
System Design: Streaming Video Platform - Youtube
Here is some concepts of System Design: Streaming Video Platform - Youtube.
1. Design
Link: https://blog.algomaster.io/p/design-youtube-system-design-interview
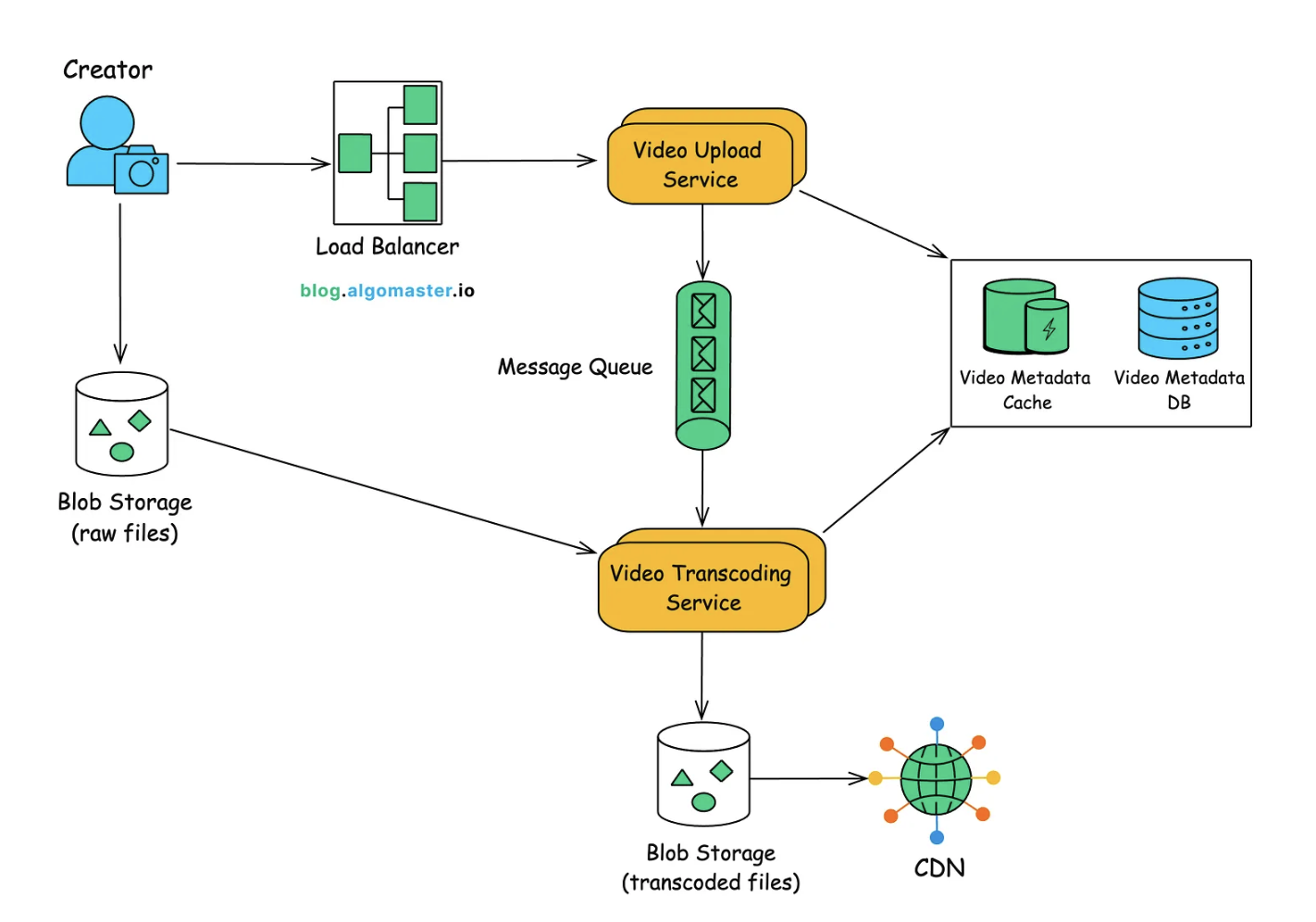
Components
Video Upload Service
- Handles video uploads from users, often using multi-part uploads for large files.
