can be used to store this data temporarily.
Examples of Cached Data:
-
Search Queries: Cache popular search queries to avoid hitting the search index repeatedly.
-
Popular Songs: Frequently streamed songs can be cached to reduce database queries.
-
User Preferences: Store the user’s liked songs and playlists in the cache for faster retrieval.
SET user:preferences:12345 "{liked_songs: [1, 2, 3], playlists: [10, 11, 12]}"
GET user:preferences:12345
2.7. Analytics and Monitoring Data (Data Warehousing)
Analytics and monitoring data are critical for tracking user engagement, system performance, and identifying potential issues.
Data is aggregated and processed in a data warehouse or distributed data stores (e.g., Hadoop, BigQuery).
Key Use Cases for Analytics:
-
User Engagement: Data on streams, skips, and playlist additions are used to generate insights into user behavior.
-
System Monitoring: Logs from various services are used to monitor system health, detect anomalies, and perform performance tuning.
-
Royalty Calculations: Streaming data is used to calculate payments for artists based on song plays and geographic reach.
3. Key Service
3.1. Music Streaming Service
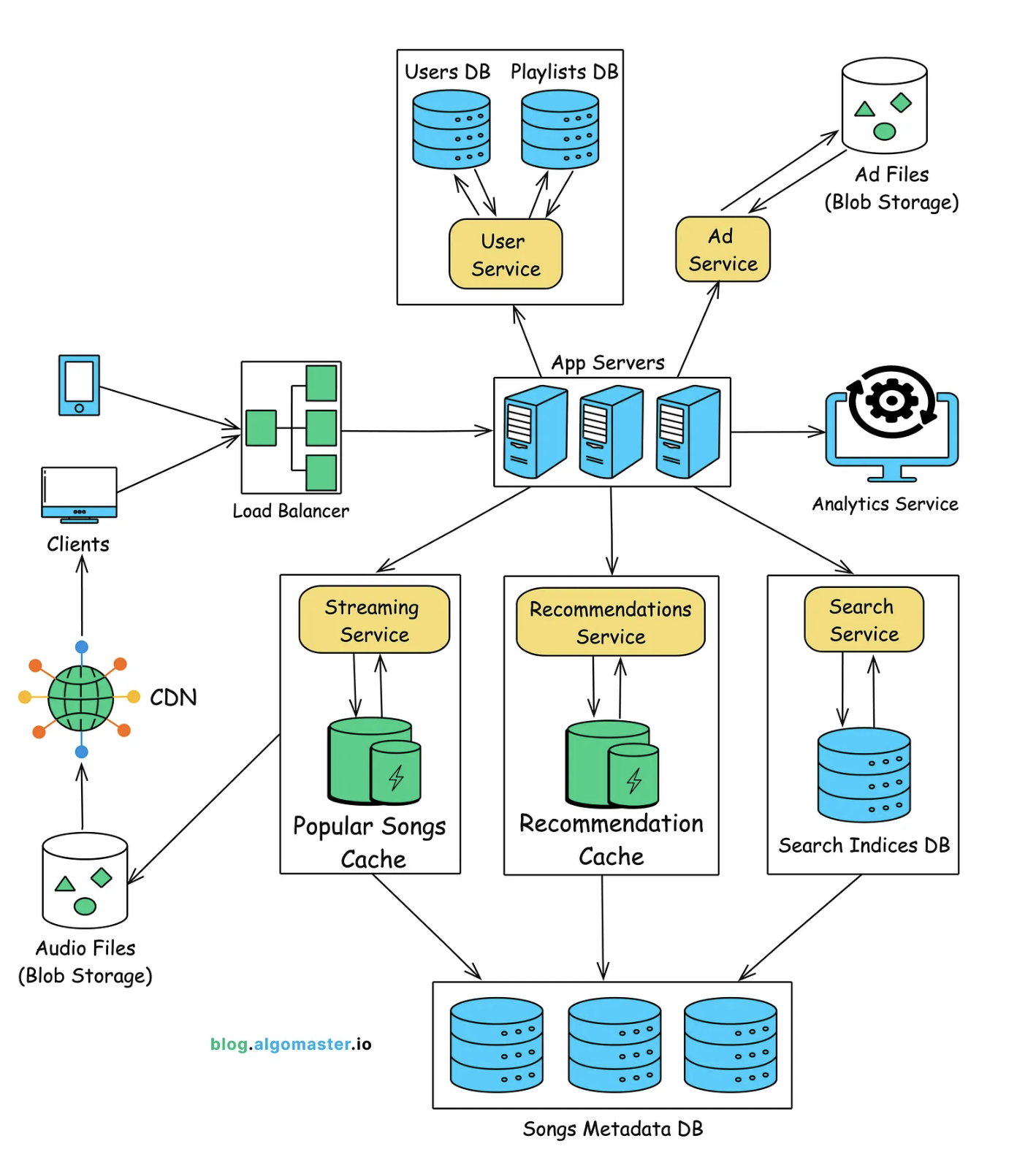
The Streaming Service is at the heart of Spotify’s architecture, responsible for delivering music content efficiently, securely, and reliably to millions of users in real time.
The actual delivery of music files is managed by a Content Delivery Networks (Cloudflare, AWS CloudFront). This ensures that music is served from geographically distributed servers close to the user, minimizing latency and bandwidth consumption.
Request Workflow:
-
Client sends a streaming request (e.g., /stream/{song_id}).
-
The App server authenticates the user and routes the request to the Streaming Service.
