
Hugging Face - AI
Source code: https://github.com/jkmaina/huggingface_book
1. Machine Learning
1.1. Supervised Learning
-
Data has label.
-
Example:
- Predict house prices.
- Classify email is spam or not.
- Recoginize handwritten digits.
1.2. Unsupervised Learning.
-
Group data by patterns
-
Example:
- Classify customer to segments.
- Detect anomolies in financial transaction.
- Reduce dimensions of data for easier visualization.
1.3. Reinforcement Learning
-
Learning by rewards and penalties
-
Example:
- Robotics
- Game development, AI agents.
- Dynamic pricing system.
2. Deep learning
2.1. Neural networks work
-
Appky in image recognition, natural language processing, speech synthesis.
-
Contains:
- Input layer: input data.
- Hidden Layers: multiple mathematic computations to identify patterns.
- Output Layer: produce the result, classify label or numerical value.
-
Activation functions: determine how signals are pased through the network
- ReLU: number/linear.
- Sigmoid: Binary classification problem 0 or 1.
- Softmax statistic tasks from 0 - 1.
-
Training neural network: backpropagation.
3. Machine Learning Programming
- Using the library scikit-learn.
3.1. Dataset Utilities
-
load: load smallm built-in datasets.
-
fetch: fetch larger datasets from external sources.
3.2. Preprocessing tools
-
StandardScaler: scale missing data to average, standar deviation.
-
MinMaxScaler: Change numbers to fit within a range.
-
OneHotEncoder: Covert text data into numbers by change it to a column 0 or 1.
3.3. Paramameters:
-
param_grid: n_estimators, max_depth, min_samples_split for Grid Search.
-
Machine learning models: LinearRegression, LogisticRegression, RandomForestClassifier (Decision Tree), SupportVectorMachines (Hyperlane),
3.4. Key metrics
-
Accuracy: If a model makes 100 predictions and 90 are correct, the accuracy = 90%.
-
Precision: If the model predicts 20 people have a disease, but only 15 really do, precision = 15/20 = 75%.
-
Recall: If 30 people actually have a disease, and the model correctly identifies 25, recall = 25/30 = 83%.
-
F1 Score: Harmonic mean of Precision and Recall, If Precision = 75% and Recall = 83%, then F1 ≈ 79%.
-
Support: 70 healthy, 30 sick → Support for “healthy” = 70, Support for “sick” = 30.
4. Building Content Moderation System
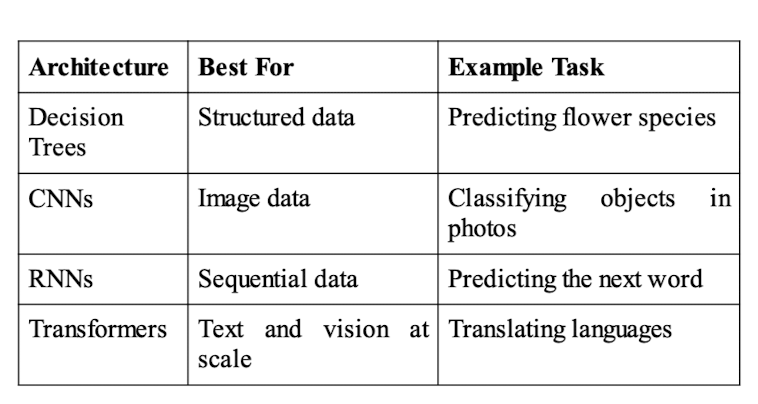
4.1. Decision Tree (Text/Structure Data)
-
The model is work well for text but not image/audio.
-
Model: DecisionTreeClassifier, RandomForestClassifier.
4.2. CNN (Image Data)
-
Split the image to small parts, analyze them and stick everything together.
-
Encoder: AutoFeatureExtractor, AutoModelForImageClassification
-
Model: google/vit-base-patch16-224.
4.3. RNN (Sequential Data)
-
Remember past input to make sense the current one.
-
Encoder: AutoTokenizer
-
Model: AutoModelForCausalLM(“gpt2”), know how to continue the sentences.
