
Overall - Product System Design - Hello Interview
Here is some note for product system design.
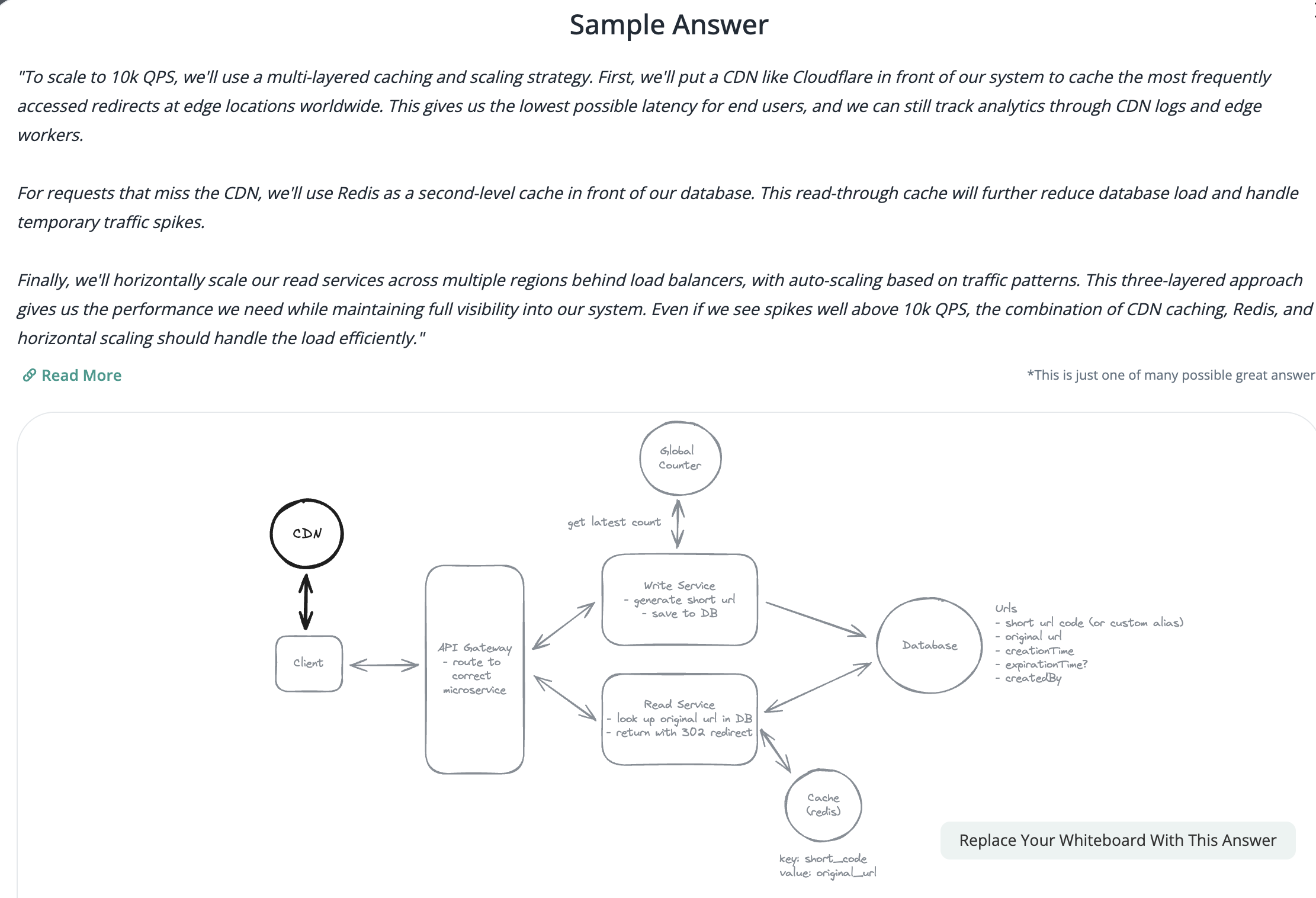
1. Bit-ly
-
Applying CQRS seperate read-write pattern.
-
Using auto increment Redis + base62 [A-Z] [a-z] [0-9] hasing pattern.
-
Centralize the distributed Redis Counter -> Make sure the url-id is unique across multiple instances.
-
To achieve 10M rps, using multiple layer cache: CDN > Redis > Horizontal Scaling (Stateless).
-
Algorithm of Hashing
- Hex: [0–9] [a–f]
- Base64: [A–Z] [a–z] [0–9] [+ /]
2. Dropbox File System
2.1. Upload File
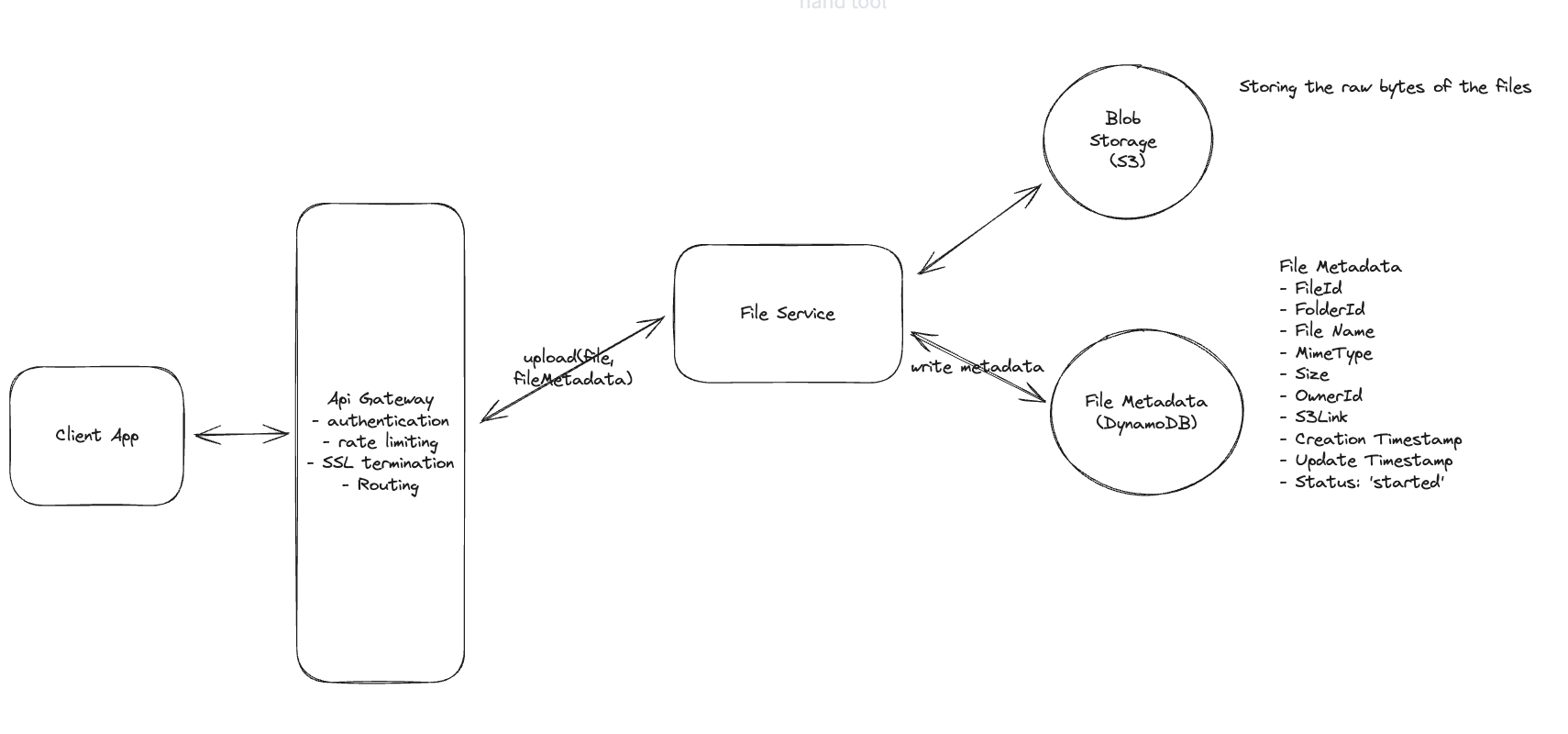
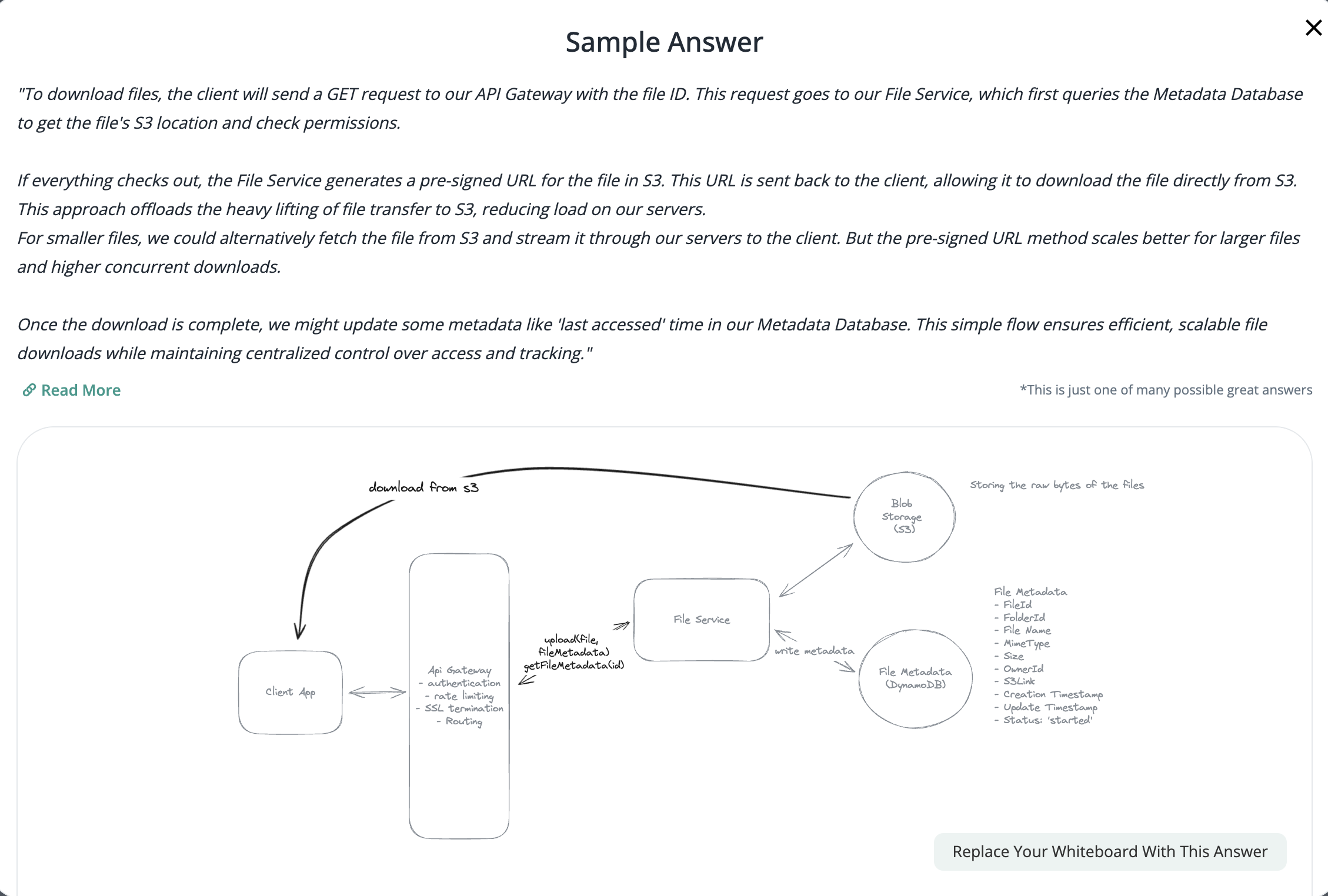
2.2. Download File
- Pre-signed URL: We need pre-signed URLs to provide secure, temporary access to private resources in a time-range without exposing credentials or making the resource publicly accessible.
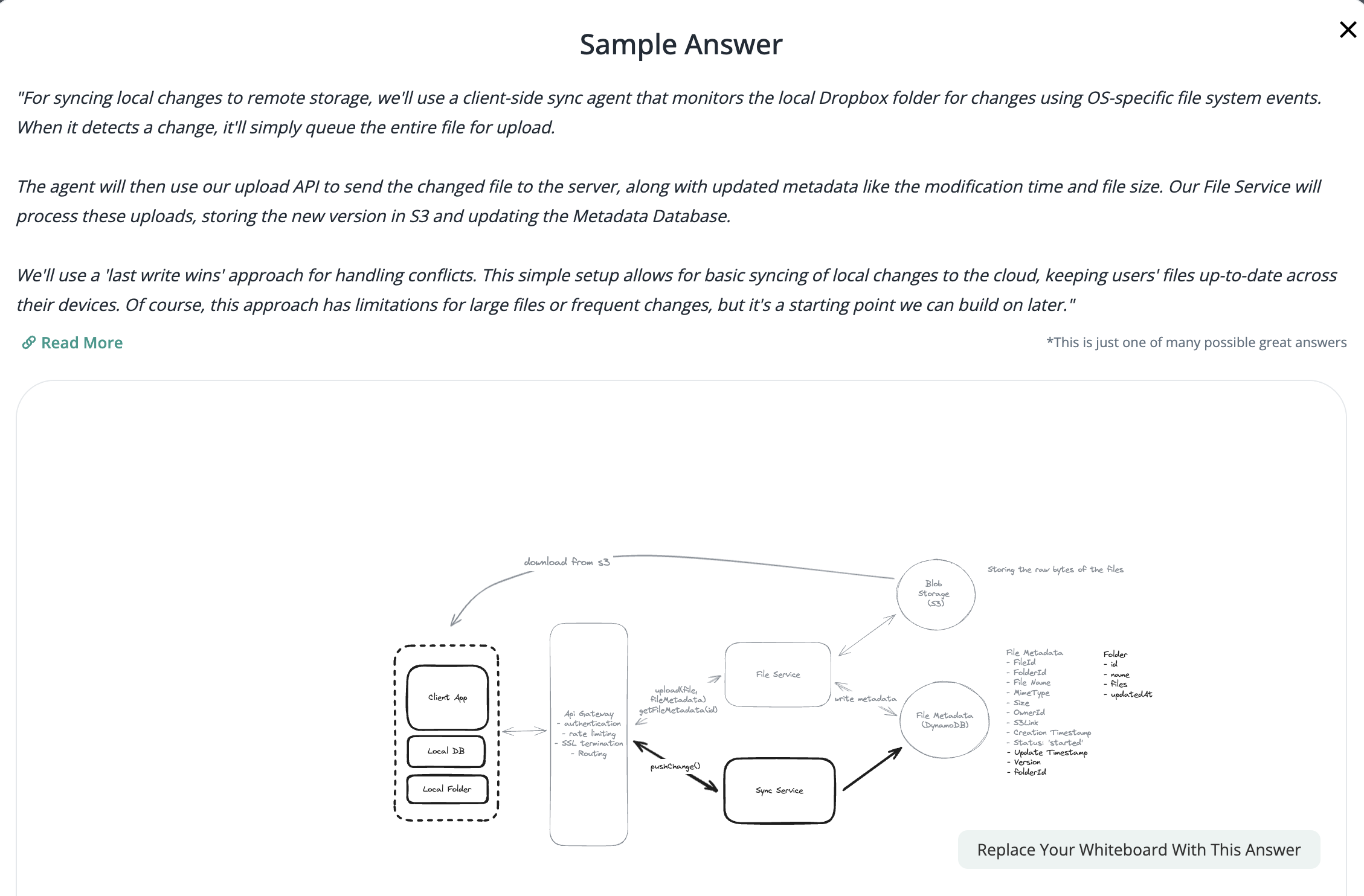
2.3. Sync local file and remote change in cloud
-
Using client-side sync agent + ‘Last write win’ to handle conflicts => sync update metadata to DynamoDB.
-
Using 2 services:
-
File Service: Upload file and create metadata.
-
Sync Service: Listen changes and update metadata.
-
2.4. How will your system handle uploading large files (up to 50GB)
- Upload by each chunk, each chunk has its pre-signed url.
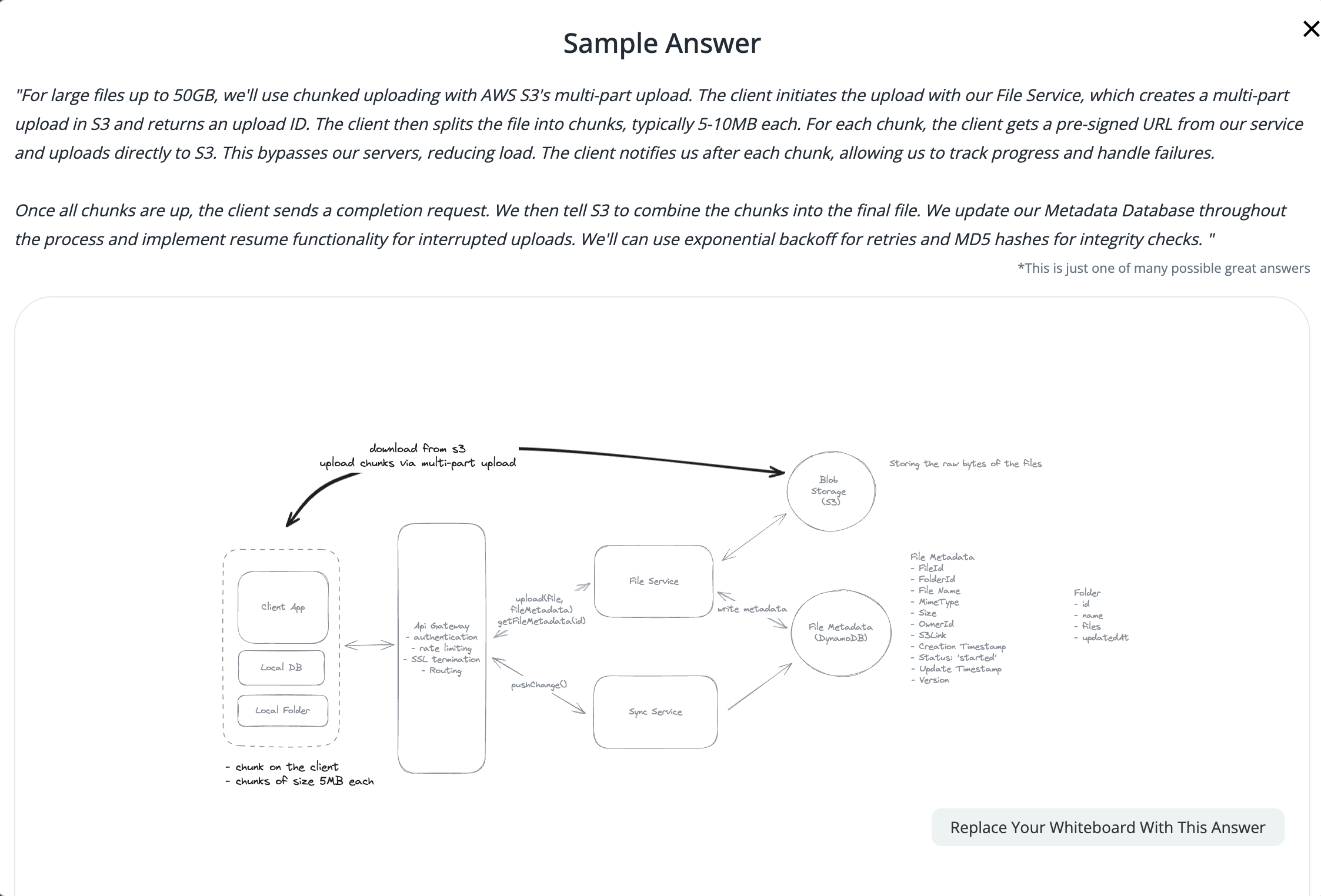
2.5. If you have a network interruptions, how it resume to upload the image but not start from scratch
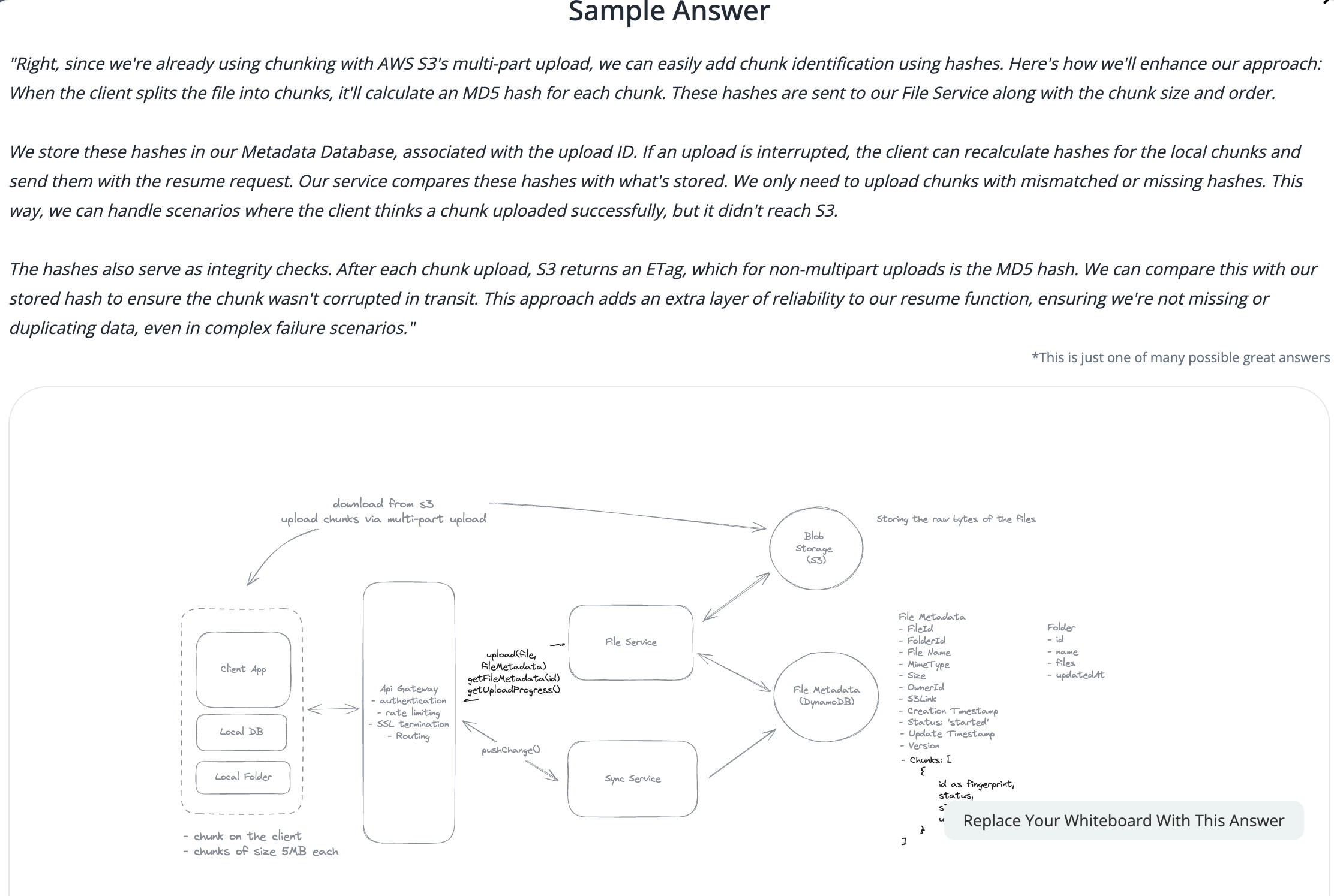
2.6. How to sync file faster by reducing bandwidth
- Only sync the modified chunks, compress images and videos before transfer.
