
Principle Software Architect
1. Principle Design
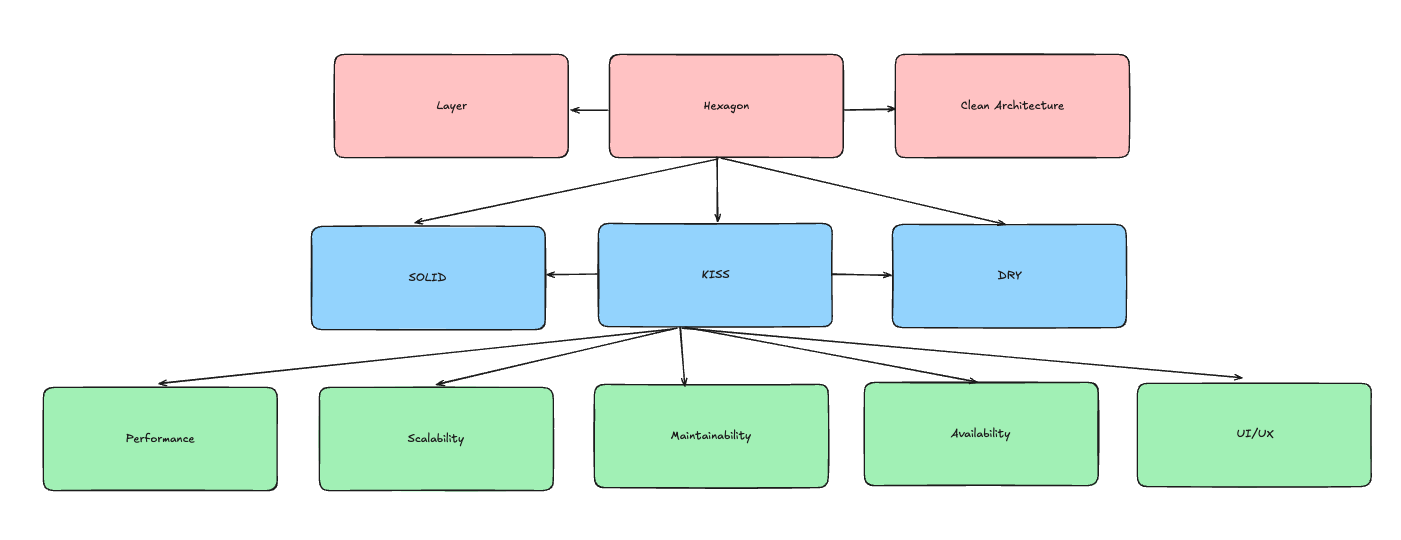
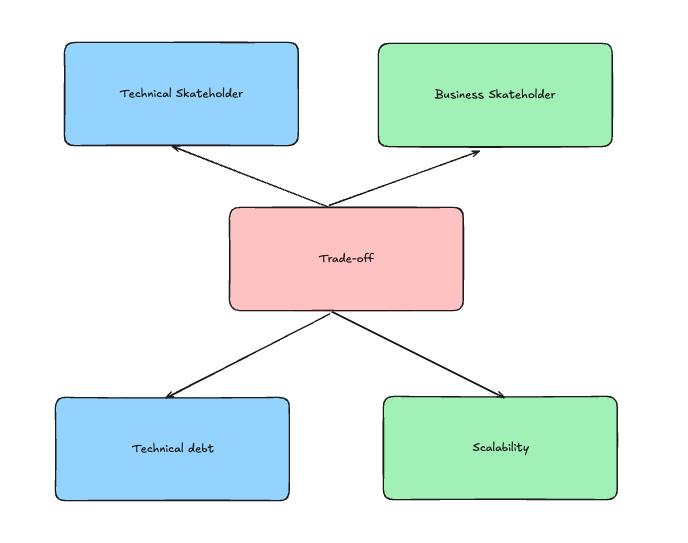
2. Trade-off
3. Focus Point
3.1. Layer Design
- Focus on each layer, higher layer only depend on the lower level.