4.4. Transformer (NLP and Vision)
-
Using tensorflow, transformer.
-
Encoder: BertTokenizer, bert-based-uncased.
-
Model: TFBertModel, bert-base-uncased.
5. LLM Pipelines
5.1. Text Classification
-
Classify text is positive or negative.
-
Model: distilbert/distilbert-base-uncased-finetuned-sst-2-english
5.2. Summarization
-
Summary long text to concise summaries.
-
Model: facebook/bert-lage-cnn
5.3. Other models
-
facebook/bart-large-cnn: Best all-around performance
-
google/pegasus-xsum: Best for very concise summaries
-
t5-small: Best if you want something fast and lightweight
-
sshleifer/distilbart-cnn-12-6: Good balance of speed and quality
5.4. Fine-tuning a Pre-trained Model
-
Prepare the Dataset: Convert your data into a format compatible with Hugging Face.
-
Load the Pre-trained Model: Choose a model suited for your task.
-
Define the Trainer: Set up training parameters, including evaluation metrics, e.g. learning rates, evaluation strategy => save the model to ./my_model.
6. Hugging Face Repo
- Push the model after trained to Hugging Face as Github.
7. Multi-Modal Transformers
-
Multi-modal Transformers process and combine data from different modalities, such as text and images.
-
Example: image captioning, visual question answering, text-to-image alignment.
8. Zero-Shot Classification
-
Zero-shot classification is like asking a person to categorize something they’ve never seen before by using common sense.
-
It enables models to categorize text without being specifically trained for that task.
-
Model: zero-shot-classification.
-
Tips: clear categories, enough context, start simple.
9. Fine-tuning for domain adaption
-
Insert the dataset to models => train.
-
Expose it to the API.
10. Few-shot learning
-
Few-shot learning uses pre-trained models to adapt to new tasks with minimal labeled data.
-
The data is lacked of label.
-
Encoder: AutoModelForSeq2SeqLM.
-
Model: t5-small
11. Metrics
11.1. Classification Metrics
-
Accuracy: Good when classes are balanced and all errors are equally costly.
-
Precision: Important when false positives are costly.
-
Recall: Important when false negatives are costly.
-
F1-Score: Good when you want a balance between precision and recall, and when classes are imbalanced.
11.2. Text summarization and translation (Generation Metrics)
-
BLEU: how closely the generated text matches the reference text.
-
ROUGE: Compares overlaps between generated text and reference text.
-
METEOR: Evaluate semantic similarity.
11.3. Regression & Predict sequences
-
Mean Squared Error (MSE): For regression task.
-
Perplexity: Check the predict sequences text.
12. Domain-Specific Evaluations
-
Finance: sentiment models based on financial impact (e.g. market sentiment classification), e.g. model + fine-tuning: google/flan-t5-base
-
Healthcare: medical text models classify conditions and diseases.
-
E-comerece: Analyze user behaviors and recommendations.
=> Compare multi-model to test precision.
13. Top models at December 2024
- mistralai/Mistral-Large-Instruct-2411
Architect: transformer (NLP, Computer Vision) + 70 billion parameters.
Use cases: Exeptional for text generation and intruction-following tasks, chatbot.
- Qwen/Qwen2.5-72B
Architect: Transformer + 72 billion parameters
Use cases: Machine Translation, text summarization.
- Qwen/Qwen2.5-32B
Architect: Transformer + 32 billion parameters
Use cases: Sumarization, Question answerng, conversational AI.
- Qwen/Qwen2.5-14B
Architect: Transformer + 14 billion parameters
Use cases: Chatbots and medium-scale applications.
- Qwen/Qwen2.5-7B
Architect: Transformer + 7 billion parameters
Use cases: chatbots, smaller-scale applications.
- google/gemma-2-2b-jpn-it
Architect: Transformer + 2 billion parameters
Use cases: Multilingual content creation and translation.
- google/flan-t5-large
-
Architect: Fine-tuned variant with T5 model.
-
Use cases: Academic research.