2.7. How can we minimize the time required to detect that a remote file has changed while not overloading the system with getChanges() requests?
- Using Polling Strategy instead of using WebSocket.
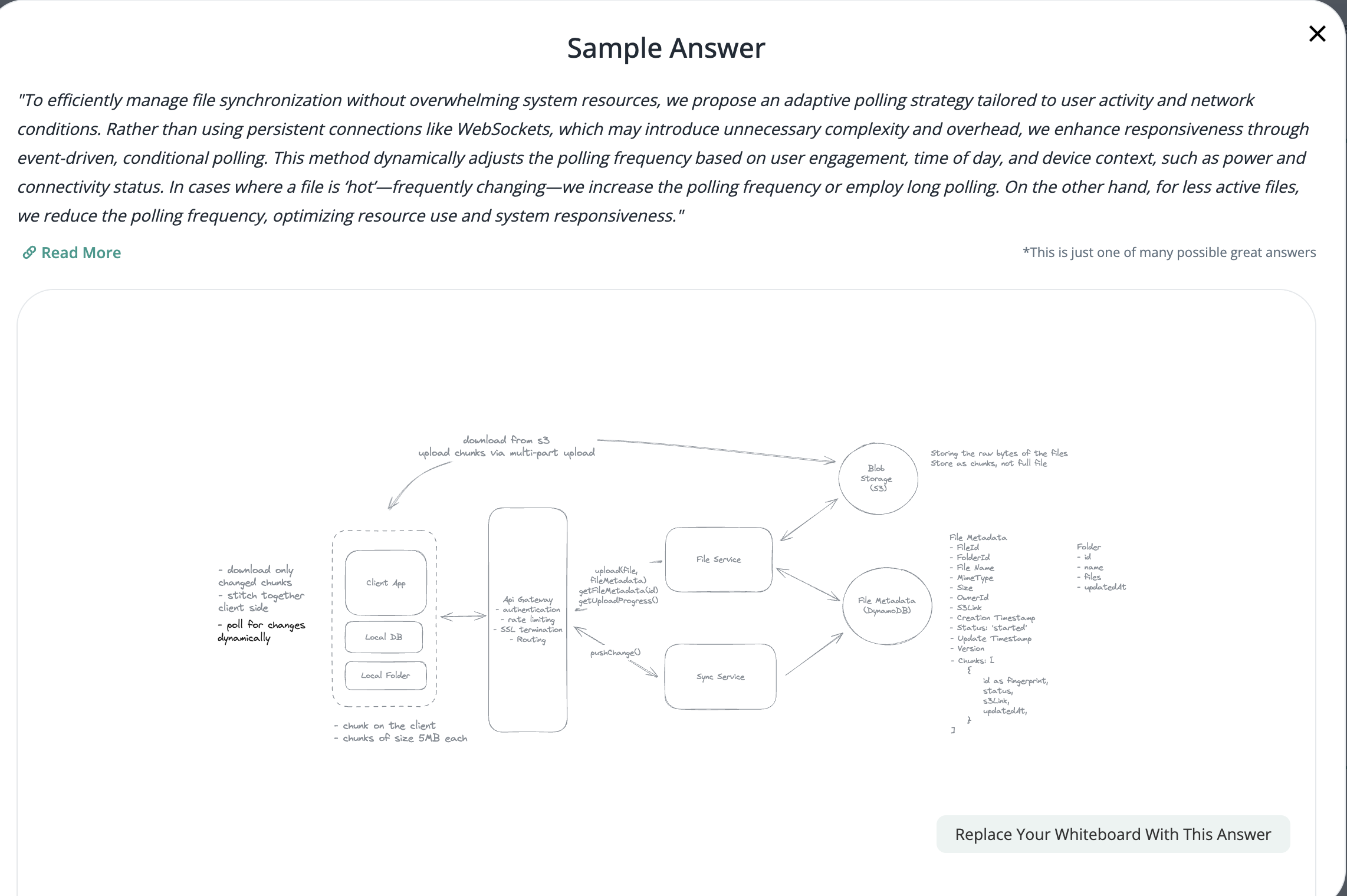
2.8. Notes:
-
Web Server and Browser prevent large file in requests (2GB request limits).
-
In file storage system, we need to prioritize Availability => User can access the file although network condition => Inconsistent Data is acceptable.
-
Compressing only work when: Time Transfer > Time compressing => If the image is already compressing, if you continue to compress it => It is counterproductive.
-
How to content-based file deduplication => Cryptographic fingerprinting (Hashing) => filenames + location.
-
We can use parallel chunking technique.
-
When the file is already upload, S3 trigger events => SQS => Amazon Dynamo DB to update status of the file to Completed.
-
Hybrid client-side for real-time update:
- Web Socket: active file.
- Pooling: in-active file.
-
‘Last Write Win’ improve the eventually consistency.
3. NoSQL Design
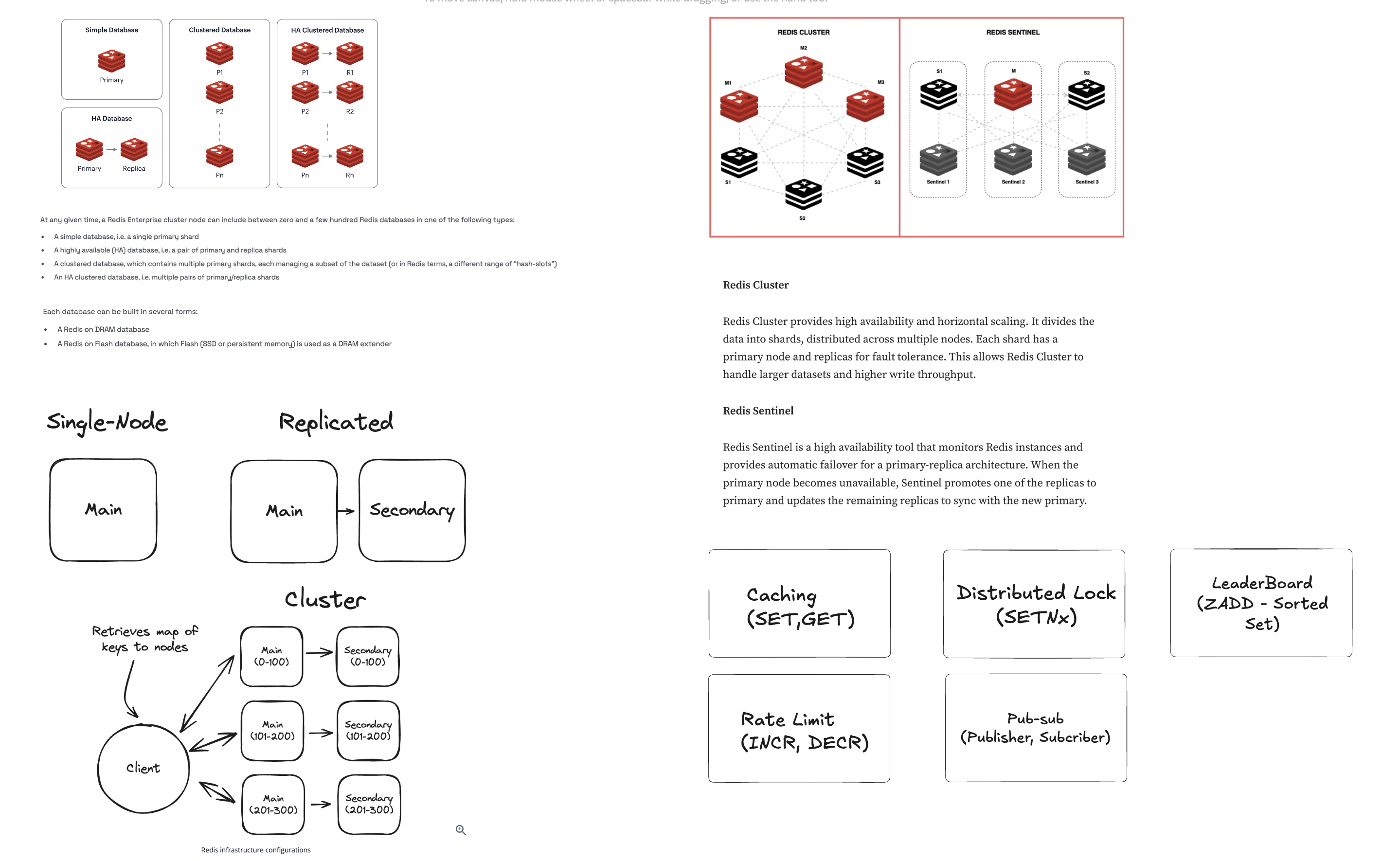
3.1. Redis
3.2. MongoDB
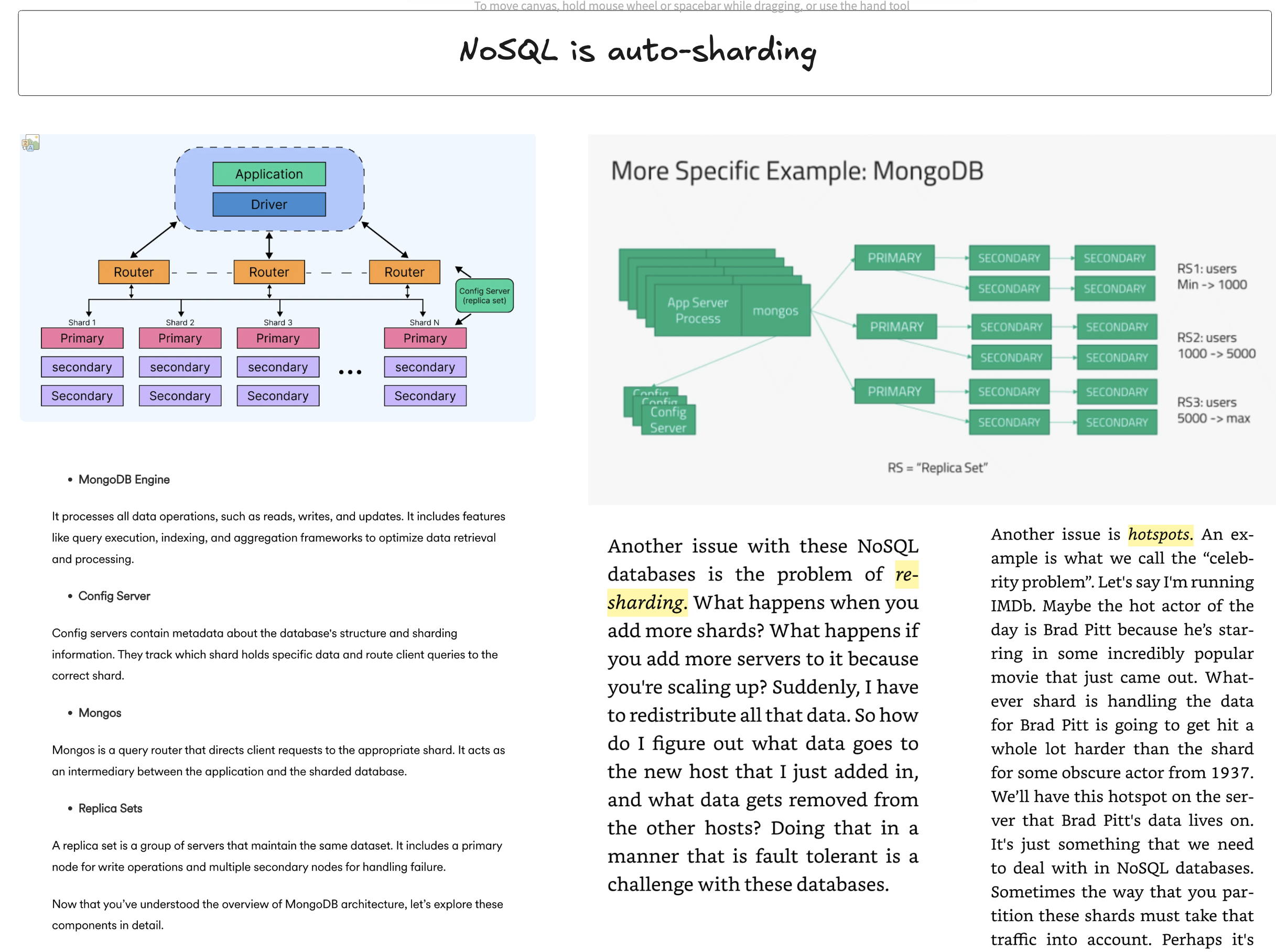
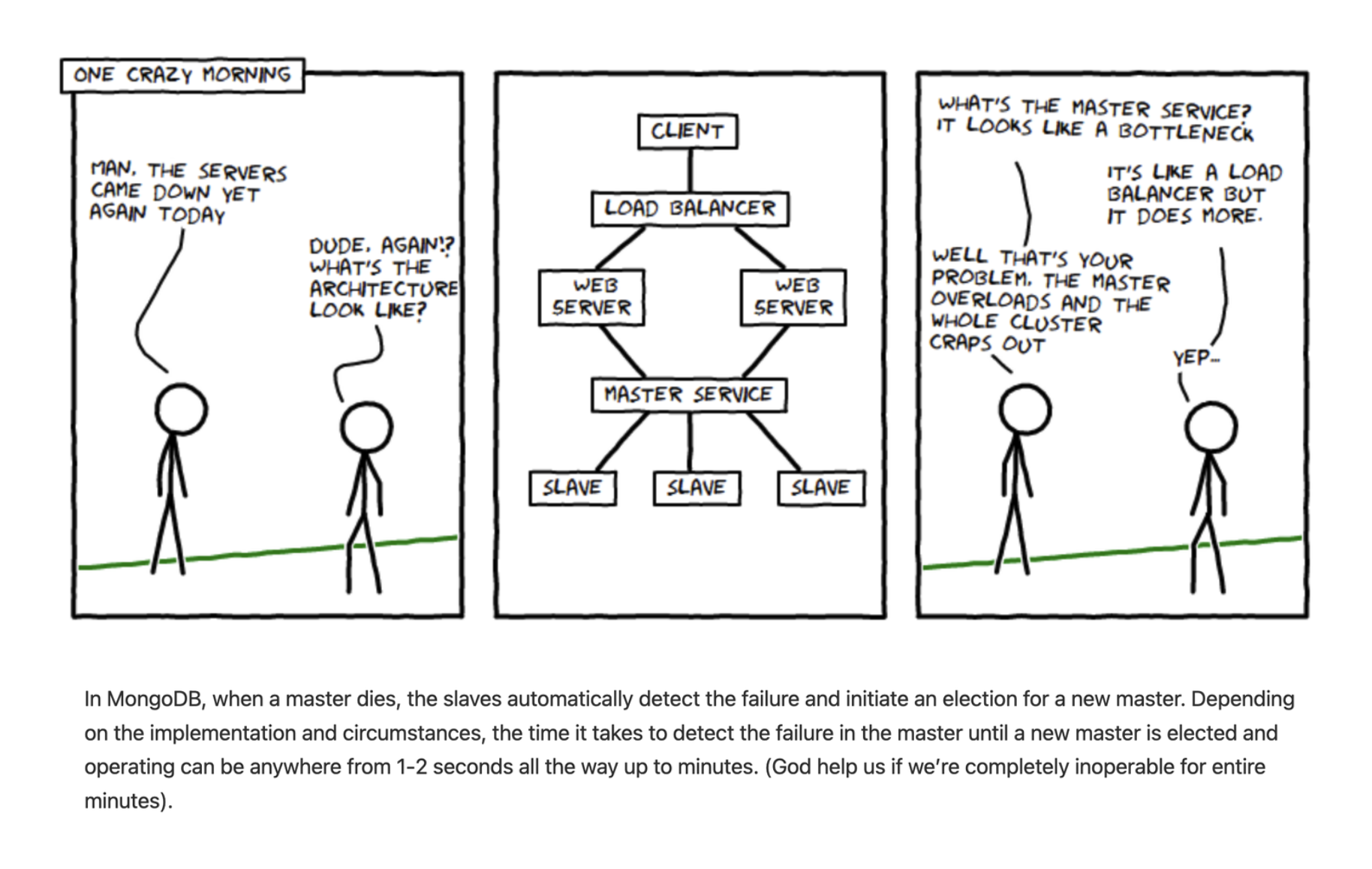
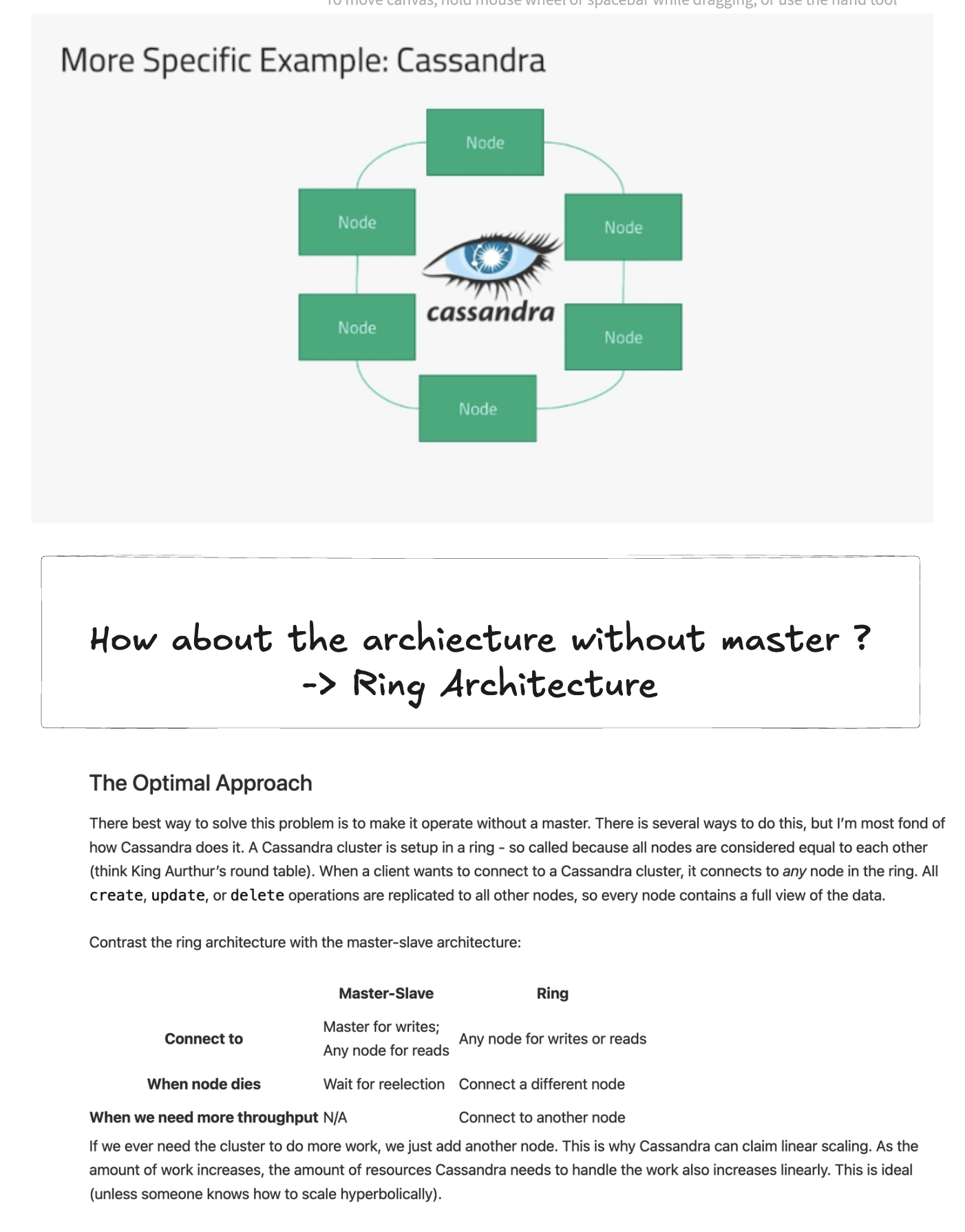
3.3. Cassandra
3.4. DynamoDB

3.5. Lock, concurrency, index, partition DBMS: Redis, MongoDB, Cassandra, DynamoDB, SQL
4. SQL Design
4.1. Lock Database
-
Khi select need to WHERE from ‘index’ => Không là nó scan DB.
-
Khi select * => auto lock bảng => Write vào không được.
When SELECT 1 billions records => What is lock db ?