-
If the song is not in the CDN, the Streaming Service retrieves the audio file’s location (from the blob storage) and pushes the file to the nearest CDN edge server. The CDN returns a URL to the streaming service to stream the audio.
-
The CDN URL is returned to the client, allowing the client to stream the audio.
3.2. Recommendation Service
The recommendation system analyzes the user’s listening habits, likes, and playlists. It uses a combination of collaborative filtering (based on users with similar preferences) and content-based filtering (based on song metadata).
Collaborative Filtering (User, Song Behavior)
Collaborative filtering is one of the most commonly used techniques in recommendation systems. This method leverages the behavior of users with similar music tastes to generate recommendations.
-
User-Based Collaborative Filtering: This technique groups users based on their listening history. For example, if User A and User B both frequently listen to the same set of artists and songs, the system may recommend songs that User A has listened to but User B hasn’t.
-
Item-Based Collaborative Filtering: In this technique, songs are recommended based on their similarity to songs the user has previously liked. If many users who like Song X also like Song Y, the system recommends Song Y to users who have listened to Song X.
Content-Based Filtering (Song Genre, Artist)
Content-based filtering focuses on the properties of songs, such as genre, artist, album, tempo, and instrumentation, to recommend similar songs to users.
-
Song Attributes: Spotify collects metadata on each song, including genre, tempo, mood, and instruments. This data is used to recommend songs with similar attributes to what the user has already liked or listened to.
-
Artist Similarity: If a user listens to multiple songs from a particular artist, the system may recommend songs from similar artists, based on shared attributes (e.g., genre, style).
3.3. Search Service
The Search Service in Spotify allows users to find songs, artists, albums, playlists, and podcasts from a vast catalog efficiently.
The architecture of Search Service can be broken down into the following key components:
-
Query Parser: Interprets and normalizes the user’s search query.
-
Search Index: A dynamically updated index that contains metadata for all songs, artists, albums, and playlists. A search engine like Elasticsearch or Apache Solr can be used to build and manage this index.
-
Ranking Engine: Once the search index returns matching results, the Ranking Engine sorts the results to ensure that the most relevant results appear at the top.
-
Personalization Layer: Customizes search results based on the user’s listening history, preferences, and demographic information.
-
Search Autocomplete: Provides users with suggestions as they type their queries, speeding up the search process.
-
Cache Layer: Caches frequently searched queries to improve performance and reduce the load on the backend.
-
Search Index Updater: Ensures that the search index stays up to date with new content being added to Spotify’s catalog.
4. Notes
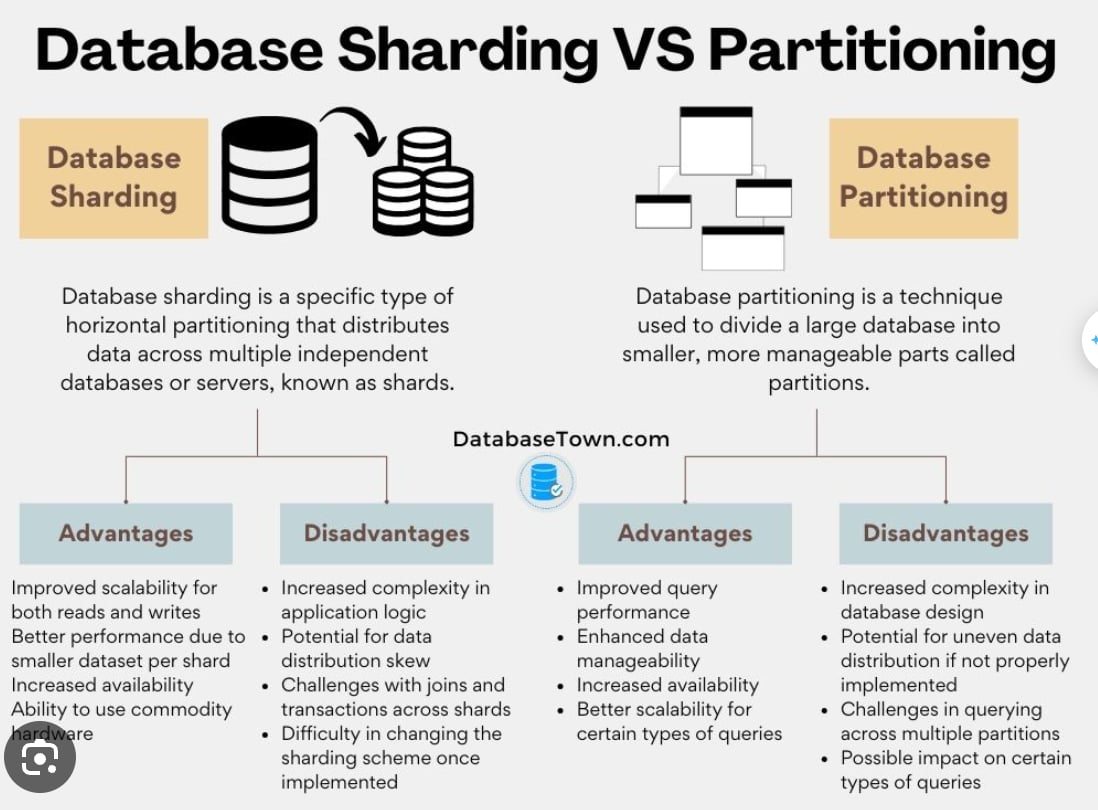
-
Partitions is split a big table to managable tables.
-
Sharding is one of parition technique: horizontal partition.