- 01-ai/Yi-1.5-9B
-
Architecture: Transformer + 9 bilition parameters.
-
Use cases: Sentiment analysis, customer insights,
- Qwen/Qwen1.5-110B
-
Architecture: Transformer + 110 bilion parameters
-
Use case: Cross-lingual applications.
- IntervitensInc/internlm2_5-20b-llamafied
-
Architecture: 20 billion parameter model optimized for structured tasks.
-
Use cases: Document summarization, data extraction.
Key insights:
-
Scalability Matters: Larger models like Qwen/Qwen2.5-72B and Qwen1.5- 110B deliver high performance but require significant computational resources.
-
Specialization Adds Value: Models like google/gemma-2-2b-jpn-it excel in niche domains, proving the importance of task-specific tuning.
-
Efficiency is Key: Smaller models, such as Qwen/Qwen2.5-7B, balance performance and resource usage, making them suitable for edge applications.
14. Deployment and Scaling
14.1. Deployment
-
Direct API deployment.
-
Containered deployment.
-
Cloud deployment: AWS SageMaker, Google Vertex AI.
-
On-premise deployment
14.2. Production Deployment
- Deploy to virtual machine or containerization.
14.3. Deploying Models with Serverless Architectures
-
Deploy model to AWS SageMaker.
-
Deploy AWS Lambda function
14.4. Accelerating Inference with GPUs
-
Increase the speed of inference time.
-
Change the model to ONNX format, to deploy to GPU Nvidia, install NVIDIA Triton
14.5. Use case product:
-
Customer support chatbots.
-
Real-time social media monitoring.
-
Financial risk analysis.
15. Optimize model performance
15.1. Quantization:
- Reduce from 32-bit precision to 16-bit, 8-bit
15.2. Model Pruning
- Prunning without losing significant loss of accuracy.
15.3. Distillation
- Use larger model (Teacher) to train a smaller model (student)
15.4. Distributed Training
-
Data paralellism: processed in multiple GPUs, and result are aggregated.
-
Model parallelism: Split across multiple devices, and each device handling a subset of the layers.
15.5. Cloud Solution
-
AWS SageMaker
-
Google Vertex AI.
15.6. Monitoring
-
Horizontal Scaling: K8s.
-
Monitoring Tool: Grafana.
-
Auto scaling: CPU/GPU ultilization.
15.7. Model Prunning
-
Remove weights: remove in smaller features, assuming they contribute less to the model predictions.
-
Remove layers in model architecture.
-
Dynamic prunning based on runtime conditions.
16. NLP
16.1. Text Classification
16.1.1. Use cases
-
Sentiment Analysis: Determine comment is positive, negative or neutral.
-
Spam detection: detect an email is spam or not.
-
Topic categorization: classify news is politics, sports or technology.
16.1.2. Data Processing
- Text processing
-
Tokenization: breaking text into smaller chunk/units.
-
Cleaning: clean noise data.
-
Normalization: standard it to a consistent format.
- Feature extraction
-
Embedding text to vector.
-
Capturing sematic meaning and contexual relationships.
-
Using techniques like: TF-IDF, Word2Vec, BERT Embedding.
16.1.3. Model selections
- Choose models pre-trained on similar domains.
- Consider computational requirements and latency.
- Balance accurancy with resource contraints.
16.1.4. Sample models
- Model: distilbert-base-uncased-finetuned-sst-2-english
16.2. Named Entity Recognization (NER)
16.2.1. Use cases
-
Information extraction: Extract structured data from unstructured text.
-
Search engines: enhance search results with relevant entities.
16.2.3. References use case
-
Persons (PER): name of individuals.
-
Organization (ORG): companies, institutions, agencies.
-
Locations (LOC): Cities, countries, geographic features.
-
Date/Time expressions (DATE): Temporal references
-
Quantities (QUANTITY): Numerical expressions, measurements
-
Miscellaneous (MISC): Other named entities
16.2.4. Data Processing
- Text processing
-
Tokenization and sentence segmentation
-
Part-of-speech tagging
-
Dependency parsing
- Entity Detection
-
Boundary detection
-
Entity classification.