- Generates a pre-signed URL for direct upload to Object Storage (e.g., AWS S3) from the user’s device.
- Creates a new entry in the video metadata database when upload is initiated.
- Sends a transcoding job to a Message Queue after a successful upload.
Video Transcoding Service
- Reads raw video files from Blob Storage and encodes it into multiple resolutions/bitrates (e.g., 240p, 480p, 720p, 1080p) for adaptive streaming.
- Generates thumbnails and extracts metadata (e.g., duration, codec).
- Stores transcoded video segments in Object Storage or CDN-backed storage for efficient delivery.
Message Queue
- Decouples video upload from transcoding to ensure scalability.
- Stores job requests from the Upload Service and allows the Transcoding Service to process them asynchronously.
Storage
- Raw Video Storage – Stores unprocessed uploads in a blob store before transcoding.
- Processed Video Storage – Stores transcoded video segments in a CDN-backed system.
- Metadata Storage – Stores structured video metadata in a relational database.
2. Workflow
2.1. Upload Workflow
Notes: Remember that client will update to CDN using pre-signed url for save bandwidth.
-
Initiating the Upload
- A logged-in content creator selects a video file via a frontend client (web, mobile, or smart TV interface).
- The client sends an upload request to the Video Upload Service via the API Gateway.
- Includes metadata such as
channel_id,title,description,tags, and other relevant fields.
- Includes metadata such as
- The server generates a pre-signed URL for an Object Storage bucket (e.g., AWS S3).
- The client uploads the video directly to Object Storage using the pre-signed URL.
-
Upload to Object Storage
- Large files often use multi-part or chunked uploads. The client splits a large file into smaller “parts” (chunks), each typically ranging from a few MBs to tens of MBs.
- If the connection drops in the middle of the upload, only the incomplete chunk needs to be re-sent rather than re-uploading the entire file from scratch.
- In many multi-part implementations, each chunk can be uploaded concurrently using multiple threads or connections.
- Large files often use multi-part or chunked uploads. The client splits a large file into smaller “parts” (chunks), each typically ranging from a few MBs to tens of MBs.
-
Metadata Creation & Status Update
- Once the upload call is initiated, the Upload Service creates a new record in the Videos table with:
video_id(primary key)channel_id(which user or channel this belongs to)title,description,tagsstatus = "processing"(since it’s not yet ready for viewing)upload_date = now()
- The Videos table record includes a reference or URL to the uploaded file in Object Storage, e.g.,
raw_file_url: <https://bucket/raw/12345.mp4>. - The Upload Service returns a response to the client with the newly created
video_id.
- Once the upload call is initiated, the Upload Service creates a new record in the Videos table with:
-
Sending a Transcoding Job
- The Upload Service places a message on a queue (e.g., RabbitMQ, AWS SQS, Kafka) containing:
video_idraw_file_urltarget_resolutionstarget_formats
- The Upload Service places a message on a queue (e.g., RabbitMQ, AWS SQS, Kafka) containing:
2.2. Transcoding Workflow
-
Processing the Job
- A Transcoding Service worker polls the queue, retrieves the message, and extracts:
raw_file_url,video_id,target_resolutions, andtarget_formats. - The worker downloads the raw file from the Object Storage (raw files bucket).
- A Transcoding Service worker polls the queue, retrieves the message, and extracts:
-
Video Transcoding Process
- The worker uses video processing tools (e.g., FFmpeg) to create adaptive bitrate variants:
- Low resolution (240p or 360p) - For slow connections.
- Standard resolution (480p or 720p) - For average connections.
- High resolution (1080p or 4K) - For high-bandwidth users.
- Each variant is split into small segments (e.g., 2-10 seconds long) for adaptive streaming.
- The worker writes the final video segments and streaming manifests to a “transcoded” bucket in Object Storage or a CDN-backed storage path, e.g.:
https://cdn.provider.com/videos/11111/720p/....
- The worker may also generate a thumbnail at this stage (capturing a frame at X seconds into the video).