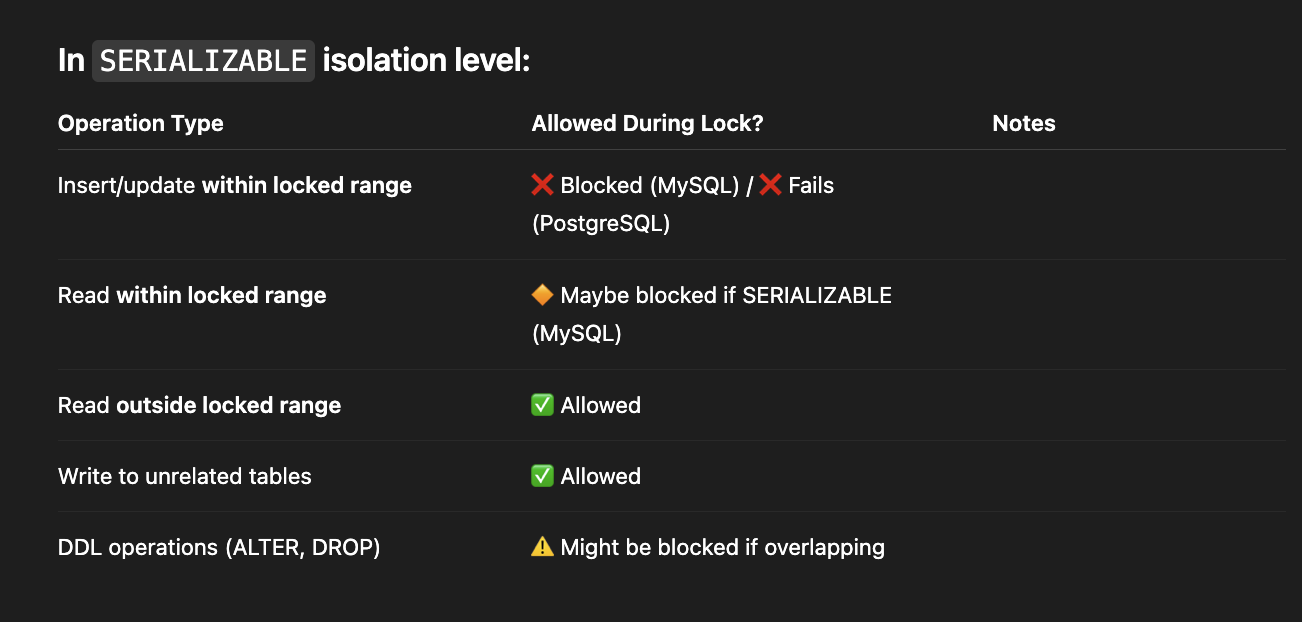
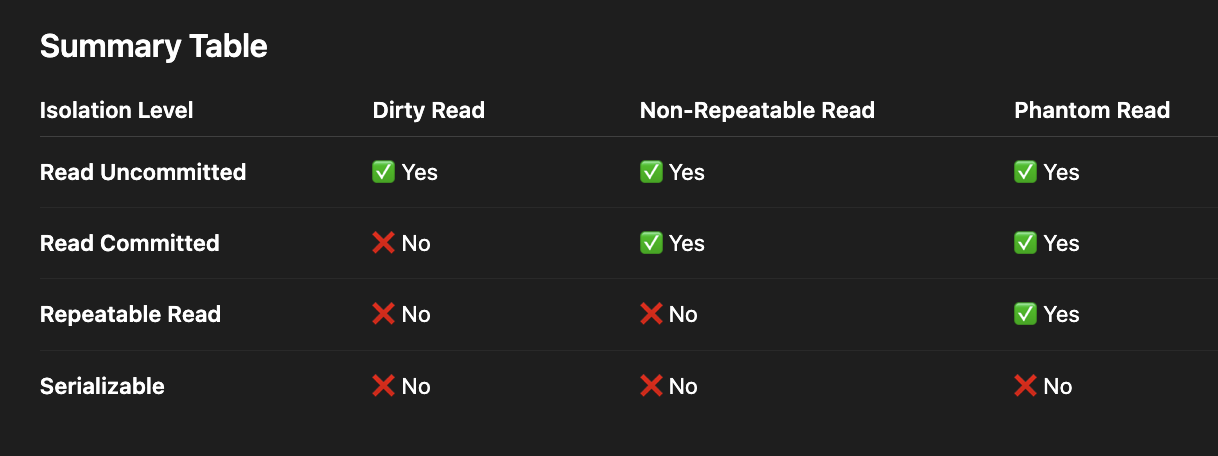
4.2. Isolation Lock happen in ACID
-
In ACID, Isolation Level in ACID
-
3 types of READ:
-
Dirty Read: Read without commit.
-
Non-repeatable Read: In the same trasaction, read the same row 2 times => Return 2 different value because other transaction has commited it.
-
Phanrom Read: Read same time with different numbers of row.
-
-
4 Isolation of Level:
-
Read Uncommited
-
Read Commited.
-
Repeatable Read.
-
Seralizable
-
4.3. Hadoop (File System)
-
Hadoop: Distributed File System from Data Warehouse.
-
Data Warehouse: Using Hive to query Hadoop.
-
Data Lakehouse: versioning, metadata, only has ACID, still distributed => Keep ACID by using distributed patterns: 2-Phrase-Commit, transaction logs, slower than warehouse.
-
DBMS: File System + Query Engine + Metadata.
4.4. Hive:
- Hive: Store metadata for Hadoop (File System)
4.5. Two-phrase commit
- Failed in ISOLATION level.
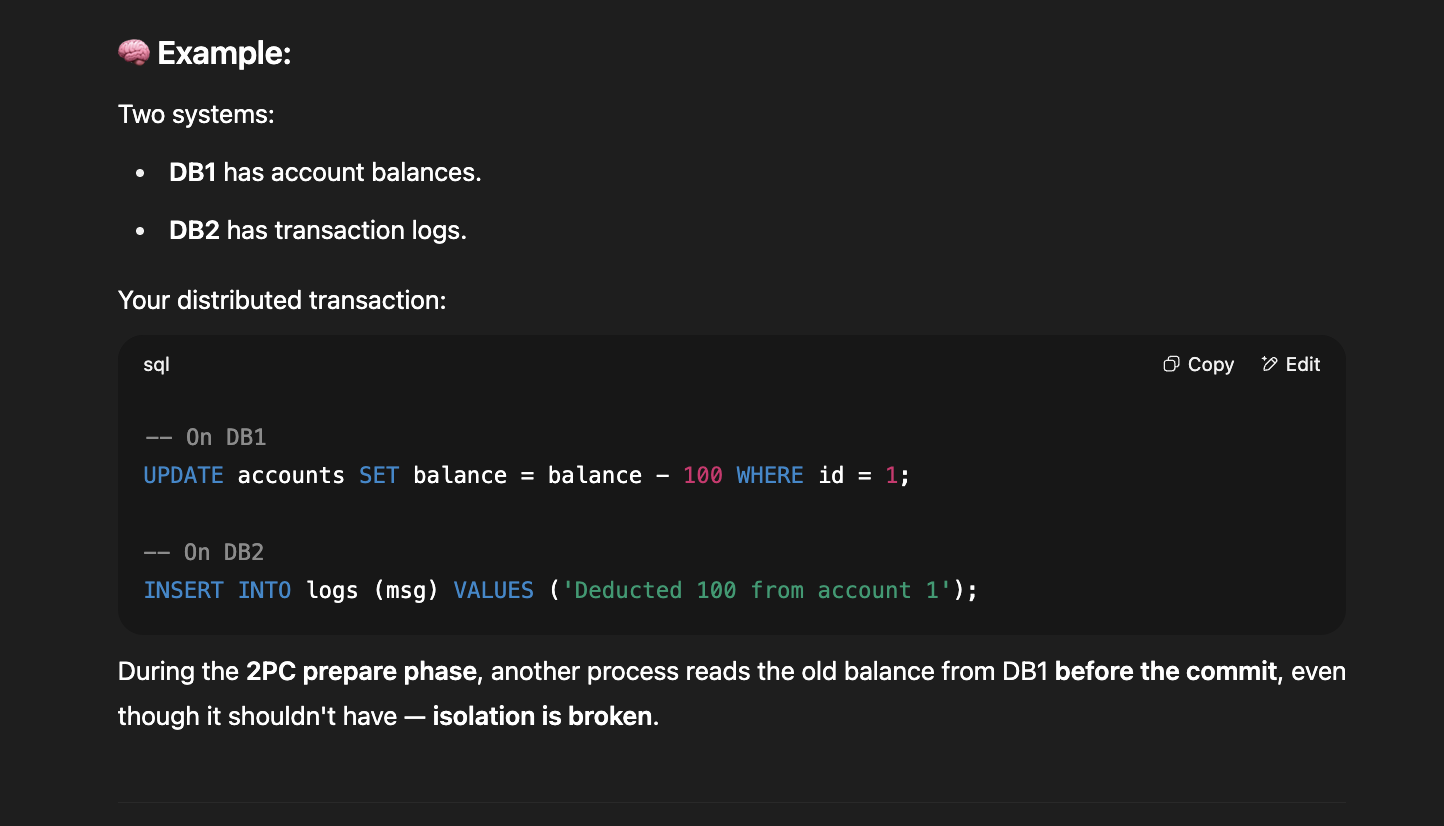
4.6. Airflow
-
Using cronjob to schedule job to query data.
-
CI/CD of data.
4.7. Flink & Spark
-
Compute Engine
-
Spark: batch processing, read batch from Kafka => Count enough records to use.
-
Flink: Read real-time, read data from Kafka => Compute to predict the fraud detection real-time, costly and less to use.
-
Depend on jobs => write a cron job with Spark, Flink => DE write cronjob.
4.8. OLAP
-
Using query engine to read data in data warehouse.
-
PostgreSQL
-
Redshift
-
Lakehouse -> trino
4.9. Superset
-
Superset -> Trino -> Query data in lakehouse (warehouse) -> Red-shift.
-
Warehouse: SQL
-
Lakehouse.
-
Object: metadata -> ETL -> Read from S3 -> Tool make it (abstract from sql -> query data in engine).
-
Data will store in file and partitioning.
-
Everything is a distributed file system -> Partition -> Abstract by sql query in tool.
4.10. Write-Ahead Log
-
A Write-Ahead Log is a sequential log file that records every intended modification to the database before the actual data is written.
-
Use to store history action of DBMS => Use for rollback, migration when change data capture,…
5. Design a Local Delivery Service like Gopuff
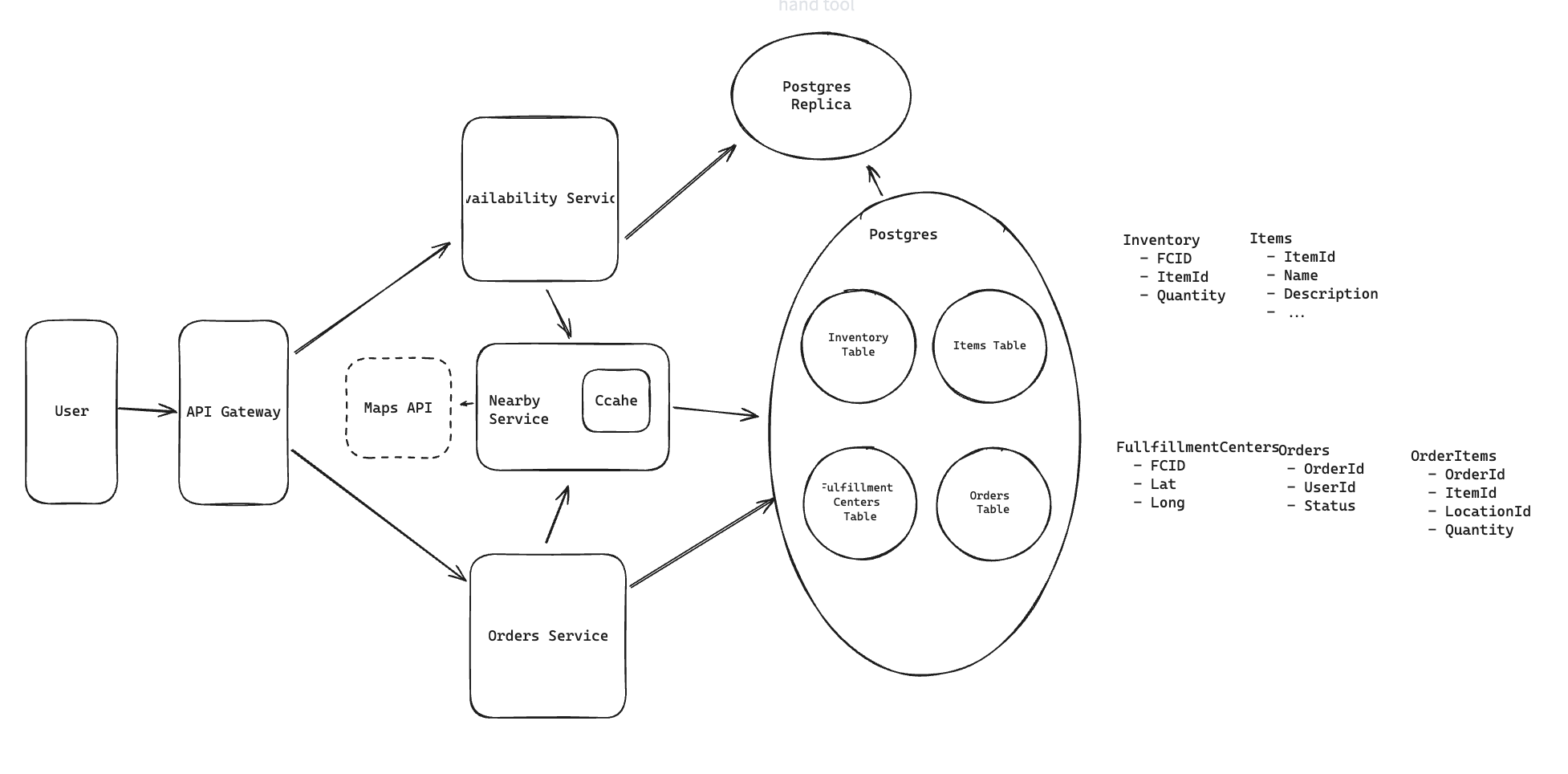
5.1. Entities:

5.2. API Design

5.3. How will customers be able to query the availability of items within a fixed distance (e.g. 30 miles)?
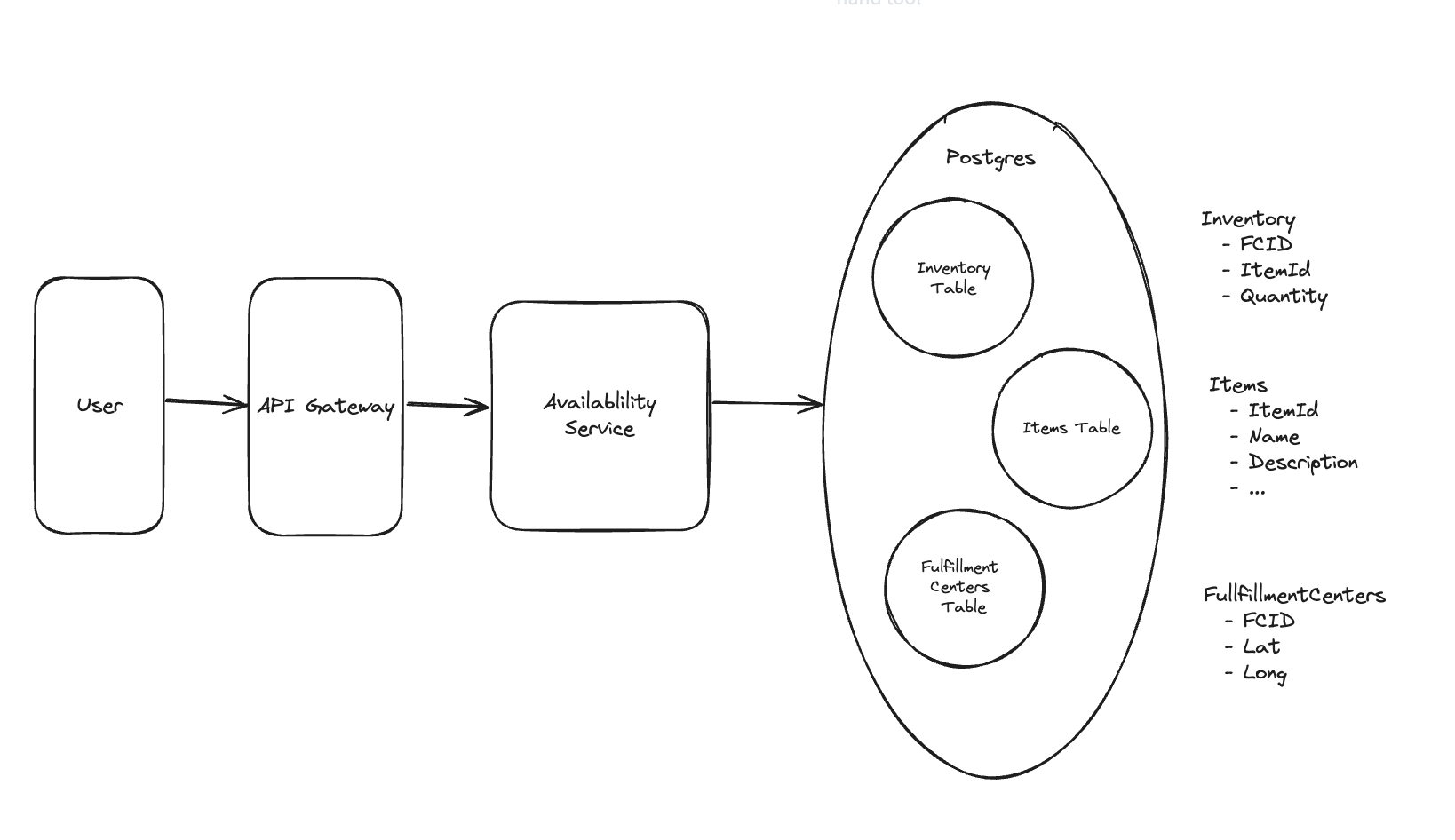
5.4. How can we extend the design so that we only return items which can be delivered within 1 hour?
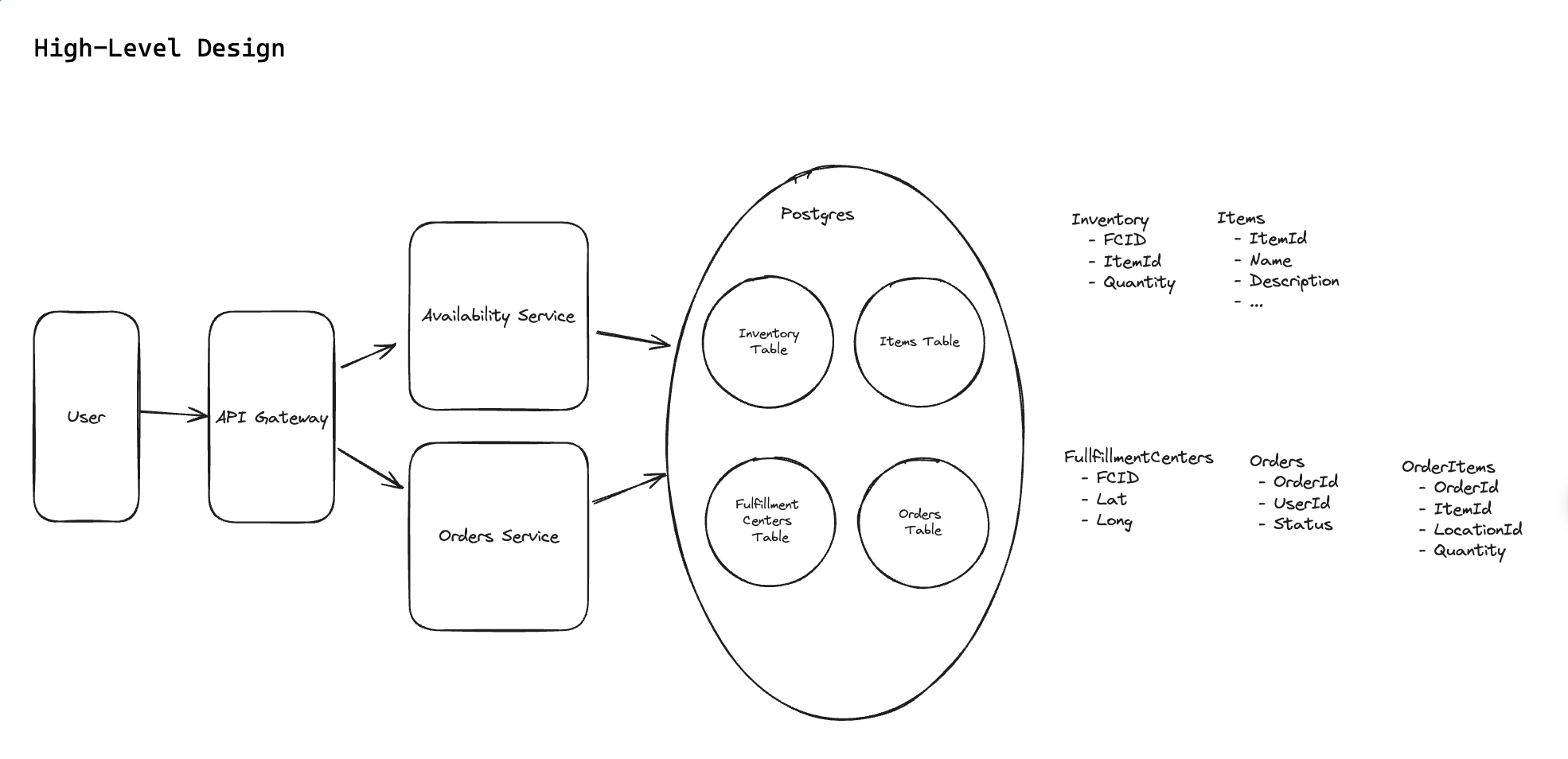
5.5. How can we ensure users cannot order items which are unavailable? How do we avoid race conditions?
“To avoid both race conditions and customers ordering out of stock inventory, we’ll use a transaction on our Postgres database. In this transaction we’ll:
(1) Check the inventory items are still available at the locations we determined when we checked availability. (2) Decrement the inventory counts at those locations. (3) Create a new Order record with the associated items.”
5.6. How can we ensure availability lookups are fast and available?
(1) We can use the prefix of the geohash of a location as the cache key so small changes in the location still hit the same fulfillment centers.
(2) Each nearby service instance can maintain a local cache of the fulfillment centers so that location search can be done without an external call. Since fulfillment centers aren’t changing often, we can make the cache TTL long.
(3) We can replicate our Postgres instance and have the availability service read from replicas. This may mean availability lookups are slightly stale, but we’re ok with this.”
Idea: The location only store data for it, do not scan all table.
5.7. How do delivery systems efficiently aggregate inventory across multiple warehouse locations?
- Sum quantities from nearby warehouses
5.8. Travel time estimation services provide more accurate delivery zones than simple distance calculations
- Travel time services account for real-world factors like traffic, road conditions, and geographic barriers, providing more accurate delivery feasibility than straight-line distance calculations that ignore these constraints.
5.9. Which technique is MOST effective for preventing concurrent resource allocation conflicts?
- Atomic transactions.
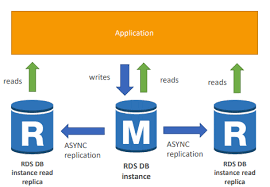
5.10. Implement database read performance
-
Read replica: Use for master slave, write in master, read from slave. But replica can serve stale data.
-
Query Caching.
-
Index.
-
Write-ahead logging: keep track all actions of DBMS, use for migration data.
5.11. Which algorithm accounts for Earth’s curvature when calculating geographic distances?
- The Haversine formula.
5.12. Two-phase filtering
-
Two-phase filtering first applies cheap local filters (like simple distance calculations) to reduce the candidate set before making expensive external API calls (like travel time estimation).