-
Contextual understanding
16.2.5. Sample models
-
Model: dbmdz/bert-large-cased-finetuned-conll03-english
-
Example: text = “Barack Obama was born in Hawaii and became the 44th President of the United States.”
=> Extracted Information: Person (Barack Obama), Location (Hawaii, United States), and Potentially numbers (44th)
16.2.6. Use cases
-
Creates a class for analyzing news articles
-
Implements confidence thresholds for entity filtering
-
Tracks entity frequencies across multiple articles
-
Categorizes entities by type
-
Provides summary statistics
-
Handles multiple articles in a batch
-
Uses type hints for better code clarity
-
Implements error handling and entity validation
16.3. Question Answering
16.3.1. Use cases
-
Chatbots: provide accurate answers to user queries based on context.
-
Customer support: answer for common questions.
-
Information retrieval: find specific information in documents.
-
Educational Tools: Supporting learning with Q & A.
16.3.2. Data processing
-
Question Processing
- Question understanding.
- Query formulation
- Answer type prediction
-
Context analysis
- Text pre-processing
- Relevant passasge idenfitication.
- Answer extraction.
16.3.3. Sample models
- Model: distilbert-base-cased-distilled-squad
Example:
-
context = “Hugging Face is a company that creates tools for machine learning.”
-
question = “What does Hugging Face create?”
=> Answer: “tool”
16.4. Retrieval Augmented Generation (RAG)
16.4.1. Context
- Use to dynamically fetch relevant information in Internet, or multiple datasources in run time.
16.4.2. Features
-
Retrieve Context Dynamically: Automatically fetch relevant information when responding to queries
-
Generate Synthesized Information: Combine retrieved content with generative AI for better contextual answers.
-
Scale to Larger Knowledge Bases: Process and handle vast document collections effectively.
-
Maintain Conversational Context: Enable follow-up questions while maintaining the thread of the conversation.
-
Update Dynamically: Keep knowledge bases updated to ensure relevance over time.
17. Computer Vision
17.1. Image Classification
-
Facial Recognition
-
Product categories by image
-
Medical imaging.
17.2. Architecture
-
VIT (Vision Transformer)
-
Object Detection:
- YOLO: fast for each speedn and efficiency.
- Faster R-CNN: high accurracy but more computational resource.
- SSD (Single shot multibox detector): balance speed and accuracy.
- Image Generation:
- GANs (Generative Adversarial Networks): create realistic image.
- Diffusion models: transform noise into detailed image, make the image cleaner.
- DALL-E: combing vision and NLP => Gen image and textual description.
- Multi-modal models.
- Image Captioning: Generating captions for image.
- Visual Question Answering (VQA): Answer questions based on image context.
- CLIP (Contrstive Language-Image Pretraining): matching text with image for retrieval and understanding tasks.
17.3. ViT (Vision Transformer)
- Classify 10 images using ViT.
Model: google/vit-base-patch16-224
17.4. Object Detection
-
Autonomous Vehicles: Detecting pedestrians, vehicles, and obstacles
-
Retail and Inventory: Manage inventory.
-
Security: Manage unauthorized activities.
Model: facebook/detr-resnet-50
17.5. Image Generation
-
Art and Design: Generating creative artwork.
-
Content Creation: Producing images for marketing or entertainment.
-
Synthetic Data: Generating training data for machine learning.
Model: CompVis/stable-diffusion-v1-4, diffusers library
17.6. Multi-Modal Models
-
Image Captioning: Generating descriptive captions for images.
-
Visual Question Answering (VQA): Answering questions about images.
-
Content Moderation: Identifying inappropriate content in multimedia.
Model: Salesforce/blip-image-captioning-base
18. Audio Processing
18.1. Speech Recognition
-
Virtual Assistants
-
Transciption services.
-
Accesibility tools
=> Translate speech to text
Model: openai/whisper-base
18.2. Text-to-speech
-
Accesibility Tools
-
Interactive System: Add voice input to chatbots.