3.2. Modular Design
-
Each module is independent developed components.
-
Each module can interconnected with other modules.
3.3. Domain-Driven Design
-
Focus on business core.
-
Use bounded contexts to seperate domains.
3.4. Event Driven Architecture:
- Communicate via events, not direct calls.
3.5. Service-Oriented Design
- Design microservices to calling each others.
3.6. User-Centered Design
- Design based on user interaction.
4. Sample Architecture
4.1. SaaS Platform Architecture
-
Microservices with API Gateway.
-
Authenticate with OAuth2, SSO.
-
RBAC.
-
Background job processing (emails, reports).
-
Stripe or Razorpay integration for billing.
-
Logging, Monitoring using ELK, Grafana.
4.2. eCommerece Platform
-
Modular Services: Catalog, Cart, Order, Payment, Delivery.
-
Redis-based caching for product search.
-
Event-driven checkout and order placement.
-
External Integration: Payment Gateway, shipping API.
-
Elastic search for search and filtering.
-
CDN for media assets.
4.3. Banking/ Fintech Architecture
-
Hexagon Architecture: strong boundary enforcement.
-
Encryption at rest and transit: KMS, TLS.
-
Real-time fraud detection using asynchronus processing.
-
Event sourcing and auto logging.
-
Mobile first client apps with biometric auth.
-
KYC, RBI,…
5. Design Security
5.1. Principle of Least Privilege
- A database read-only replca should only have read access.
5.2. Fallback Securely
- Always have fallback mechanism and sanitize error messages.
5.3. Use multi defense layer
- Multiple secure layers: Firewall, authentication, encryption, rate limiting.
5.4. Using secure defaults of platforms.
- The default configuration of the systems should be the most secure one.
5.5. Minimize attack surface
-
Do not expose admin API on public network.
-
Always route to API gateways.
5.6. Separation of Duties
- No single person or component has complete control.
5.7. Don’t trust user input
- Never trust the input from client-side.
5.8. Keep it simple
-
Using OAuth2 instead of building a custom token system.
-
Avoid over-engineering security features => Keep it simple.
5.9. Auditability and Logging
- Log access to critical endpoints, permission escalations and login attempts.
5.10. Open Design
- Do not depend on the security layer, using well-reviewed libraries and protocols.
5.11. Security Threat Modeling
- We can use: STRIDE, DREAD for threat modeling.
5.12. Principles
-
Authentication: Username & Password, MFA, OAuth.
-
Authorization: RBAC, GBAC, PBAC, ACL, Scopes.
-
Encryption: Symmetric, Asymmetric, Hashing, Digital Signatures.
-
Compliance: GDPR, HIPAA, SOC 2.
5.13. Execution
-
Frontend: Cookie constent UX.
-
API Gateway: Enforce geo-IP restriction, throttle suspicious access.
-
Backend: Encrypt sensive fields, audit logs.
-
Data Layer: Use KMS, environment flag.
-
Infrastructure: Use infrastructure as code for auditing.
-
Compliance: use compliance checks tool, e.g. AWS Config, GCP Security Command Center.
6. Design Scalability
6.1. Context
- It doesn’t mean add more servers, it designs that handle more users, more data, more complexity.
6.2. Scaling
-
Vertical Scaling: monolithic applications, not a distributed system => Moore’s Law.
-
Horizontal Scaling: unlimited scaling, stateless system.
-
Load balancing: Round robin, least connections, IP hash.
-
Caching: client-side cache, CDN (edge cache), mem-cache, distributed cache.
-
Sharding: Range-based, Hash-based, Geo-based.
6.3. Microservices && Domain-driven Design
-
Indentify the bounded context, e.g. Driver Management and Ride Matching are seperate bounded context.