-
Step 1: Pre-computed radius filtering
5.13. Paritition strategy
-
Round-robin distribution
-
Geographic sharding
-
Hash partitioning
-
Timestamp-based splitting
5.14. What happens when cached inventory data becomes stale after concurrent orders?
- Overselling inventory
5.15. Which isolation level BEST prevents phantom reads in concurrent transactions?
-
Two read query -> Call different numbers of rows.
-
Only serializable solve phantom read.
5.16. Eventual consistency and Partition Tolerance
-
Eventual consistency: Parts may show different data briefly, but will match soon.
-
Partition Tolerance: Partition tolerance means a system can work even when some parts can’t talk to each other => Using Data Replication or Local Cache.
5.17. Reduce external service
-
Batch Processing.
-
Result Caching.
-
Local pre-filtering.
6. Design a News Aggregator (Example dev.to)
6.1. Non-requirements

6.2. Entities

6.3. API Design
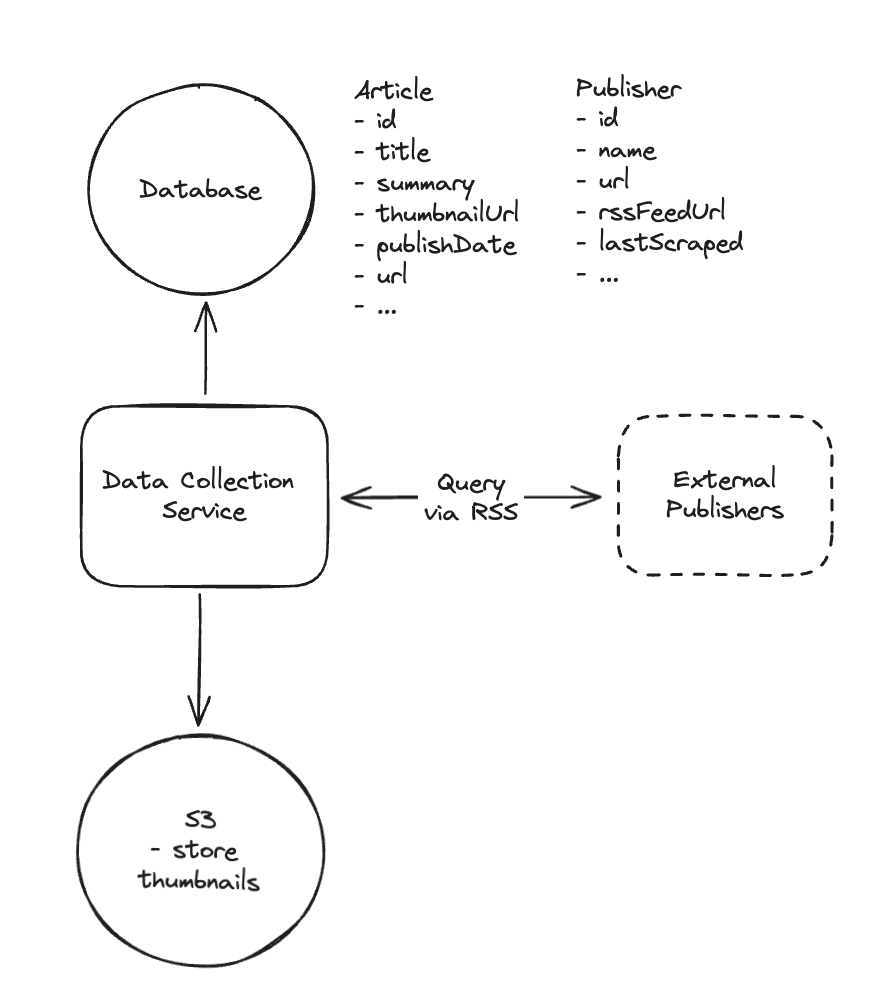
6.4. How will your system collect and store news articles from thousands of publishers worldwide via their RSS feeds?
6.5. How will your system show users a regional feed of news articles?
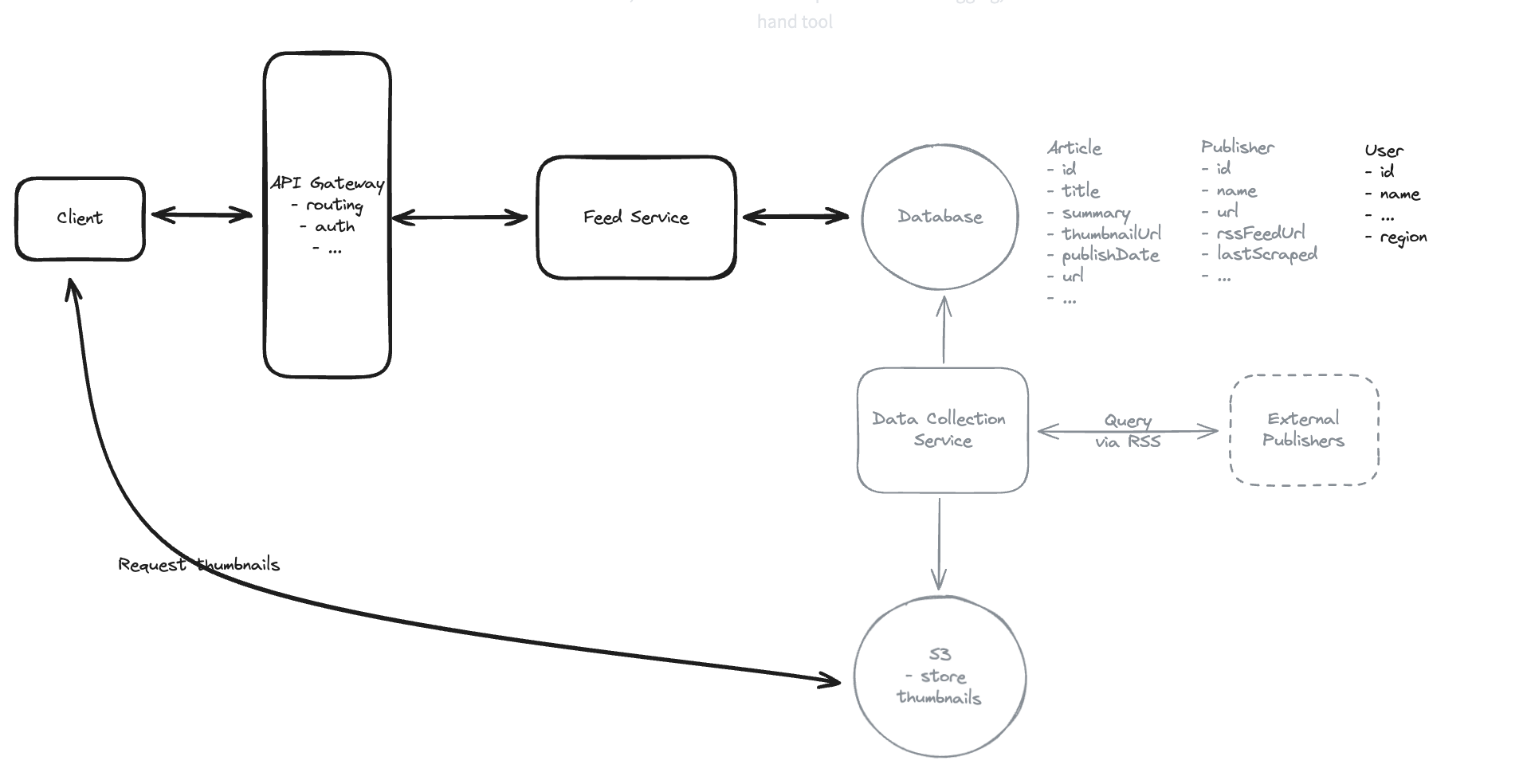
6.6. Scroll through the feed ‘infinitely’?
-
An optimal solution could use monotonically increasing article IDs (like ULIDs) as cursors, eliminating timestamp collisions entirely.
-
This makes pagination incredibly simple: we just query for articles with IDs less than the cursor value => Scroll from the highest ID to the lowest one. We just store the last article we saw client side as the cursor and pass it along with each API request.
6.7. How do you ensure that users feeds load quickly (< 200ms)?
-
Using CDC (Change Data Capture) from database to Redis.
-
Update pre-computed value to Redis, using ZREVRANGE, maintain only the most recent 1,000-2,000 articles per region.
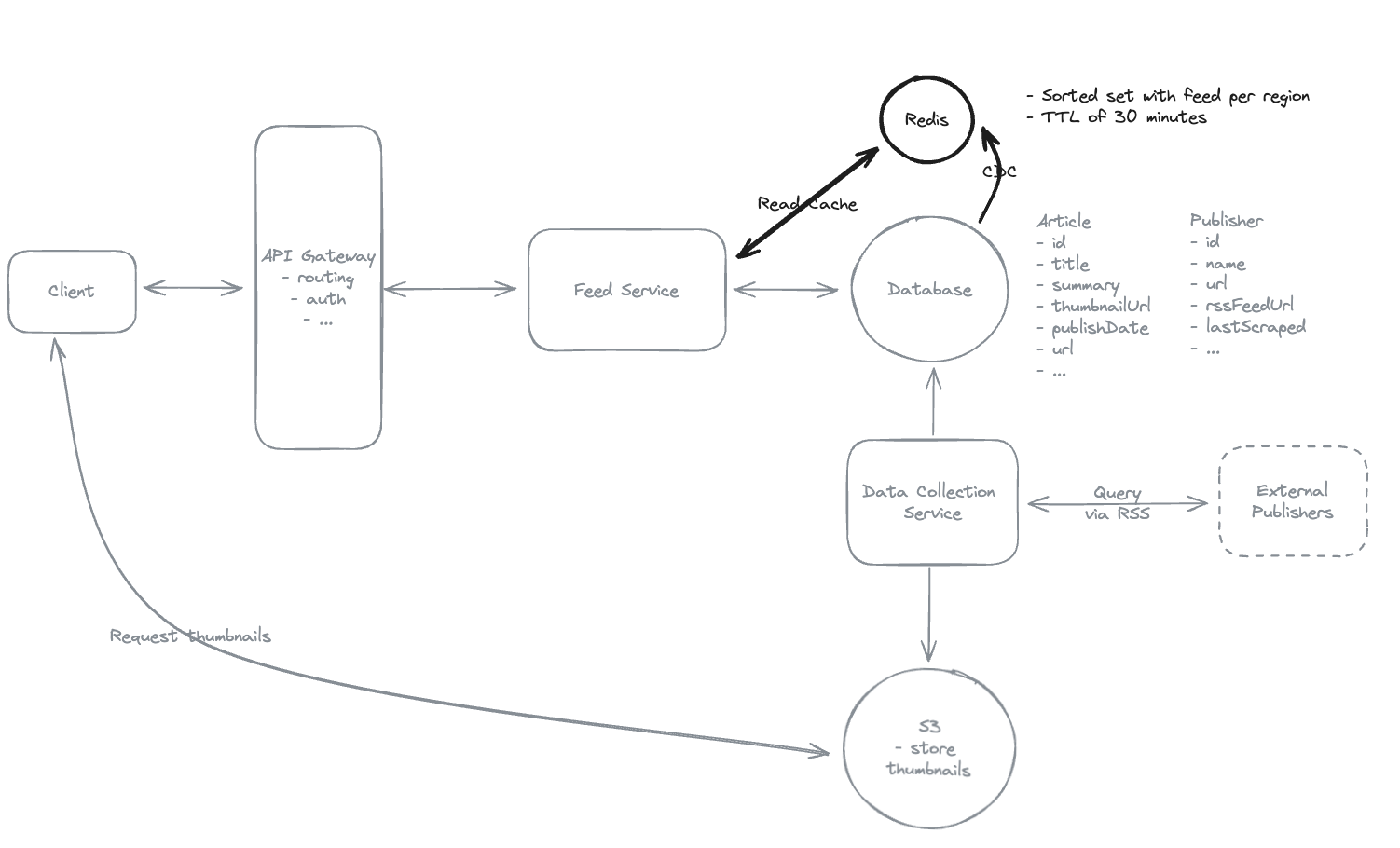
6.8. How do we ensure articles appear in feeds within 30 minutes of publication? Even for publishers that don’t have RSS feeds.
-
Integrate with Webhook of platforms.
-
Using 3 methods: frequent RSS polling, Web Scraper, Webhook.
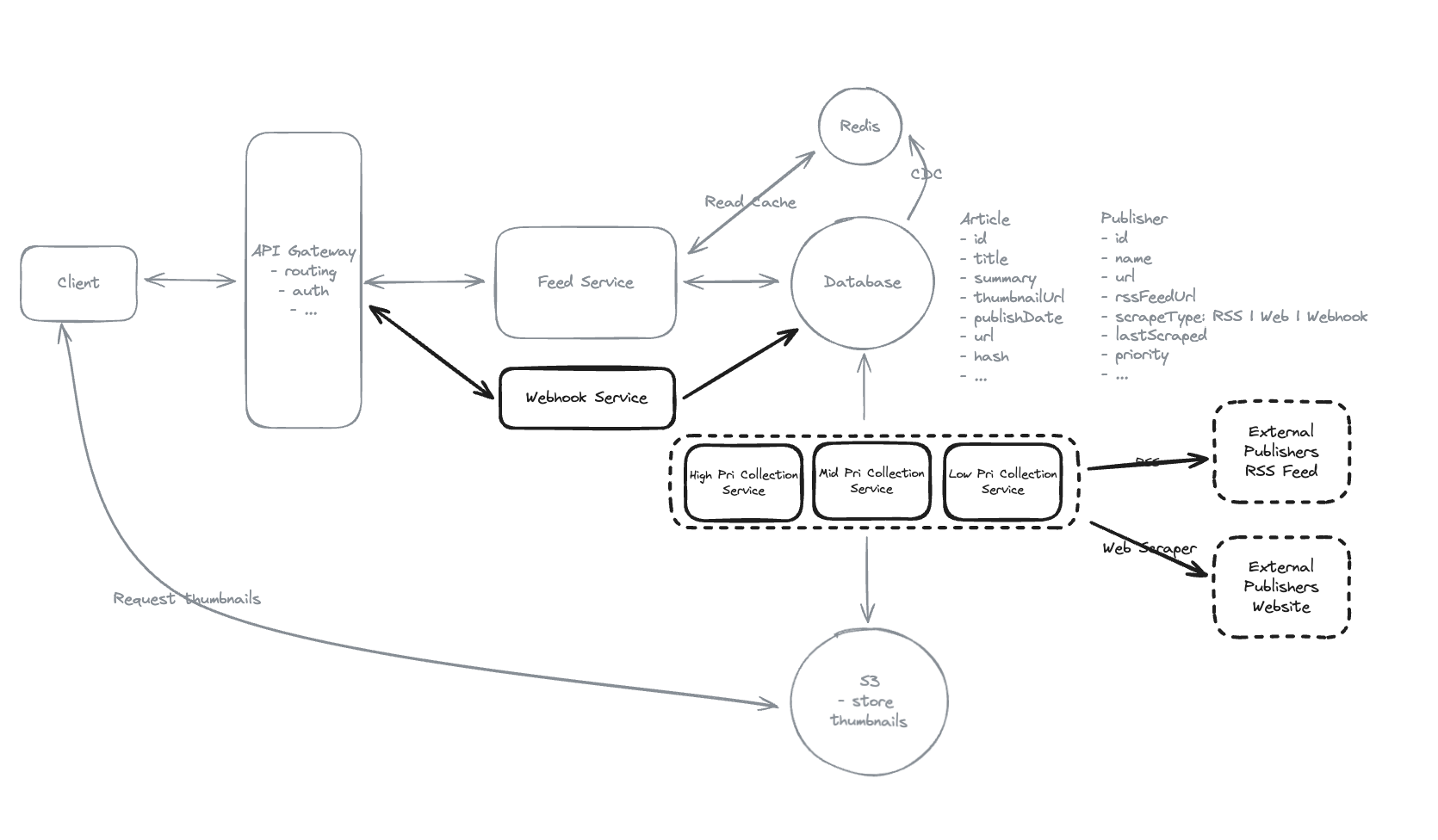
6.9. How do you efficiently deliver thumbnail images for millions of news articles in user feeds?
- Using thumbnail in region of the client-side.
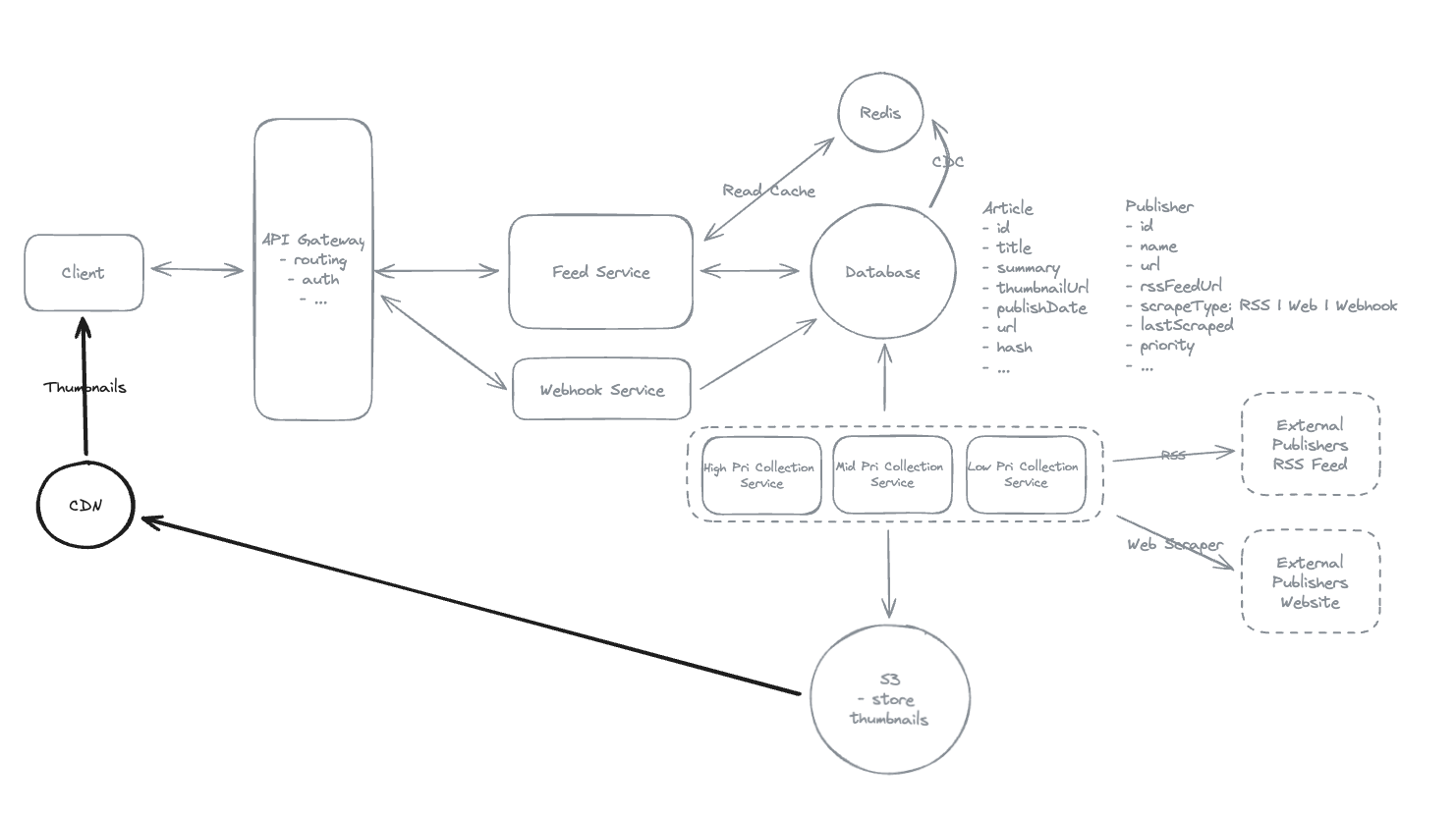
6.10. How do you scale your cache infrastructure to handle 10M concurrent users requesting feeds?
- With 10M concurrent users requesting feeds, a single cache instance can only handle ~100k requests per second, creating a massive bottleneck
=> Scale the redis, each instance 100k rps -> 100 instance can handle 10M rps.
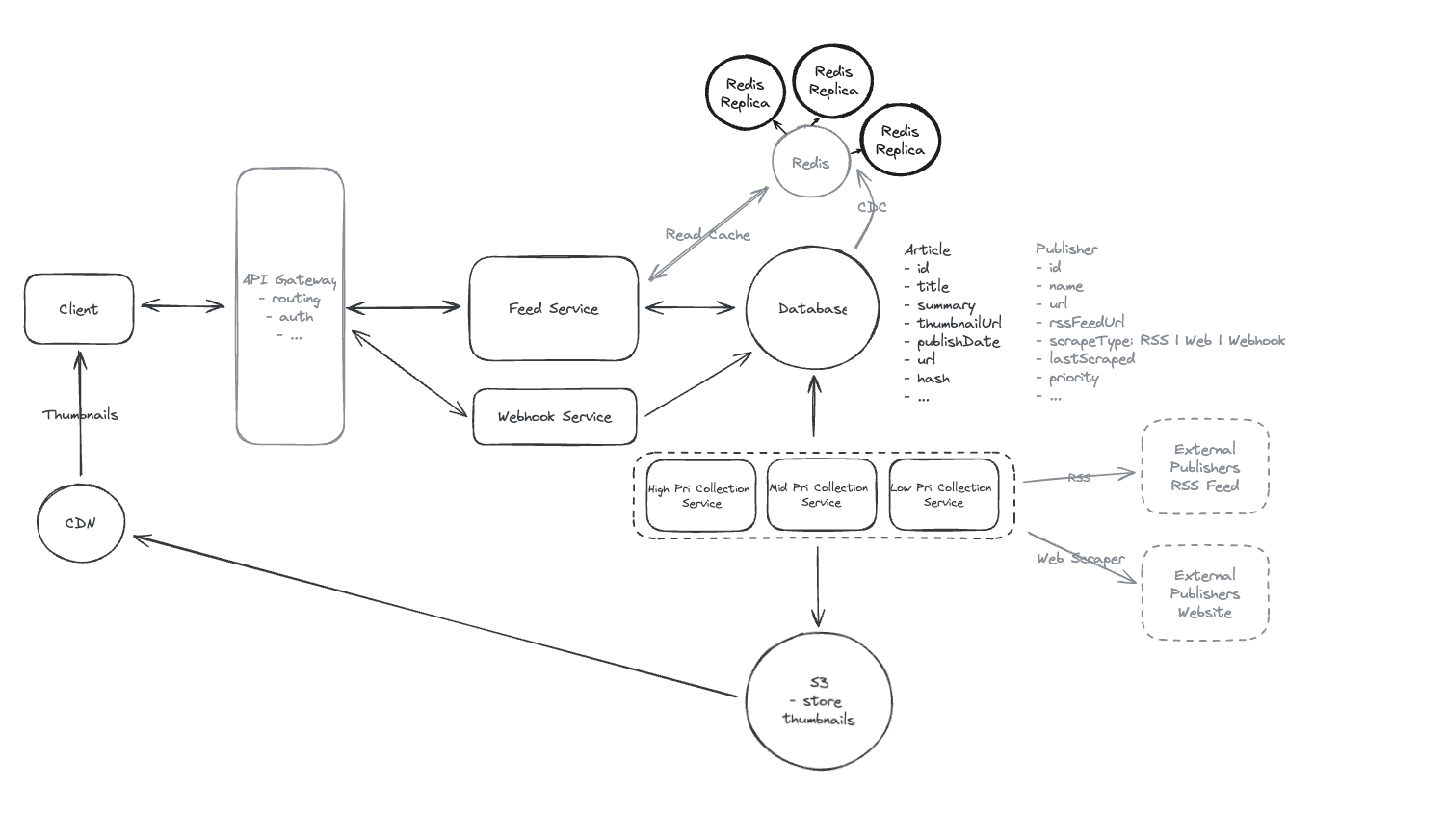
6.11. Why do news aggregators like Google News download and store their own copies of publisher thumbnails rather than linking directly to publisher images?