-
Entertainment: generate audio for games.
Model: suno/bark-small
18.3. Audio Classification
-
Environment sounds: apply in filter noise in Airpod.
-
Music Genre classification: classify songs by their genres.
-
Speech emotion recognition: detect emotions from speech.
Model: MIT/ast-finetuned-audioset-10-10-0.4593
18.4. Voice CLoning
-
Personal assistants: creating assistants with user-specific voices.
-
Entertainment: replica voices for media or games.
-
Accesibility: Enhance voice restruction for users with speech impairment.
Model: tts = TTS(“tts_models/en/vctk/vits”, gpu=device==”cuda”)
19. Create dataset
19.1. Create datasets
19.2. Preprocessing and Transforming datasets
19.3. Normalize datasets
- normalized_value = (x - min(x))/ (max(x) - min(x))
19.4. Upload datasets
19.5. Visualizae datasets
20. Top datasets in Hugging Face
20.1. GLUE
- GLUE is a benchmark dataset designed to evaluate the performance of NLP models on a variety of language understanding tasks, including sentiment analysis, sentence similarity, and natural language inference.
20.2. IMDB Reviews
-
Customer Feedback Analysis: Analyzing product reviews.
-
Content Moderation: Identifying offensive or negative reviews.
-
Sentiment Analysis: Building models to classify text as positive or negative.
20.3. SQuAD (Stanford Question Answering Dataset)
- SQuAD is a dataset for training and evaluating question-answering models.
20.4. MNIST (Modified National Institute of Standards and Technology)
- MNIST is a collection of handwritten digits commonly used for image classification.
20.5. CIFAR-10
- CIFAR-10 contains images categorized into 10 classes, such as airplanes, cats, and cars.
20.6. Common Voice
- Common Voice is a crowd-sourced dataset of speech recordings for various languages.
20.7. LibriSpeech
- LibriSpeech contains audiobook recordings in English, widely used for ASR.
20.8. COCO (Common Objects in Context)
- COCO provides richly annotated images for object detection, segmentation, and captioning.
20.9. WikiText
- WikiText contains high-quality text extracted from Wikipedia articles.
20.10. SNLI (Stanford Natural Language Inference)
- SNLI is a dataset for natural language inference, categorizing sentence pairs as entailment, contradiction, or neutral.
21. Hugging Face Space
-
Hugging Face Spaces are cloud-hosted environments where you can deploy and showcase machine learning models, applications, and demos.
-
Demo frontend: Streamlit, Gradio
-
Backend: Docker
22. Hugging Face Inference API
- Provide easy to use API to demo it => but it charge the token usage.
=> You can create access token free.
- Tasks:
- Text classification
- Summarization
- Translation
- Question answering
- Image classification
- Object detection
- Audio transcription
23. Deploy Model to Hugging Face Inference API
23.1. Batch Processing
- Process multiple inputs in a single request:
23.2. Deploy model to hugging face
- Fine-tune models on your dataset, upload them to the Hugging Face Hub, and access them via the Inference API.
23.3. Integration with Web Applications
- Integrate with web application using Flask.
23.4. Sample projects
-
Building a Text Summarization App
-
Multi-Model Pipelines: multiple models together to perform complex tasks.
-
Batch Inference: reduce network calls.
-
Create a Python Lambda function to use the Hugging Face Inference API.
-
Monitoring and Logging API Calls
24. Diffusers
- Diffusion models work by gradually adding noise to data (forward diffusion) and then learning to reverse this process (reverse diffusion).
25. Low-Rank Adaptation (LoRA) + Diffusions
- A training technique to fine-tune large models like Diffusers
25.1. SDXL Base Lightning
-
Reduces inference time by up to 3-4x
-
Maintains quality comparable to base SDXL
25.2. Pixel Art XL
- Converting images into pixel art style
25.3. LCM LoRA
- Fast inference with Latent Consistency Models
25.4. ToonYou
- Anime/cartoon style conversion
25.5. Juggernaut XL
- Enhanced detail and realism
25.6. Toy Face
- Toy/plastic figure style conversion
25.7. Detail Tweaker XL
- Enhanced image detail and clarity
25.8. DreamShaper XL
- Overall quality improvement
25.9. Add Detail
- Detail enhancement for specific areas
25.10. Realistic Vision
- Photorealistic image generation
26. KolorsTryOn and Flux:
-
Flux is a series of advanced text-to-image models
-
Model to support full-body image of yourself after trying on clothes.