- The worker uses video processing tools (e.g., FFmpeg) to create adaptive bitrate variants:
-
Status Update & Database Sync
- Once transcoding finishes successfully, the Transcoding Service calls an internal API (e.g.,
PUT /videos/{video_id}/status) on the Metadata Service. - The Videos metadata table record is updated:
status = "live"(video is now available for streaming).transcoded_urlfields updated with resolution-based URLs.thumbnail_urlupdated.
- If transcoding fails, the worker marks
status = "failed", optionally storing an error message. - Once the transcoded files are in object storage or an origin server, the CDN automatically caches content at edge locations to serve playback requests.
- Future playback requests are served from CDN edge nodes, reducing origin bandwidth usage and improving streaming performance.
- Once transcoding finishes successfully, the Transcoding Service calls an internal API (e.g.,
2.3. How Video Transcoding Works
Video transcoding is the process of converting a raw video file into multiple formats, resolutions, and bitrates to ensure smooth playback across different devices, network speeds, and screen sizes.
To achieve smooth and adaptive streaming, we use Adaptive Bitrate Streaming (ABR). This allows the client to dynamically switch between different quality levels based on the user’s network speed, ensuring an optimal viewing experience.
Notes: Adaptive Bitrate Streaming (ABR)is a technique for streaming videos by network condition of client.
![]()
When a video is uploaded, it undergoes post-processing to convert it into a streamable format. This process is often executed in steps using a pipeline to produce the final output.
Step 1: Uploading & Storing the Raw Video
- A user uploads a raw video file (e.g., MP4, MOV, AVI).
- The raw file is stored in Object Storage (e.g., AWS S3) directly from the user’s device.
- Metadata is recorded in the Videos Metadata Table, including:
video_iddurationstatus = "processing"
Step 2: Job Dispatching via Message Queue
- Once the raw file is uploaded, the Upload Service sends a message to a Message Queue (e.g., Kafka).
- The Transcoding Service workers poll messages from the queue and process jobs asynchronously.
- Example Message Sent to Queue:
{ "video_id": 456, "raw_file_url": "s3://video-uploads/12345.mp4", "target_resolutions": ["240p", "480p", "720p", "1080p"], "target_formats": ["HLS", "DASH"] } - The target formats are HLS (HTTP Live Streaming) and DASH (Dynamic Adaptive Streaming over HTTP), the two most widely used adaptive streaming protocols.
Step 3: Decoding the Raw Video
- The raw video file is split into smaller segments (e.g., 10-second chunks) using a tool like FFmpeg.
- Each segment is transcoded separately into multiple formats.
- Segments can be transcoded parallelly using multiple FFmpeg instances on worker nodes.
Step 4: Encoding into Multiple Resolutions
- Each video is encoded into multiple bitrates/resolutions (e.g., 240p, 360p, 480p, 720p, 1080p).
- A “master” manifest references these resolutions, letting the player decide which one to fetch.
Step 5: Generating Video Segments for Streaming
- Each resolution is split into short segments (2-10 seconds) for HLS and DASH adaptive streaming.
- Why Segment-Based?
- Short segments allow quick adaptation. If the network changes mid-video, the next segment can be requested at a different bitrate/resolution with minimal playback disruption.
Step 6: Generating Thumbnails
- A thumbnail image is created as a preview.
- The user can later update the thumbnail manually.
Step 7: Storing Transcoded Files in Object Storage
- The transcoded videos, thumbnails, and manifest files are stored in Object Storage (e.g., AWS S3).
- Example storage structure:
s3://video-platform/videos/12345/240p.m3u8 s3://video-platform/videos/12345/480p.m3u8 s3://video-platform/videos/12345/thumbnail.jpg
Step 8: Updating the Database & CDN
- The Video Metadata Table is updated with:
Transcoded URLsfor different resolutionsThumbnail URLstatus = "live"(video is ready to stream).
- The CDN caches video segments for low-latency streaming and fast access.
2.4. Video Streaming
The Video Streaming Component is responsible for orchestrating video playback and adaptive streaming.