- Publisher images can be slow to load, change URLs, or become unavailable, which would break the feed experience => Storing local copies ensures consistent load and latency.
6.12. Cursor-based pagination & Offset-page Approach
-
Cursor-based pagination -> decrease down ID from the cursor.
-
Offset page -> Rerender when publishers have new data.
6.13. Why might implementing webhooks from publishers be preferred over frequent RSS polling for breaking news delivery?
- Webhooks provide immediate notification when content is published, reducing discovery latency from minutes to seconds.
6.14. When implementing personalized news feeds, why might ‘pre-computed user caches’ be worse than ‘dynamic feed assembly’ despite being faster?
- Pre-computed user caches require enormous additional memory and introduce complex cache invalidation logic
6.15. Why do news aggregators implement Change Data Capture (CDC) instead of simple database polling for cache updates?
-
CDC triggers cache updates immediately when new articles are inserted, providing sub-second freshness.
-
Pooling require a high database load.
6.16. During a major election, your Redis cache serving 100M users gets overwhelmed at 100k requests/second. What’s the BEST immediate scaling solution?
- Add read replicas.
6.17. A system’s database must serve 100,000 read requests per second. Which scaling approach handles this load most effectively?
- Implement read replicas.
6.18. A news publisher’s RSS feed is down for 2 hours during breaking news. What’s the BEST fallback strategy?
-
Context: 1 publisher source is lost => What do you do ?
-
Solution: Using Web Scraping technique if the RSS feeds is failed.
6.19. What happens when cached data becomes stale in high-frequency update systems?
- Users see outdated information
6.20. All of the following improve content freshness
-
Real-time webhooks
-
Frequent polling
-
Change data capture
6.21. Geographic data distribution reduces latency by serving content from nearby locations.
- Yes
6.22. During traffic spikes, which component typically becomes the bottleneck in read-heavy systems?
-
In read-heavy systems, the database or cache layer typically becomes the bottleneck first -> Data retrieval operations.
-
About server: it is basic routing, and load balacers can usually be scaled easily than data layer.
6.24. Eventual consistency is acceptable for news feeds where availability matters more than perfect synchronization.
-
According to the CAP theorem, news aggregation systems often prioritize availability over strict consistency.
-
Users prefer access to slightly outdated content rather than no content at all.
6.25. When implementing category-based news feeds (Sports, Politics, Tech), which approach provides the best balance of performance and resource efficiency?
-
Cache metadata in regional caches (like feed:US) => Filtering from this key.
-
Pros: This avoids the memory explosion of separate category caches (25 categories × 10 regions = 250 cache keys) => Reading 1,000 articles from Redis takes ~10ms, and in-memory filtering adds only 1-2ms.
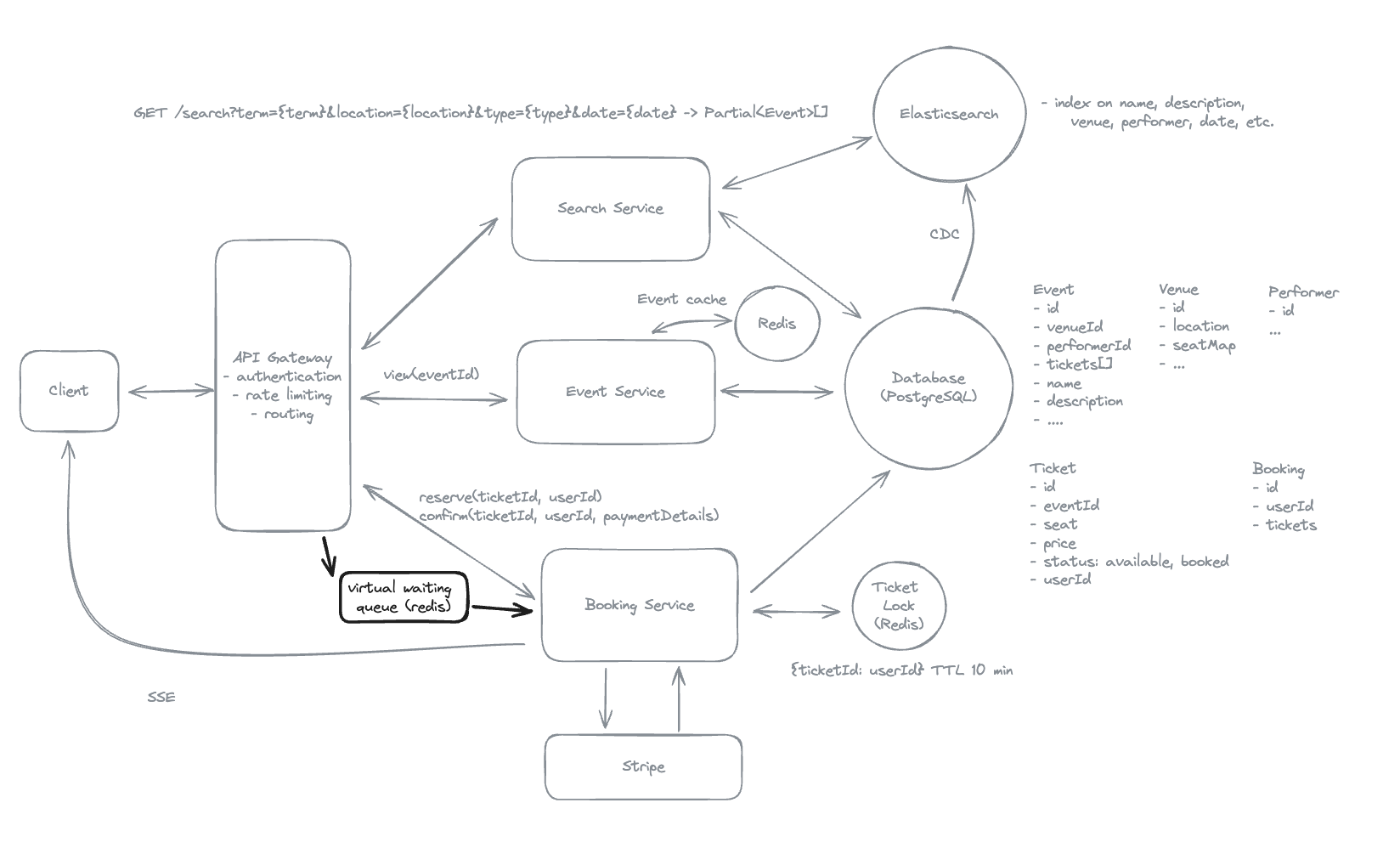
7. Design Ticketmaster
7.1. Non-functional requirements
-
Consistency for booking events.
-
Availability for searching events.
-
Scalability for handle popular events.
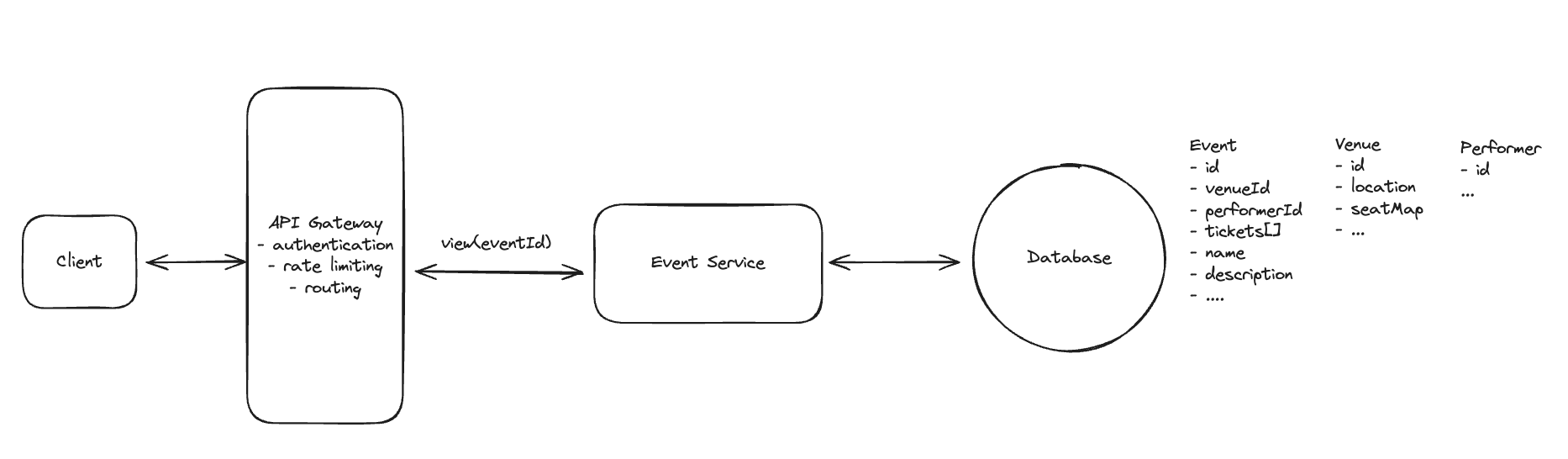
7.2. Entities

7.3. API Design

7.4. How will users be able to view simple event details when clicking on an event? ie. name, description, location, date, etc.
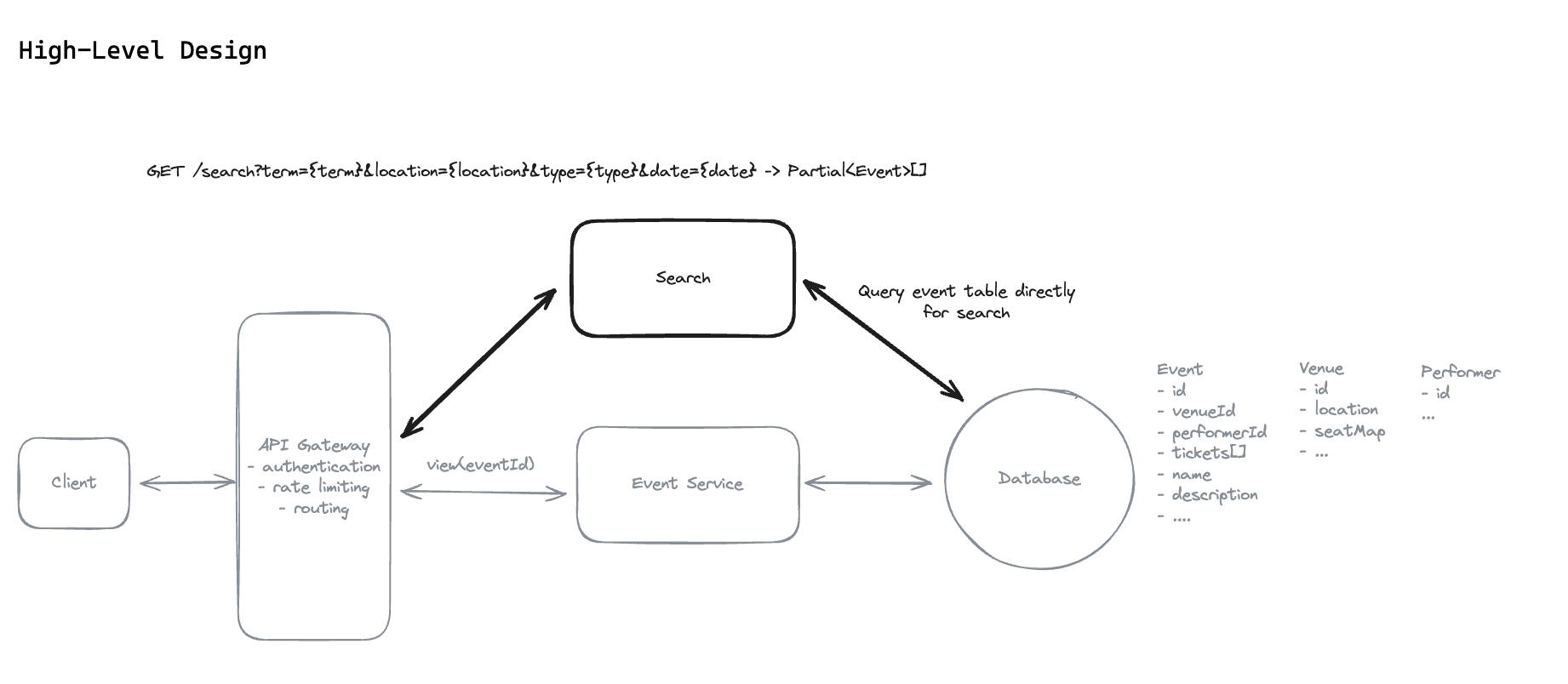
7.5. How will users be able to search for events?
7.6. How will users be able to book specific seats for events? Each physical seat has exactly one ticket. Do not consider General Admission or section-based booking.
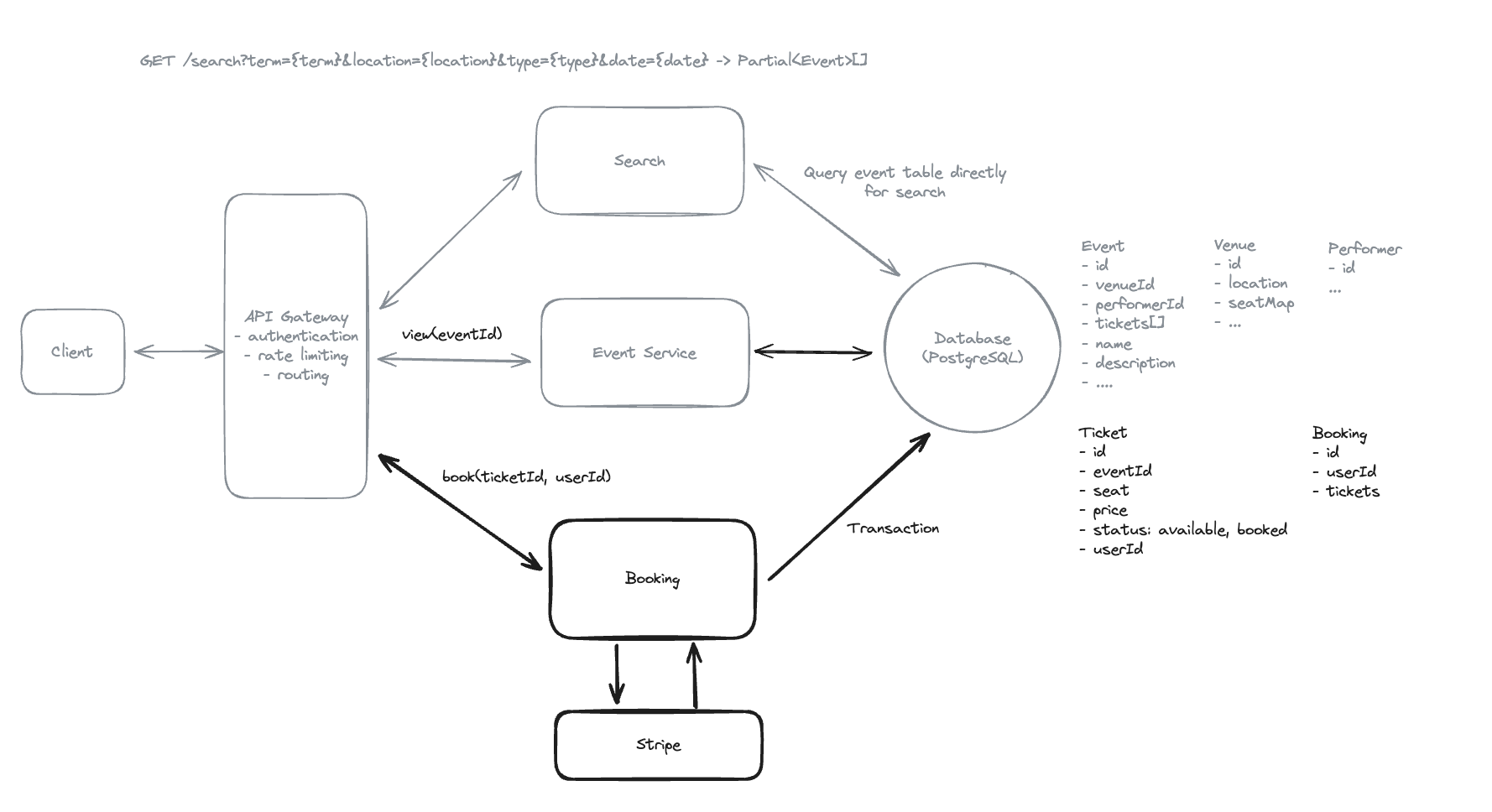
7.7. Implement a two-phase booking process:
- Seat Reservation: Temporarily hold selected seats.
- Booking Confirmation: Finalize purchase within a time limit.
How would you design this to prevent users from losing seats during checkout?
-
To implement the two-phase booking process and prevent users from losing seats during checkout, we’ll use a distributed lock system with Redis and a 10-minute TTL (Time to Live). When a user selects seats to reserve, the client sends a POST request to the Booking Service with the selected ticketIds. The Booking Service attempts to acquire locks for these seats in Redis, setting a TTL of 10 minutes for each lock. This reservation ensures that no other user can reserve or book the same seats during this period.
-
If the user completes the purchase within the 10-minute window, the Booking Service finalizes the booking by updating the ticket statuses to “booked”. If the user does not complete the purchase in time, the locks automatically expire due to the TTL, and the seats become available for others to reserve. This mechanism effectively prevents seat loss during checkout by exclusively holding seats for the user and automatically releasing them if the reservation times out.
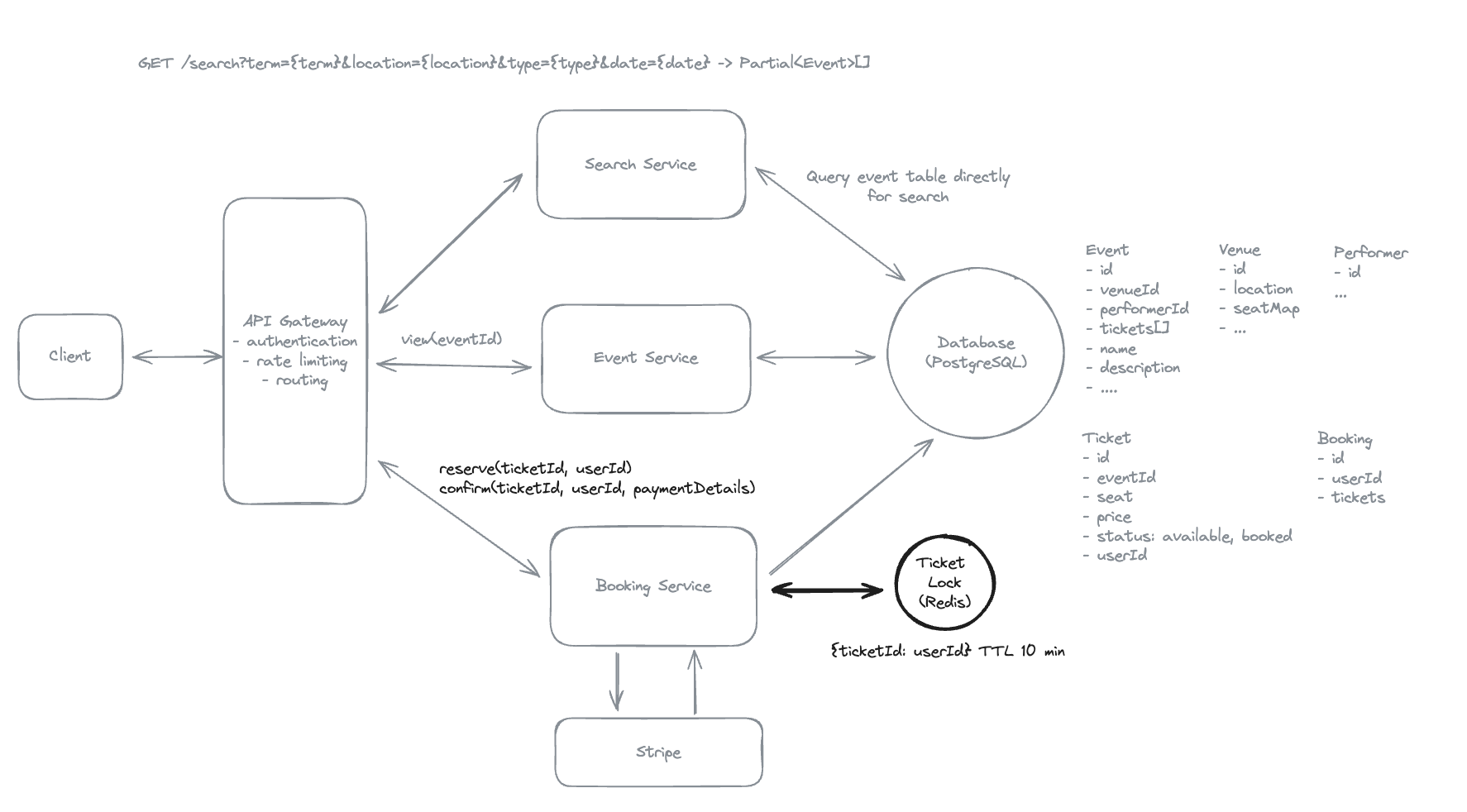
7.8. How can your design scale to support up to 10M concurrent users reading event data? Focus on optimizing the database and read flow for this high volume of requests.
- Read from cache => Read replicas, because Database engine need time to query.