-
Use the same Ubiquitous language: Transaction, Authorization, Refund.
-
Aggregate the Entities: Customer, RideDetails, PaymentInfo.
-
Apply ACL for inter-service communication.
6.4. Event-driven
-
Technology: Kafka, RabbitMQ (AMQP, Scheduling Queue), Pub/Sub System.
-
Using Kafka when you need real-time message processing, share messages in group.
-
Using RabbitMQ when you want to have message routing mechanism, share message for each consumer.
-
Using cloud native pub/sub for event-driven systems.
6.5. Serverless
-
A login with AWS Lambda + API Gateway + DynamoDB.
-
Schedule tasks, DynamoDB -> S3 Storage.
-
Use serverless: event-driven, short-lived jobs.
6.6. Eventually Consistency
-
Each replicas have data but not sync together.
-
Asynchronus Messaging.
-
Idempotency.
-
Outbox Pattern.
-
Saga Patterns.
-
Event Sourcing.
7. Design Operation
7.1. Devops
-
Design for CI/CD: canary deployments, blue-green deployments, rolling updates.
-
Using IaC (Infrastructure as code) to manage networks, servers, databases.
-
Using secrets for environment variables.
7.2. Observability
-
Logging
- Log levels: info, debug, warn, error, fatal
- Aggregation: Elastic Search, Kibana.
- Info: requestID, userID, traceID.
-
Monitoring: Metrics, Dashboards, Alerts
- Infrastructure: CPU, memory, disk, network.
- Application: requests rate, number of requests, latencies.
- Business: Orders processed, sign-up, conversions.
- Dashboards: Grafana, Data dog.
- Alerts: SLO-based alerts (e.g. 95% of API responses should be < 300ms)
-
Distributed Tracing
- Trace context propagation: using X-Request-ID.
- Tools: OpenTelemetry, Jaeger, AWS X-Ray.
- Trace: DB Call, API Call, External services.
-
Goals: Ensure and trace RCA, SLAs
7.3. Handle Failure
-
Retries: wait 1s -> 2s -> 4s while retries, set max attempts.
-
Circuit Breakers: Do not to route the traffic to failed services, isolate the failure.
-
Backpressure: slowing down the requests
- Using message queues.
- Return HTTP Status code 429
- Leaky Bucket, sliding window, queue threshold.
- Load shedding: dropping non-critical traffic
7.4. Reliability: SLOs, SLIs, and Error Budgets
-
SLO: Service level objectives = SLI + Error Budgets
-
SLI: measurements of the system
- % of successful requests.
- % of requests under 200ms.
- Number of requests per second.
- % of failed API calls.
- % of data not lost.
-
SLO: reliability goals with the skateholders in a period of time.
-
Error budgets: allowable amount of failures in given periods.
7.5. Diagram to codebase
-
Translate the architecture to maintainable code.
-
Enforcing Boundaries: Modular Monorepos, ADRs, ArchUnit
- Modular Monorepos: Multi modules as services in the same repo, can be deployed independently.
- ADR: short document about how the architecture decisions has made.
- ArchUnit: Use to write test about the dependencies of a module.
-
Validation: Static validation (structure code), runtime validation, dependency validation, infrastructure conformance.
8. Design Performance
8.1. Caching
-
Client-side caching: Using HTTP Cache-control, Cache static resources e.g. image, scripts.
-
Edge Caching: APIs with GET cachable responses or static content in CDN.
-
Application/Database caching: Redis, memcache, frequently queried data.
8.2. CDN
-
Reduce latency by serveing content from closest geographically servers.
-
Prevent DDoS attack.
8.3. Async Processing
-
Email/SMS.
-
Data transformation.
-
Video/Image Processing.
-
Background analytics.
-
Using graceful fallbacks: to make sure handle all requests
8.4. Frontend Performance
-
Minimize critical rendering path: load critical resources first, lazy load for images and non-critical content.