Rather than pushing large media files through a single backend endpoint, modern platforms provide manifests describing how to fetch the media segments.
Clients then download video segments directly from the CDN, which offloads huge bandwidth demands from your core application servers.
Below is the typical workflow to support smooth video streaming:
-
User Initiates Playback
- The user clicks on a video thumbnail or opens a video page on a web browser, mobile app, or smart TV app.
-
Fetching Video Metadata
- The client app sends a request to the Video Metadata Service via the API Gateway or Load Balancer to retrieve:
- Video metadata (title, description, thumbnail, channel info).
- A streaming manifest URL (e.g., HLS
.m3u8or DASH.mpdfile), which guides the player in fetching and playing the video.
- The client app sends a request to the Video Metadata Service via the API Gateway or Load Balancer to retrieve:
-
Downloading the Manifest File
- The client makes an HTTP GET request to the CDN to download the manifest file.
- This manifest file contains links to video segments in multiple resolutions and bitrates (generated in the video transcoding process), allowing adaptive streaming based on the user’s internet speed.
-
Retrieving Video Segments & Adaptive Bitrate
- The video player chooses an initial bitrate (often mid or low) and downloads the first segment from the CDN.
- It continuously monitors download speed and buffer level. If downloads arrive quickly, it may switch to higher quality; if the connection slows, it drops to lower quality.
-
Continuous Playback
- The player sequentially requests segments:
segment_01.ts,segment_02.ts, etc., or corresponding.m4sfragments for DASH. - It buffers data, rendering frames to the user in a near real-time fashion.
- The player sequentially requests segments:
-
End of Playback / Seeking
- When playback concludes or the user seeks (e.g., moves the timeline forward), the player calculates which segments to request next and continues the same segment download process.
2.5. Video Search
A video platform’s Search Engine enables users to quickly find videos by keywords in titles, descriptions, tags, or even transcribed captions.
This requires:
-
Indexing: Transforming raw metadata into a data structure optimized for text retrieval (e.g., inverted indexes).
-
Query Parsing: Understanding user queries, possibly with keyword-based or NLP-based improvements.
-
Ranking/Scoring: Determining how relevant each video is to the user’s query, often incorporating signals like view count, recency, or user preferences.
Architecture and Components:
- Whenever a video is uploaded or updated, the system pushes the new/updated metadata to a search indexing service (e.g., Elasticsearch, Solr, or a custom system).
- This process might be asynchronous—meaning a short delay between upload and availability in search results.
- Inverted Index: Each word maps to a list of video IDs where it appears, enabling fast lookups.
- The Search Service queries the inverted index with relevant filters (e.g., language, upload date).
- A scoring/ranking algorithm sorts results by relevance, which might incorporate additional signals like popularity or watch time.
- If the user is logged in, search could factor in watch history, subscriptions, or topic preferences.
3. Database Design
A large-scale video platform like YouTube requires handling both structured data (e.g., user accounts, video metadata, subscriptions) and unstructured/semistructured data (e.g., video files, search indexes, logs).
Typically, you’ll combine multiple database solutions to handle different workloads:
-
Relational Databases (SQL) for user profiles, channel data, and video metadata.
-
NoSQL / Key-Value Stores for high-volume event logs (e.g., watch history) or caching frequently accessed data.
-
Search Indexes for keyword-based searches (title, tags, description).
-
Object Storage for the actual video files and thumbnail images.
3.1. Relational Tables
Given the structured nature of user profiles, video metadata, subscriptions, and relationships, a relational database (like PostgreSQL or MySQL) is often well-suited.