27. SOTA
- This is a model has set a new record or is among the best available for solving a specific problem => great of the time model.
27.1. Llama Models
-
Developed by Meta.
-
Suitable: text generation, translation.
27.2. Mistral
-
Developed by Mistral AI team.
-
Suitable: Question-answering, text generation.
27.3. Qwen and Coding Models
- Suitable: Coding algorithms
28. Domain-specific models
28.1. Instruction-Pretrained/Finance-Llama3-8B
- Application: Credit Risk Assessment for Loan Applications
28.2. Instruction-Pretrained/Medicine-Llama3-8B - Specialized AI for Healthcare
- Application: Diagnostic Support, Research Summarization, Patient Education, Medical Training
28.3. Law-AI/InLegalBERT - Specialized AI for Legal Applications
- Application: Legal Document Classification, Legal Question Answering.
28.4. Chronos-Bolt-Base
-
Demand Forecasting
-
Financial Predictions
-
Anomaly Detection
-
Climate and Weather Analysis
-
Multivariate Forecasting
29. JavaScript and Transformer
-
Library JavaScript: transformer.js, allow to call with model in Hugging Face by model name.
-
Use case:
-
Text classification: ‘distilbert-base-uncased-finetuned-sst-2-english’.
-
Question and answer: ‘deepset/roberta-base-squad2’
-
30. Text to video models
30.1. THUDM/CogVideoX-5b
- Model to train text to video.
30.2. ByteDance/AnimateDiff-Lightning
- Generating animated sequences from textual prompts with a focus on character and object motion.
30.3. genmo/mochi-1-preview
- A text-to-video model that emphasizes stylized and creative video outputs, blending artistic styles with descriptive prompts.
31. Leaderboards
31.1. Text Classification
-
Task: Classify text into predefined categories.
-
Metrics: Accuracy, F1 score.
-
Top Models:
- distilbert-base-uncased-finetuned-sst-2-english
- roberta-large-mnli
31.2. Question Answering
-
Task: Answer questions based on a given context.
-
Metrics: Exact Match (EM), F1 score.
-
Top Models:
- deepset/roberta-base-squad2
- bert-large-uncased-whole-word-masking-finetuned-squad
31.3. Summarization
-
Task: Generate concise summaries for long documents.
-
Metrics: ROUGE-L, BLEU.
-
Top Models:
- facebook/bart-large-cnn
- t5-small
31.4. Machine Translation
-
Task: Translate text between languages.
-
Metrics: BLEU, METEOR.
-
Top Models:
- Helsinki-NLP/opus-mt-en-fr
- facebook/wmt19-de-en
32. How Leaderboards Are Evaluated
- Datasets Models are evaluated on standardized datasets, such as:
- GLUE: For text classification.
- SQuAD: For question answering.
- CNN/Daily Mail: For summarization.
- Metrics Each leaderboard specifies metrics that reflect model performance:
- Accuracy: Percentage of correct predictions.
- F1 Score: Harmonic mean of precision and recall.
- BLEU: Measures translation quality.
- ROUGE: Evaluates summary relevance.
- Evaluation Protocols
-
Reproducibility: Models must be evaluated in a consistent environment.
-
Fair Comparison: Benchmarks ensure fair comparisons across models.
33. Enterprise Options on Hugging Face
-
Interence Endpoints: Scalability, Security.
-
Private models.
-
AI workflows: AI Workflows provide a structured approach to building and deploying machine learning pipelines.
-
Collaboration tools.
-
Enterprise support.
34. Open-source models
-
Open-Source Models and Datasets
-
Collaborative Tools
-
Funding with NVDIA, Microsoft, Google.