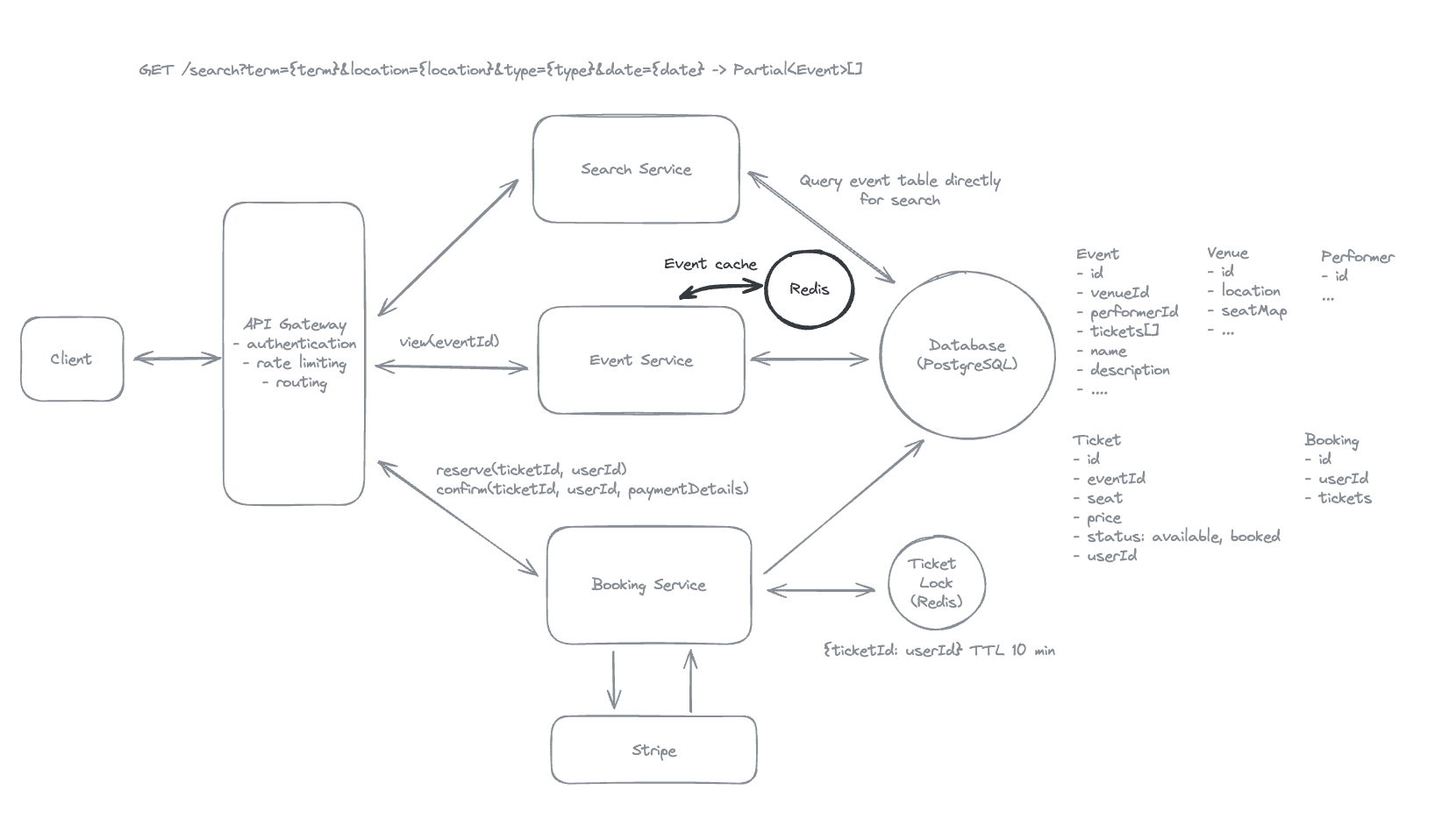
7.9. How can you improve search to handle complex queries more efficiently. If you think your design already handles this well, explain how.
- When search it return data from Elastic Search, rather than the database.
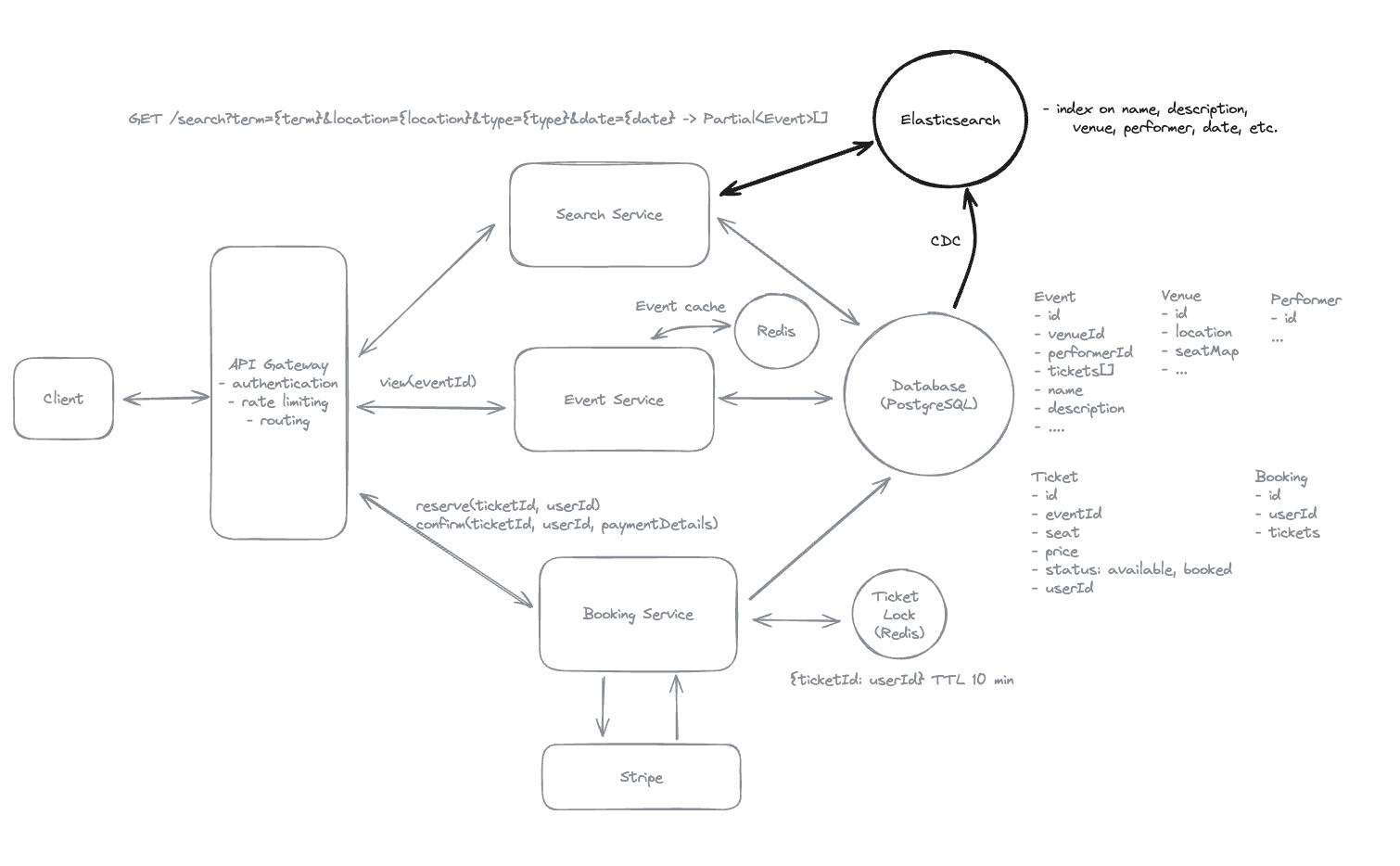
7.10. How can you make the seat map on the event page automatically refresh to display the latest seat availability in real time?
-
We can implement Server-Sent Events (SSE). When a user views the seat map on the event page, the client establishes an SSE connection to the Booking Service. The server then pushes updates to the client whenever there’s a change in seat availability—such as seats being reserved or booked by other users. On the client, we’ll receive these updates and block off the seats in the seat map accordingly.
-
As we scale, we may not be able to fit all connections for a single event on a single Booking Service instance. In this case, we can introduce pub/sub to broadcast changes or add a dispatcher that utilizes Zookeeper or a similar service to know which server to send updates to.
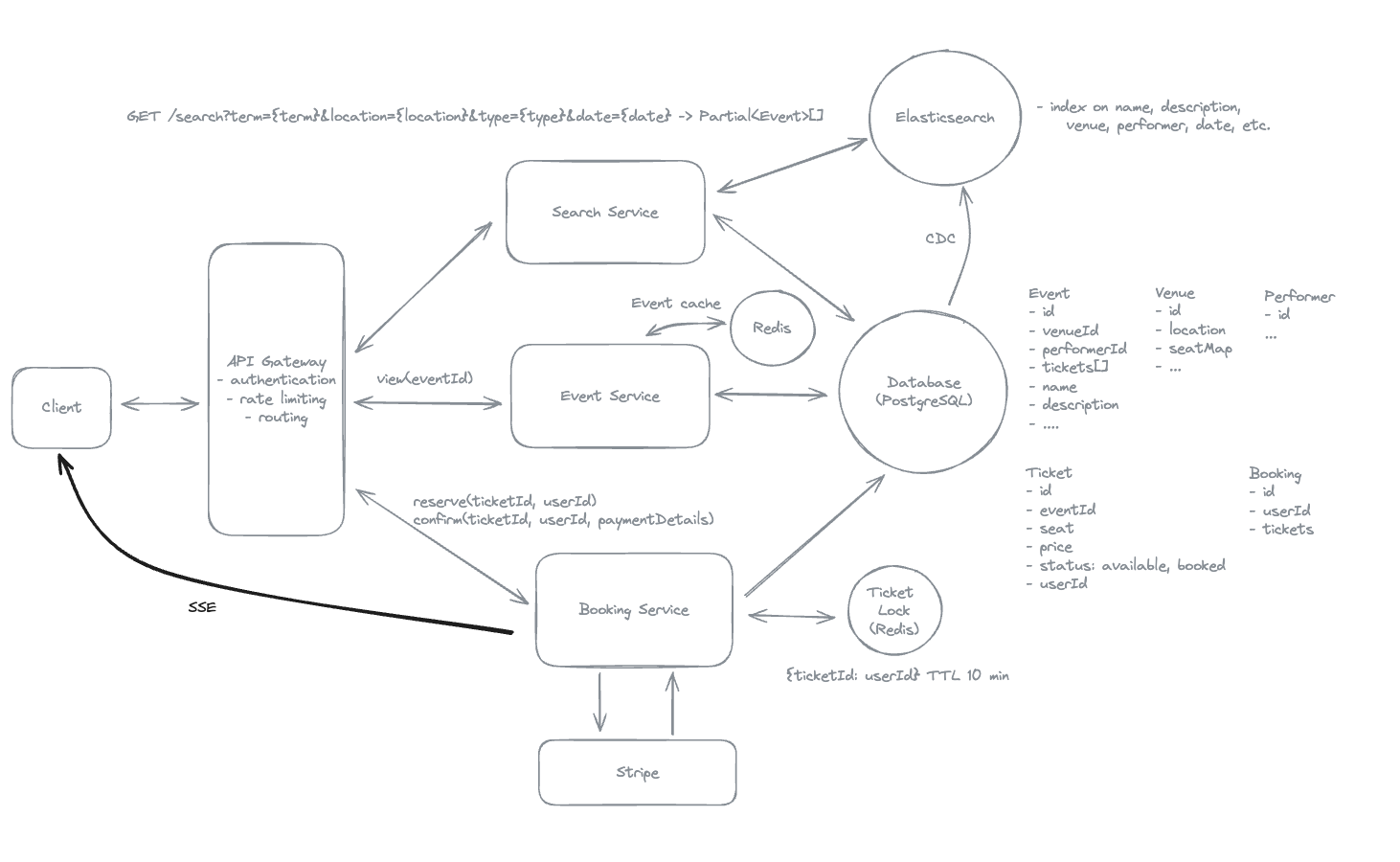
7.11. How would you implement a virtual waiting room that queues users for popular events and grants access based on their queue position?
-
We can implement a virtual waiting room using Redis’ Sorted Sets data structure. When users attempt to access the event page during peak times, they are redirected to a waiting room, and their session IDs are added to a Redis Sorted Set with their timestamp as the score, ensuring first-come-first-served order.
-
Every N minutes, or based on the number of completed bookings, we use ZRANGE to pull users from the front of the queue and grant them access to the event details page in a controlled manner, throttling the number of concurrent bookings and preventing system overload. This approach ensures fairness by serving users in the order they arrived and provides scalability to handle surges in traffic.
Example:
ZADD booking_queue 1625380000 user1
ZADD booking_queue 1625380001 user2
ZADD booking_queue 1625380002 user3
Top 100 users from 0 to 99.
ZRANGE booking_queue 0 99
-- KEYS[1] = ZSET key (e.g., "booking_queue")
-- ARGV[1] = user_id
-- ARGV[2] = score (e.g., timestamp)
-- ARGV[3] = max size (e.g., 100)
local zset = KEYS[1]
local user = ARGV[1]
local score = tonumber(ARGV[2])
local max_size = tonumber(ARGV[3])
-- Get current size
local current_size = redis.call("ZCARD", zset)
if current_size < max_size then
redis.call("ZADD", zset, score, user)
return "ADDED"
else
-- Get the lowest score entry
local lowest = redis.call("ZRANGE", zset, 0, 0, "WITHSCORES")
local lowest_user = lowest[1]
local lowest_score = tonumber(lowest[2])
if score > lowest_score then
-- Remove the oldest
redis.call("ZREM", zset, lowest_user)
-- Add the new user
redis.call("ZADD", zset, score, user)
return "REPLACED"
else
return "REJECTED"
end
end
7.12. Redis faster than Disk-based access
-
Because Redis is in-memory access.
-
DBMS is Disk-based access
7.13. Which consistency model prevents concurrent processes from allocating the same resource?
- Strong Consistency
7.14. Which approach works BEST for efficient partial text matching in search queries?
Full-text search engines
-
SQL Like: full table scans.
-
Elastic Search: Inverted Index, Fuzzy Matching.
7.15. Distributed locks prevent multiple processes from accessing shared resources simultaneously.
- Yes
7.16. A system needs to prevent double resource allocation, which database property is most essential?
- Transactions ensure that operations like checking availability and marking resources as allocated happen atomically.
=> Preventing race conditions where multiple users could claim the same resource simultaneously.
7.17. Horizontal Scale
- Stateless service.
7.18. Which technology enables real-time server-to-client data streaming without client polling?
- SSE.
7.19. What happens when a distributed lock’s TTL expires before the operation completes?
- Lock becomes available to other processes
7.20. Which strategy works BEST for managing millions of simultaneous users during high-demand events?
- Implement virtual waiting queues
7.21. Inverted indexes improve full-text search performance by mapping words to documents.
- True
7.22. When designing for high availability, which system component should prioritize consistency over availability?
- Payment processing must prioritize consistency to prevent double charges, financial discrepancies, and fraud.
8. Design FB News Feed
8.1. Non-functional Requirements

8.2. Entities

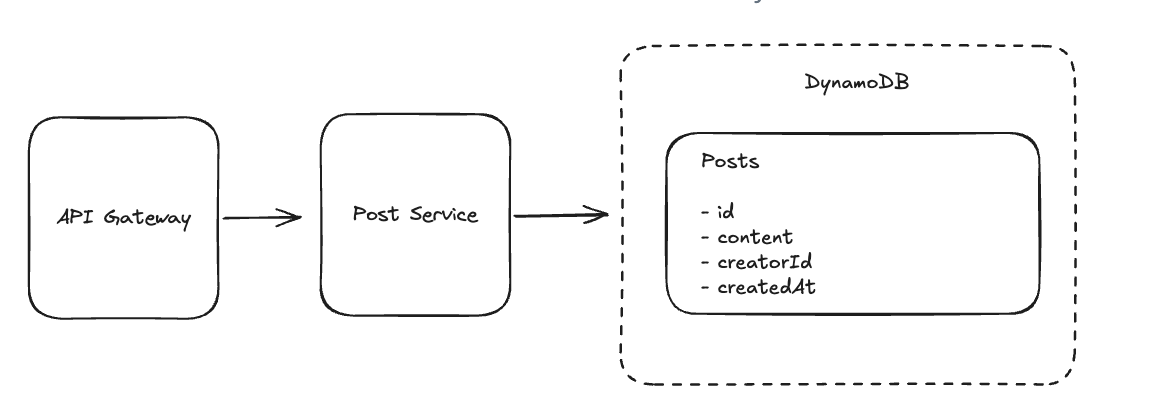
8.3. Users should be able to create posts
8.4. Users should be able to friend/follow people.
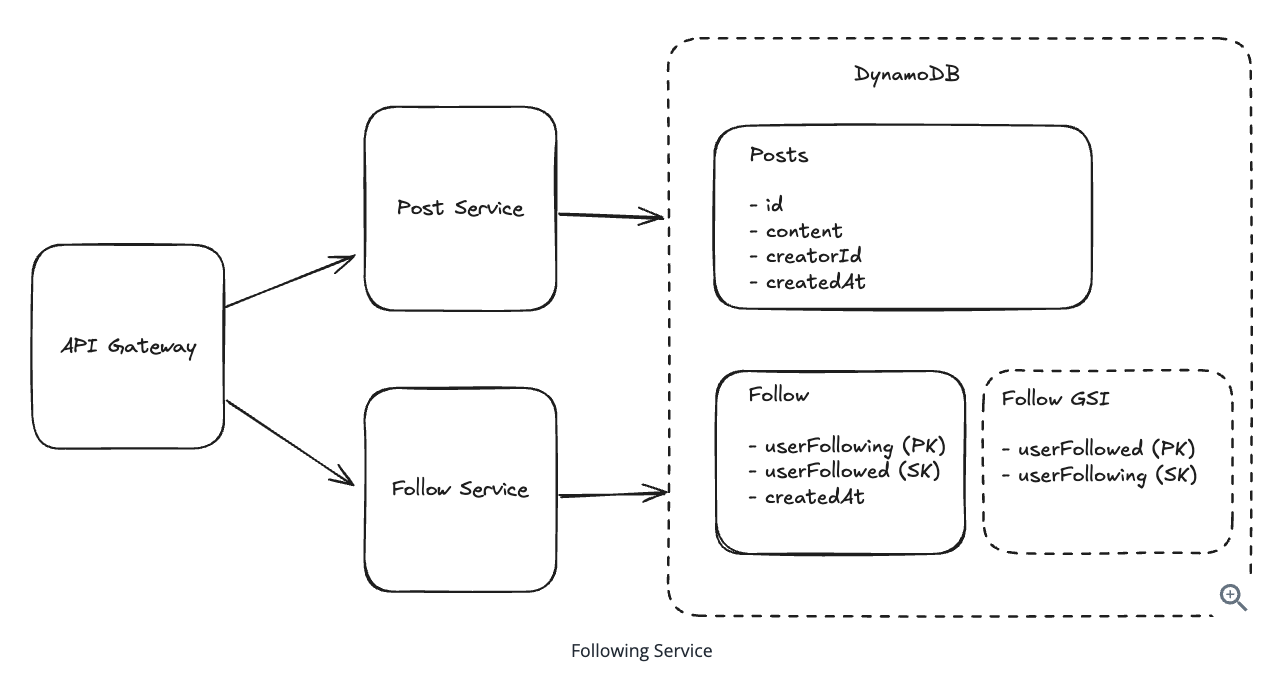
8.5. How do we handle users who are following a large number of users? (Push Model)
- Push by create new record: UserID -> FollowID -> FeedID
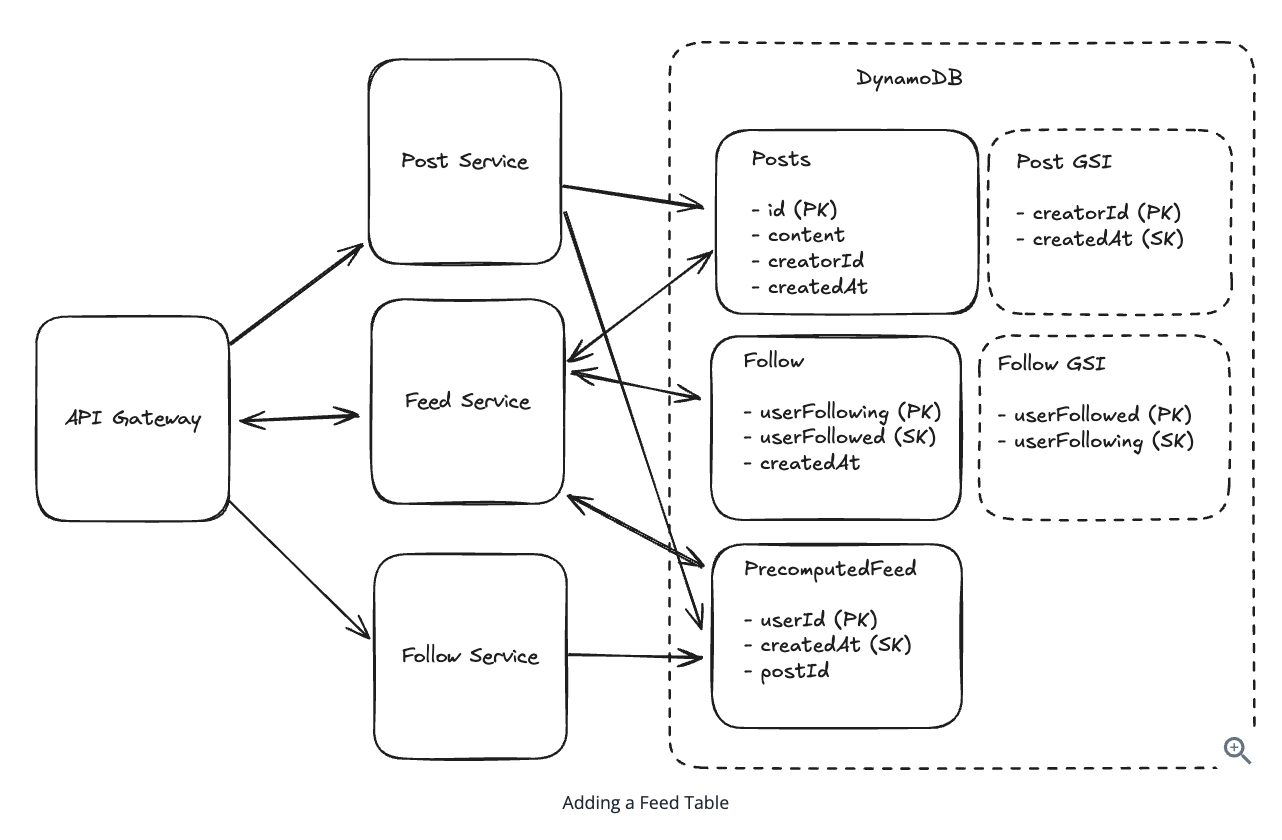
8.6. How do we handle users with a large number of followers?
- Celebrity Problem: Pull Model.