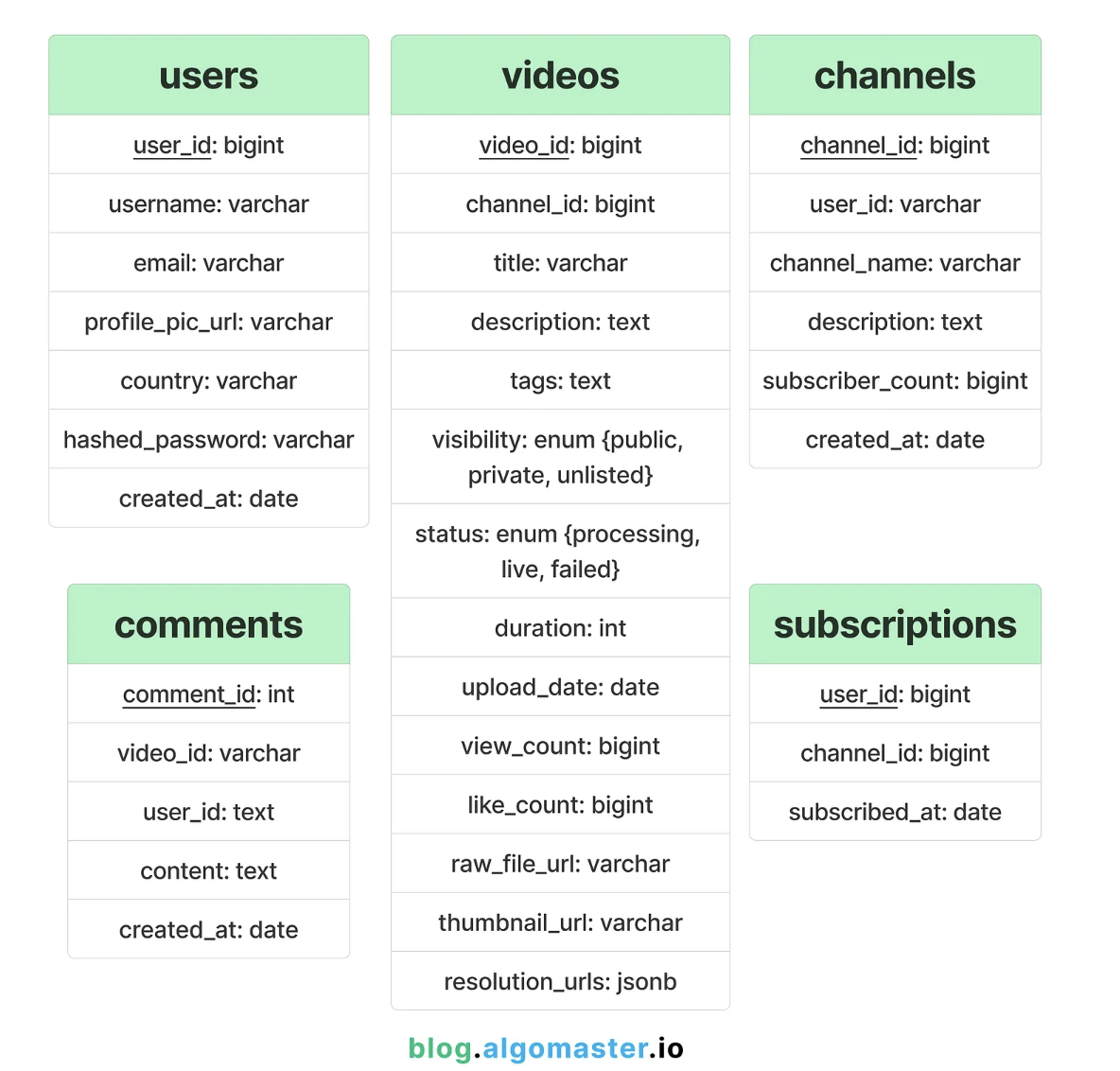
Example resolution_urls JSON format:
{
"240p": "https://cdn.provider.com/videos/12345/240p.m3u8",
"480p": "https://cdn.provider.com/videos/12345/480p.m3u8",
"720p": "https://cdn.provider.com/videos/12345/720p.m3u8",
"1080p": "https://cdn.provider.com/videos/12345/1080p.m3u8"
}
3.2. Search Indexes
For fast video searches, we can store video metadata in Elasticsearch.
{
"video_id": 12345,
"title": "Learn System Design",
"description": "This is an in-depth guide...",
"tags": ["system design", "architecture", "scalability"],
"views": 500000,
"upload_date": "2025-01-30T10:15:00Z"
}