-
Bundle optimization: tree-shaking unused JavaScript, code-splitting with tools like Webpack or Vite, compress assets using Gzip.
-
Image Optimization: Serve webp format, compress images, using responsive image techniques (dynamic load images by devices, srcset, picture)
-
Reduce HTTP requests: combile css/js files where appropriate, cache assets with proper headers.
-
Leverage browser caching and CDNs
-
Monitor and Analyze: Google Lighthouse, Sentry, monitor FCP, TTI, LCP.
8.5. Backend Performance
-
Optimize algorithms and logic: reduce loops and data structures, avoid blocking in async environments.
-
Reduce network overhead: compress API responses, pagination, avoid over-fetching using GraphQL (only fetch the necessary fields).
-
Connection Polling: manage HTTP and DB connection with pools, adjust thread pool size based on system capacity.
-
Async & Parallel processing: using non-blocking I/O, offload heavy tasks to queue and worker threads.
-
Memory & CPU Profilling: Prometheus, spot memory leaks, bottlenecks, CPU-hogging routines.
-
Caching responses: using memcached, redis, return HTTP code 304, HTTP not modified redirection.
8.6. Database Performance
-
Indexing: use index after where, join, order by,… Use composite indexes when approriate.
-
Query optimization: Use EXPLAIN or EXPLAIN ANALYZE to profile query, avoid N + 1 query problems in ORM (fix by join), replace subquery with join if faster => Optimize to from N + 1 query to 2 query (join + select)
-
Connection Management: Using max connection pool, using read replicas for scaling reads.
-
Sharding & Partitioning: Split large tables to smaller units, ditrbute write load across shards.
-
Materialized Views & Denormalization: Precompute complex joins or aggregations to a virtual table (use view to provide security / restricted access, hide certain columns or rows), view stores real-time data, material views stores stale data, eventual consistency.
-
Ccaching in Redis or memcached, using write-through or cache-aside patterns
-
Monitor: MySQL slow query log, pg_stat_statements, alert for high CPU, table scans.
8.9. Build PaSS product
-
Frontend: Bundle size was 3MB, after optimization => reduced 1MB using code-splitting and lazy load.
-
Backend: Response time droped from 1.2s -> 200ms using caching user profile and optimize database queries.
-
Database: Replace subquery with JOIN, add indexes => droped query time from 500ms to 50ms.
-
Monitoring/Benchmark to profilling metrics:
- Latency (P50, P95, P99 => 99% of requests under the latency threshold, 1% can be higher)
- Throughput (reqs/s)
- Resource ultilization: CPU, memory, disk I/O.
- Startup time: services.
- Netowkr round-trip time: RTT
- Testing: load test - test the performance in a scenario, stress test - test the maximum breaking points.
- RabbitMQ: allow to configure messages with routing key “error” go only to error_queue, fanout to many queues,… Kafka can do it but can not built-in function.
- RabbitMQ: low latency, Kafka: high-throughput.
9. Design with AI
-
Predictive scaling.
-
Proactive learning from logs.
10. Technical Choice:
-
Frontend: React + Next.js SPA.
-
Backend: Golang.
-
Auth: OAuth2 with multi-tenant token scopes.
-
Database: PostgresSQL.
-
Cache: Redis.
-
Queue: RabbitMQ, Kafka.
-
Infras: Deploy using Kubernetes + Helm, GitOp.
-
Observability: Grafana, Loki, Prometheus.
-
Payment Integration: Stripe.
-
Search: Elastic Search.
-
Encryption: TLS, Data encrypted, Rate limiting.
-
Data Layer: Event Sourcing.
-
Fraud Detection: AI service.
=> Each service you can declare the other techstack.
11. How a software architect do
-
Balance authority and enablement: document the changes, reasonale.
-
Balance innovation with delivery: Take innovations and manage risks, write POC with time-box.
-
Work with teams: Agile daily meeting, very details about making decisions.