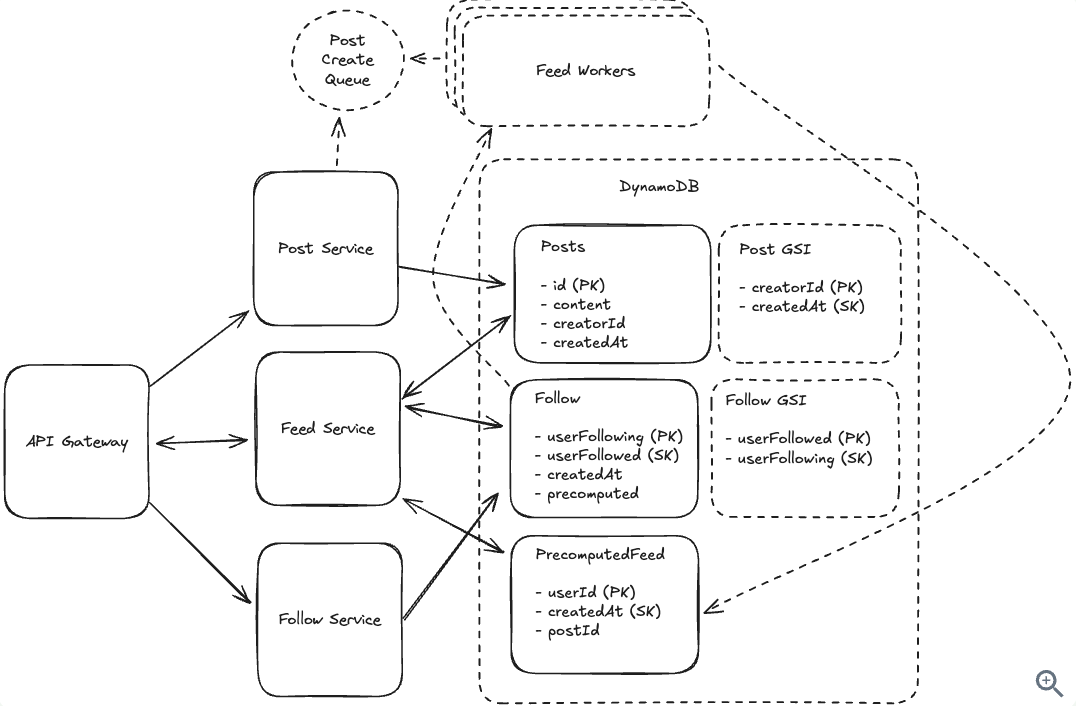
8.7. How can we handle heavy-read and unread of posts?
- Using Redis for heavy-read posts.
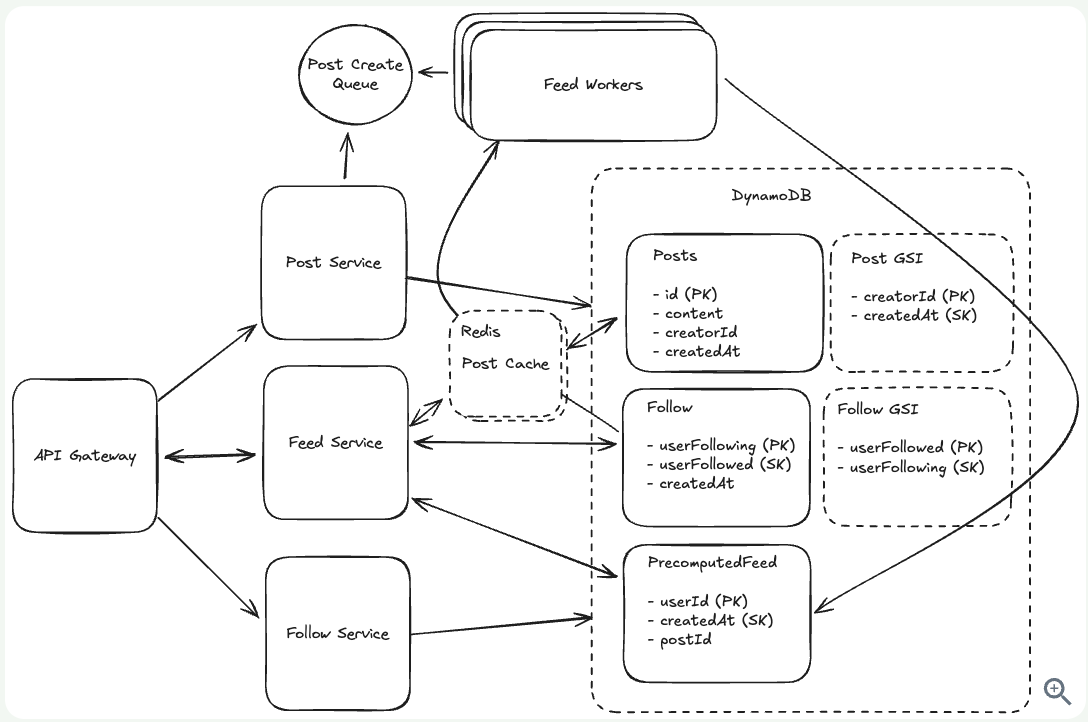
8.8. Fan-out on write means aggregating data at read time when a user requests their feed.
-
Fan-out on write means pre-aggregating data when posts are created (at write time).
-
While fan-out on read means aggregating data when users request their feed (at read time).
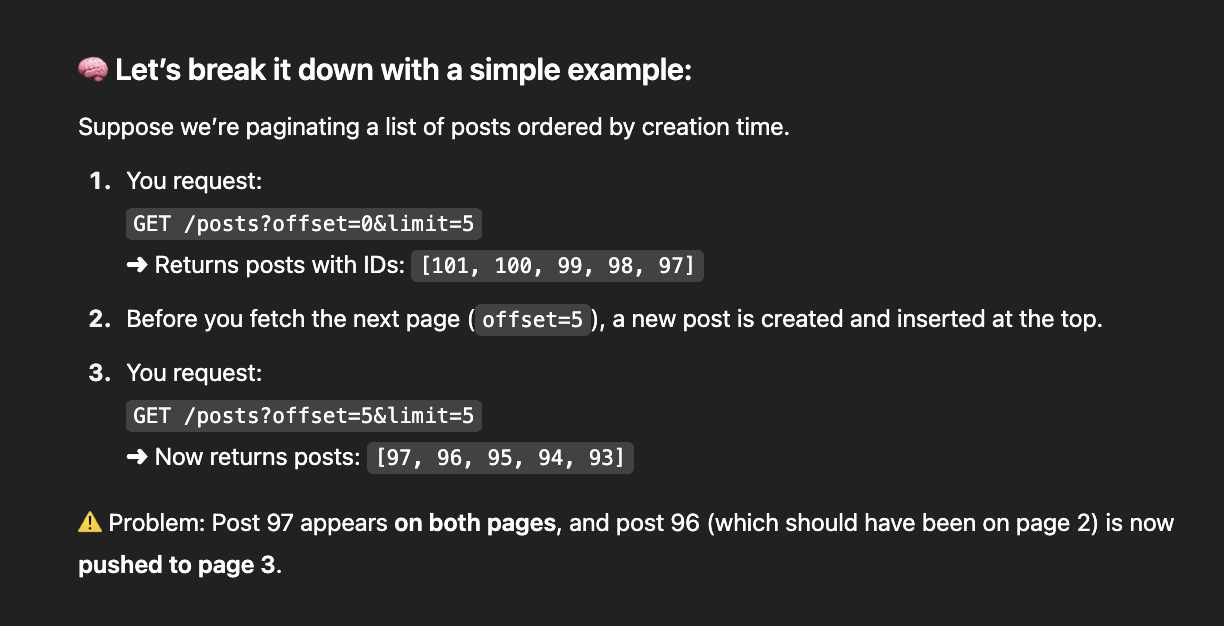
8.9. Key-value stores can scale infinitely regardless of how requests are distributed across the keyspace.
-
Key-value stores require even load distribution across partitions to scale effectively.
-
If certain keys get much more traffic (hot keys), those partitions become bottlenecks, limiting scalability.
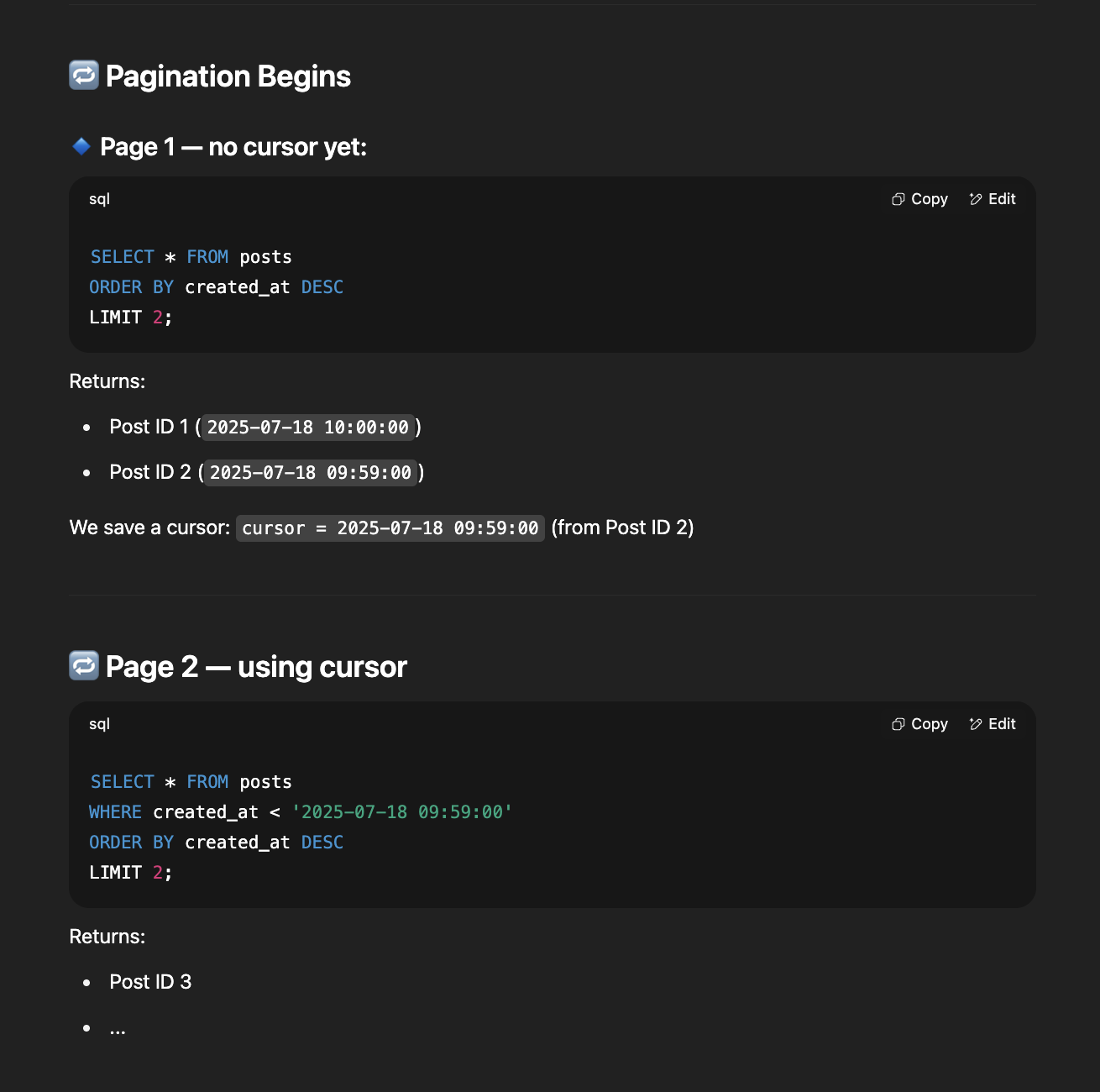
8.10. Secondary indexes in databases are primarily used to improve write performance rather than enable different query patterns.
- Secodary Index: Support read, but longer write.
8.11. What is the most effective approach to handle hot keys in a distributed cache system?
- Implement redundant caching where multiple nodes can serve the same popular keys
8.12. For modeling follow relationships in a social network using a key-value store, what is the most efficient approach for supporting both ‘who does user X follow’ and ‘who follows user X’ queries?
-
Create a table with composite keys and a secondary index with reversed keys
-
Idea: Using composite keys (follower:following) with a secondary index that reverses the key order (following:follower) allows efficient querying of both access patterns in a single table structure, which is optimal for key-value stores.
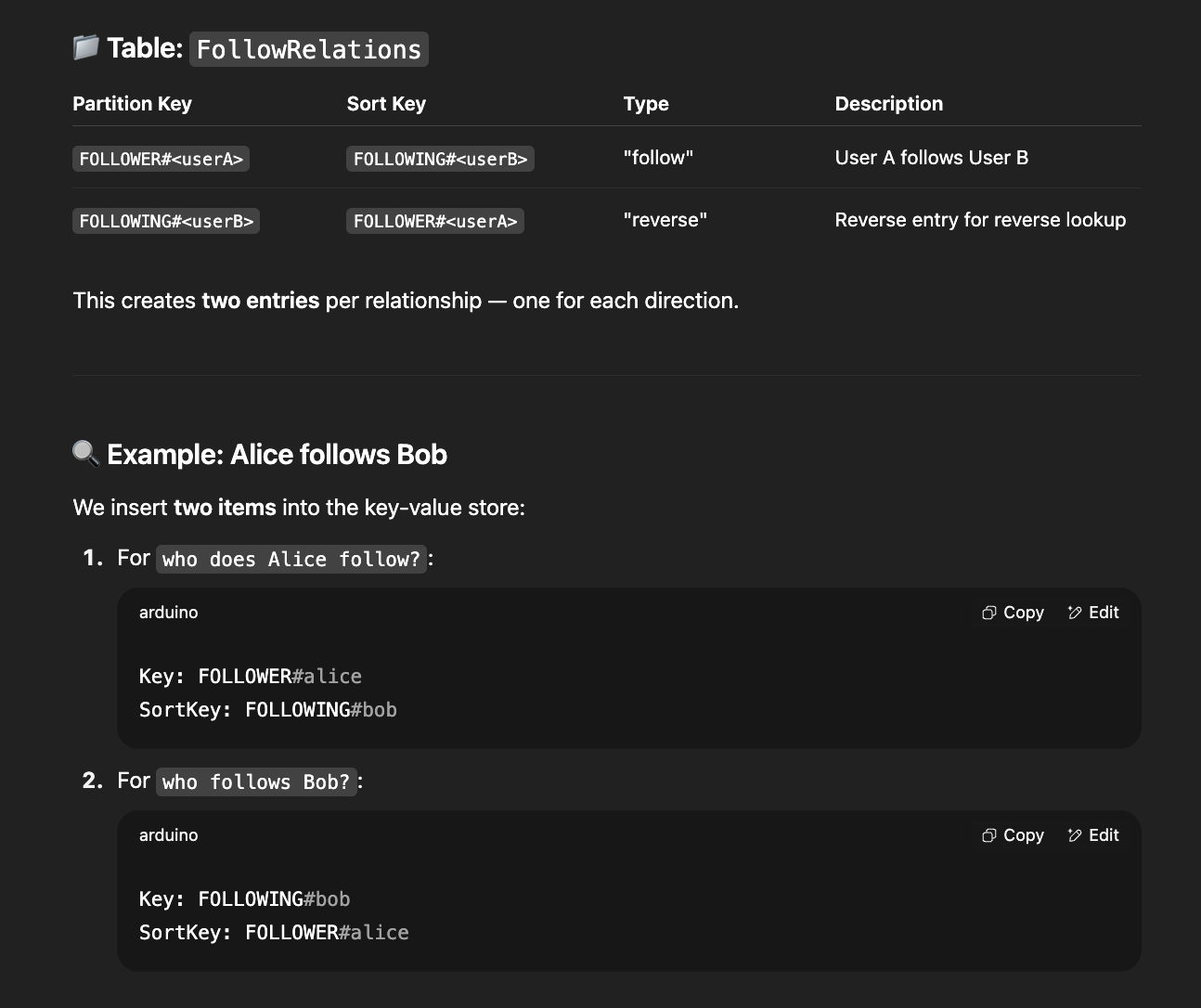
- Efficient lookups: All queries are direct key-prefix scans (ideal for key-value stores).
🔑 Partition Key & Sort Key
- Partition Key: Determines which physical partition (node/shard) the item is stored on.
- Sort Key: Determines the order of items within a partition.
8.13. What is the primary benefit of maintaining precomputed feeds for users in a social media system?
- Cache is pre-computed.
8.14. In the context of the CAP theorem, a social media feed system that tolerates up to 1 minute of post staleness is prioritizing which combination?
- Availability and Partition tolerance
8.15. In a hybrid fan-out strategy for social feeds, what is the most practical approach for handling celebrity accounts with millions of followers?
- Skipping fan-out for celebrity accounts (not writing to millions of feeds) and instead merging their recent posts during read operations is more efficient than trying to update millions of precomputed feeds.
8.16. Why are stateless services easier to scale horizontally compared to stateful services?
-
Any instance can handle any request without needing to maintain session data
-
Idea: Horizontal Scaling.
8.17. When using message queues to handle posts from users with varying follower counts, what is a key consideration for queue design?
- Posts from users with few followers require little work (updating few feeds), while posts from users with millions of followers require massive work. The queue system needs to account for this variable workload to avoid bottlenecks.
9. Design Tinder
9.1. Functional Requirements

9.2. Non-functional Requirements

9.3. Entities
- Actor of your system, discover later.

9.4. API Design
- Each demand (requirement) => 1 Endpoint

- View and Actions
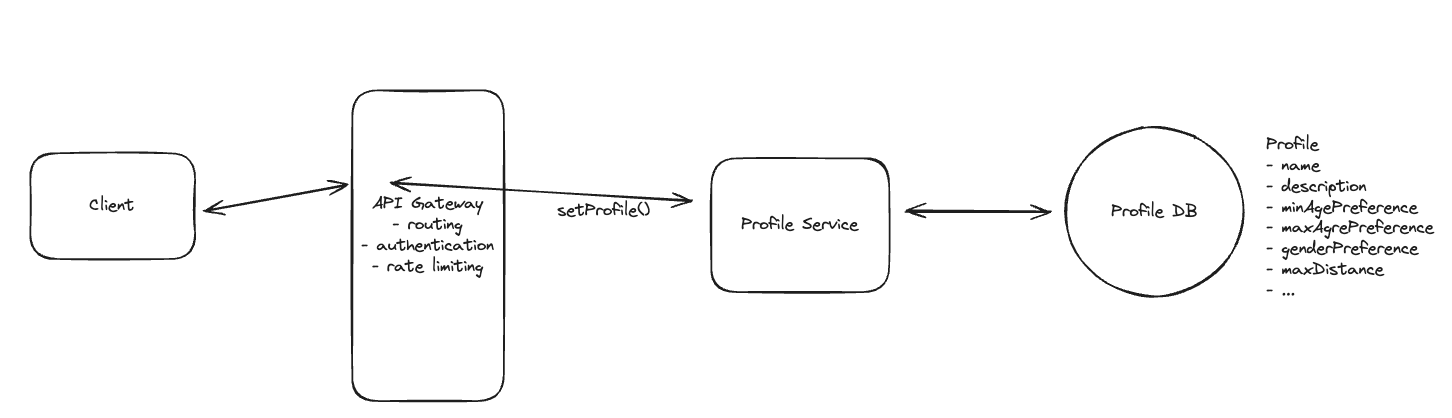
9.5. How will users be able to create a profile and set their preferences?
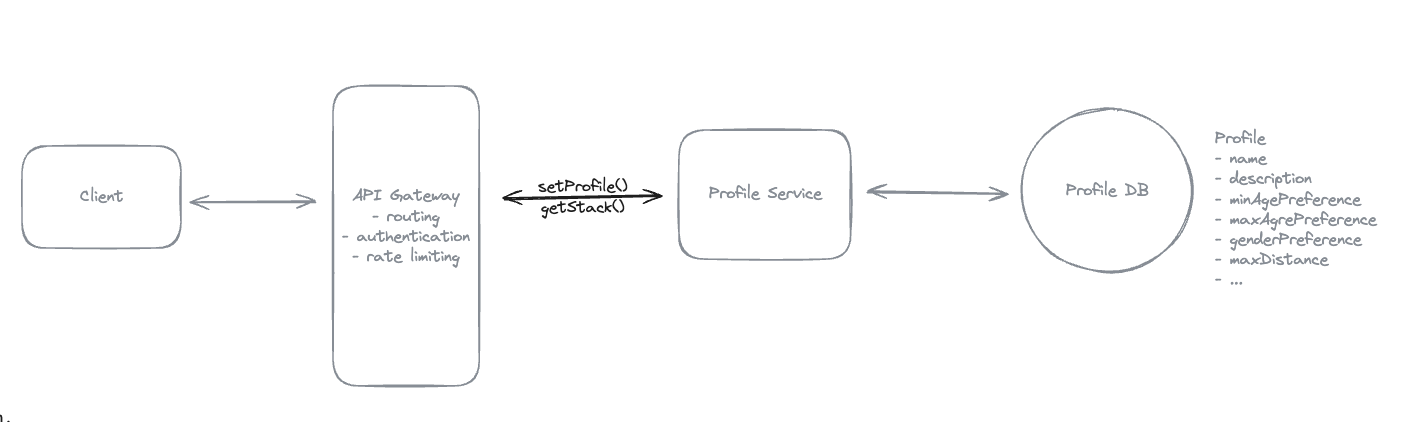
9.6. How will users be able to get a stack of recommended matches based on their preferences?
9.7. How will the system register and process user swipes (right/left) to express interest in other users, showing a match if you swipe right (like) on someone who already liked you?
- Using Cassandra for heavy-write.
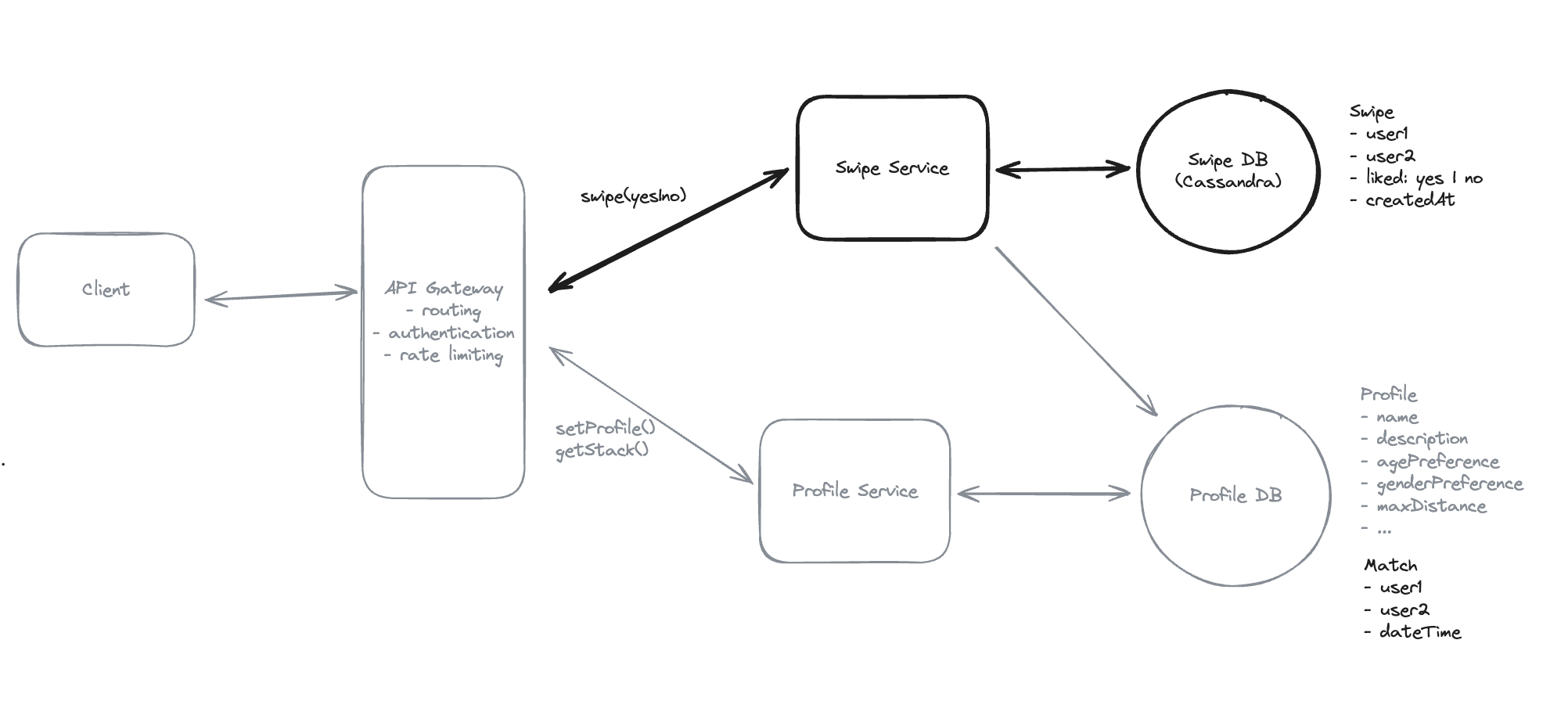
9.8. The other user needs to know that they have a new match as well, how will your system notify them?
- Using: Apple Push Notification Service (APNs) for iOS or Firebase Cloud Messaging (FCM) for Android
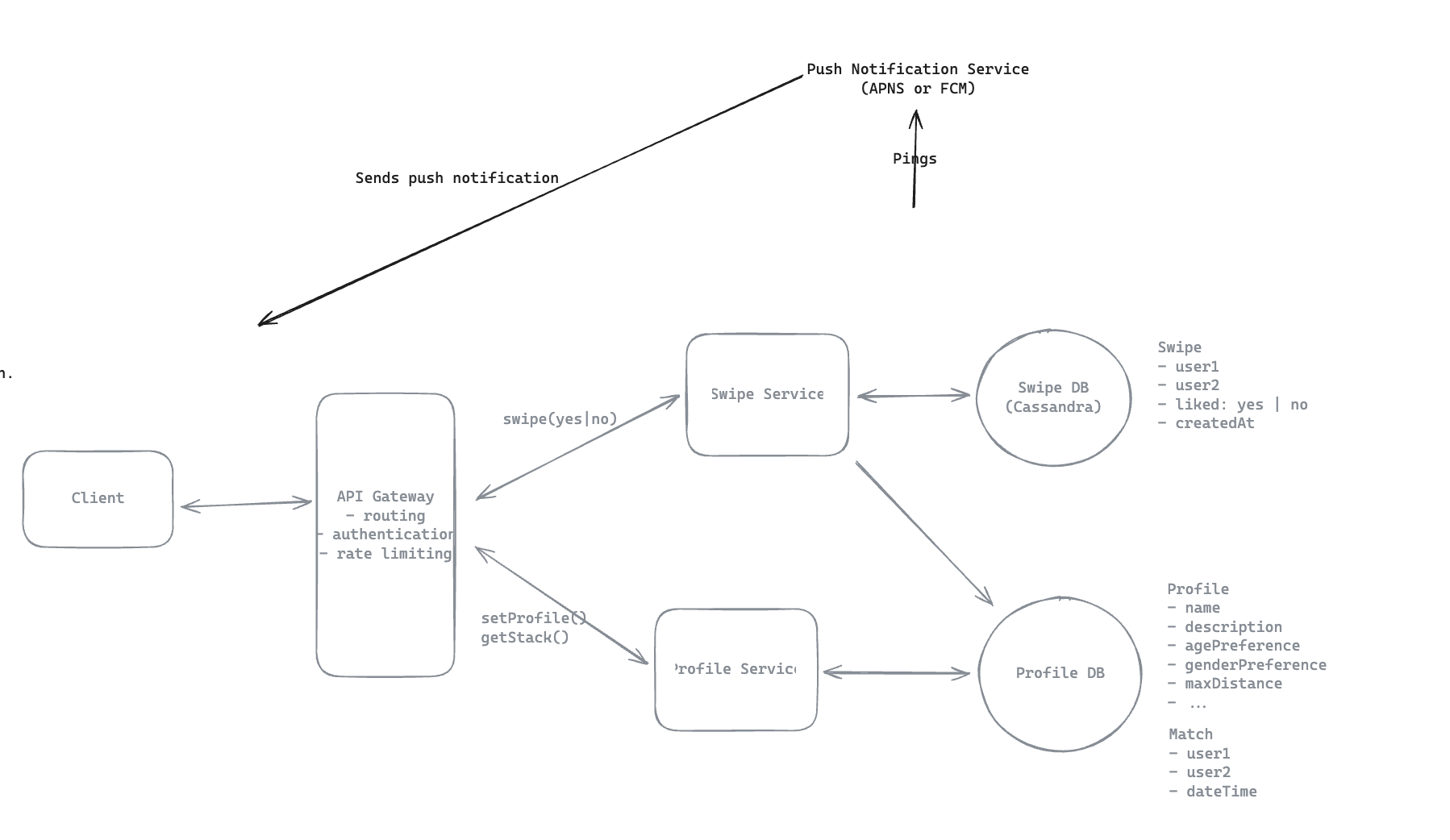
9.9. How would you design the system to ensure that swipe actions are processed both consistently and rapidly, so that when a user likes someone who has already liked them—even if only moments before—they are immediately notified of the match?
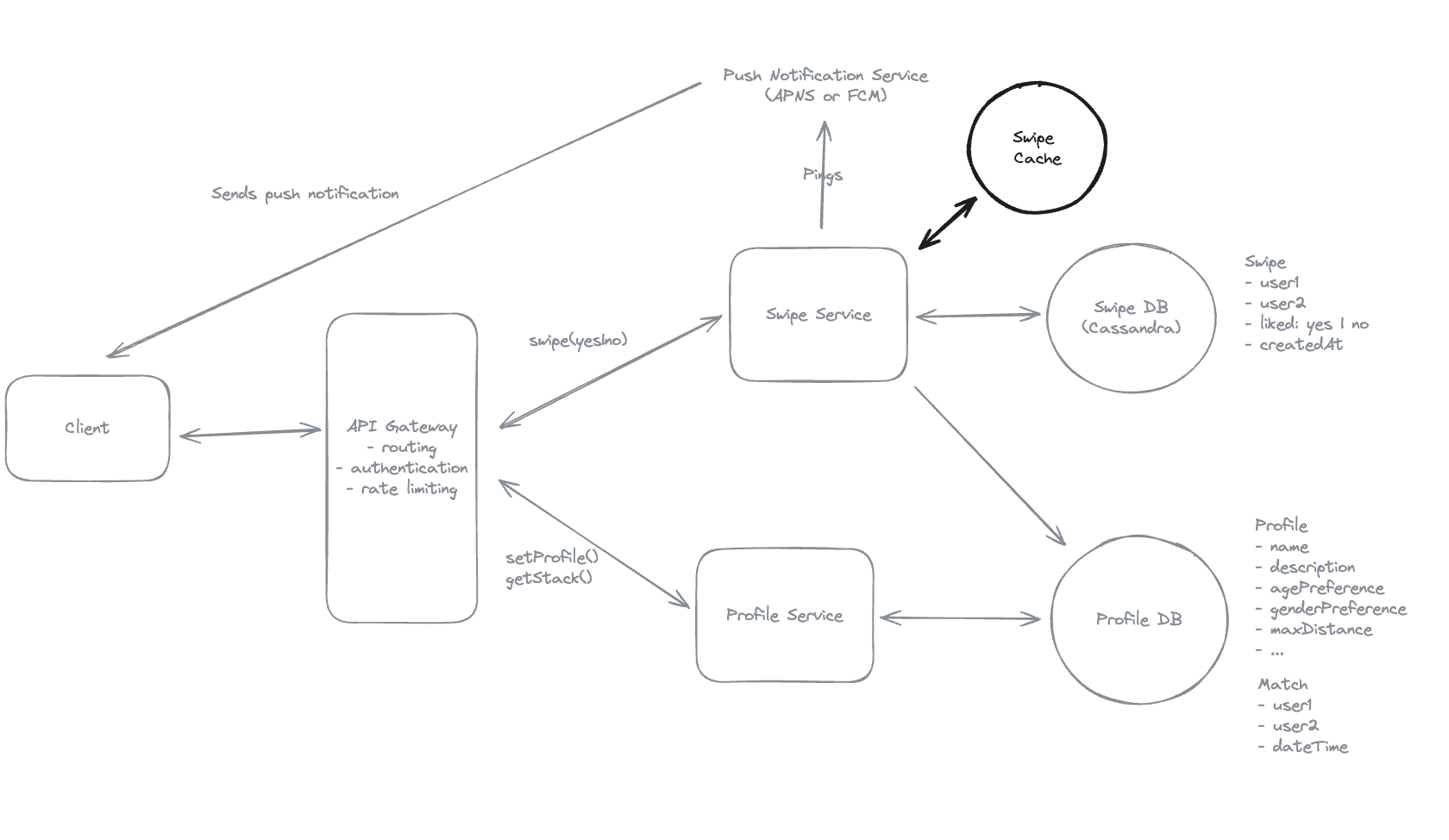
9.10. How can we ensure low latency for feed/stack generation?
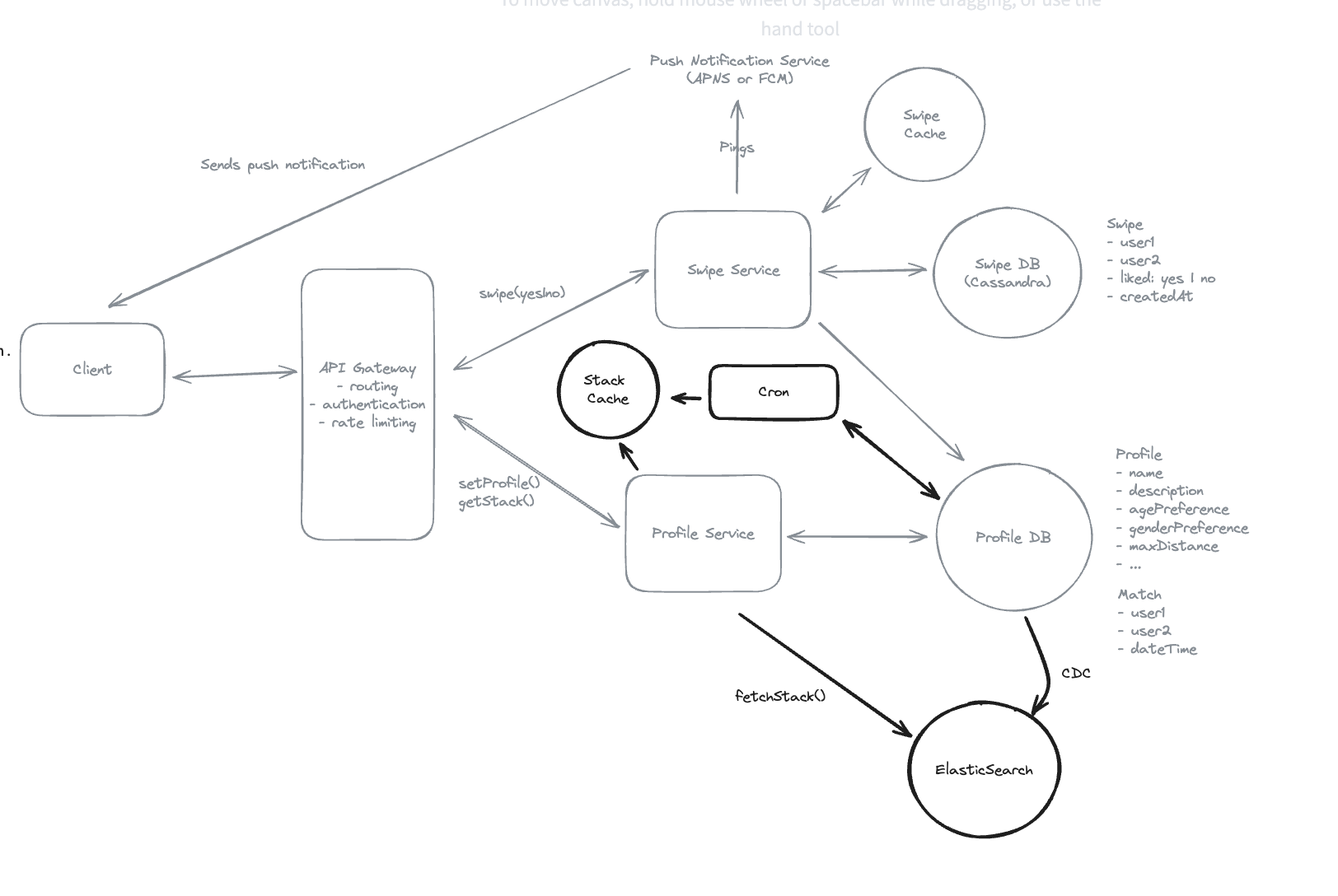
9.11. How can the system avoid showing user profiles that the user has previously swiped on?
-
For users with relatively small swipe histories: Using cache to filter out.
-
For users with larger swipe histories: Using bloom filter to check if a profile has likely been swiped on.
-
One trade-off with bloom filters is that they can produce false positives but never false negatives.
-
Bloom Filters: If the users have swiped on => must be never show => pass requirements, but maybe filter out some users have not swiped on.
=> If the Bloom filter says the element is NOT in the set, then it’s definitely not => print(bf.might_contain(“grape”)) == False, it is definately not have in the set. => If the bloom filter says yes, maybe yes or no.
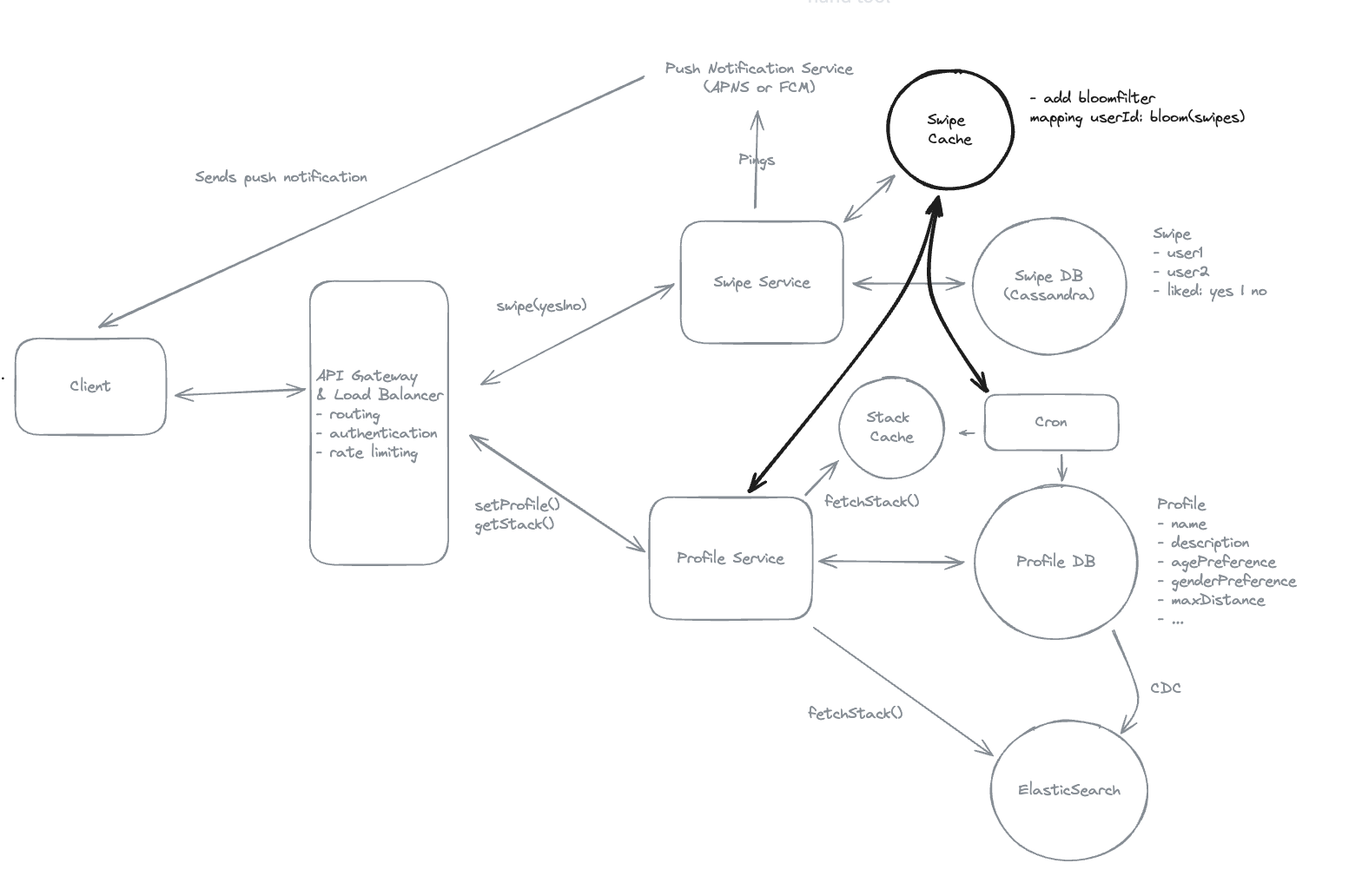
9.12. Redis is single-threaded. Atomic operations prevent race conditions when multiple processes access shared resources concurrently.
- True, Single-threaded do not need to worry about conflicts.
9.13. Which data structure efficiently handles 2D proximity searches for location-based queries?
- Geospatial Index
9.14. Write-optimized databases like Cassandra sacrifice immediate consistency for higher write throughput.
- Write-optimized databases typically use append-only structures (like commit logs) and eventual consistency models to maximize write performance.
9.15. Write buffer size optimization improves write performance by batching disk writes, but doesn’t directly improve read performance.
- Yes
9.16. Bloom filters can produce false positives but never false negatives when testing set membership.
- Yes
9.17. Why do systems use Lua scripts in Redis for atomic operations like swipe matching?
-
Lua scripts in Redis execute atomically on the server side => ensure it happen as a single atomic unit.
-
This prevents race conditions where two users might swipe simultaneously and miss detecting a match.
9.18. Pre-computing and caching data reduces query latency at the cost of potentially serving stale information.
- Yes
9.19. Why do dating apps partition swipe data by sorted user ID pairs (e.g., ‘user123:user456’)?
-
By creating partition keys from sorted user IDs, systems ensure that swipes between any two users (A→B and B→A) always land in the same database partition.
-
This enables single-partition transactions for atomic match detection, avoiding the complexity and performance overhead of distributed transactions.
9.20. Bloom filters are ideal for preventing users from seeing profiles they’ve already swiped on because they never produce false negatives.
- Show the items that have not existed => Bloom Filters.
9.21 (Hay). In systems with high write loads, which consistency model is typically chosen and why?
- Eventual consistency, have bandwidth and resource for write.
9.22. Client-side caching can reduce server load but requires careful invalidation strategies to maintain data accuracy.
- Yes
9.23. Cache Staleness strategy
-
Time-based TTL.
-
Periodic background refresh.
-
Event-driven cache invalidation.
9.24. Consistent hashing minimizes data redistribution when nodes are added or removed from a distributed system.
- Yes
9.25 (Hay). Why do dating apps use geospatial indexes instead of simple latitude/longitude range queries?
-
Range queries don’t account for Earth’s curvature
-
Range queries only work in flat rectangle, not work for curve of the Earth.
-
Geospatial indexes like R-trees account for true geographic distance calculations.
9.26. Using Redis for match detection and Cassandra for durable swipe storage creates consistency challenges that require careful coordination.
-
This dual-storage approach gains Redis’s atomic operations for real-time matching.Cassandra’s durability for historical data, but creates a consistency gap.
-
If Redis fails after detecting a match but before Cassandra persists the swipe, the match could be lost.
10. Patterns
10.1. Real-time Updates
10.1.1. Network Protocol
-
Network Layer (Layer 3):
- Assigns IP addresses (IPv4 or IPv6) to devices.
- Splits large packets into smaller ones if needed.
-
Transport Layer (Layer 4):
-
TCP: connection-oriented protocol: before you can send data, you need to establish a connection with the other side.
-
UDP: connectionless protocol: you can send data to any other IP address on the network without any prior setup.
-
TCP tracks every byte sent and requires ACKs to confirm receipt. If packets get lost, TCP retransmits them. UDP simply doesn’t do this, TCP ensures data arrives in order.
-
-
Application Layer (Layer 7): At the final layer are the application protocols like DNS, HTTP, Websockets, WebRTC => DNS can choose to use TCP or UDP.
TCP Connection
-
When user make connections using TCP -> Three-way handshanking + Make requests + Finish.
-
When a user makes REST requests like GET, POST, or PUT, the underlying transport protocol is typically TCP, can use keep-alive for sessions.
Load Balancers
-
Layer 4 Load Balancers: AWS Network Load Balancer => Load to IP layer
-
Layer 7 Load Balancers: API Gateway => Load HTTP requests.
-
It works together
User Request --> Layer 4 Load Balancer --> Layer 7 Load Balancer --> Backend Server
Internet
↓
Layer 4 Load Balancer (e.g., AWS Network Load Balancer)
↓
Layer 7 Load Balancer (e.g., AWS Application Load Balancer, NGINX)
↓
Backend servers (web servers, APIs, etc.)
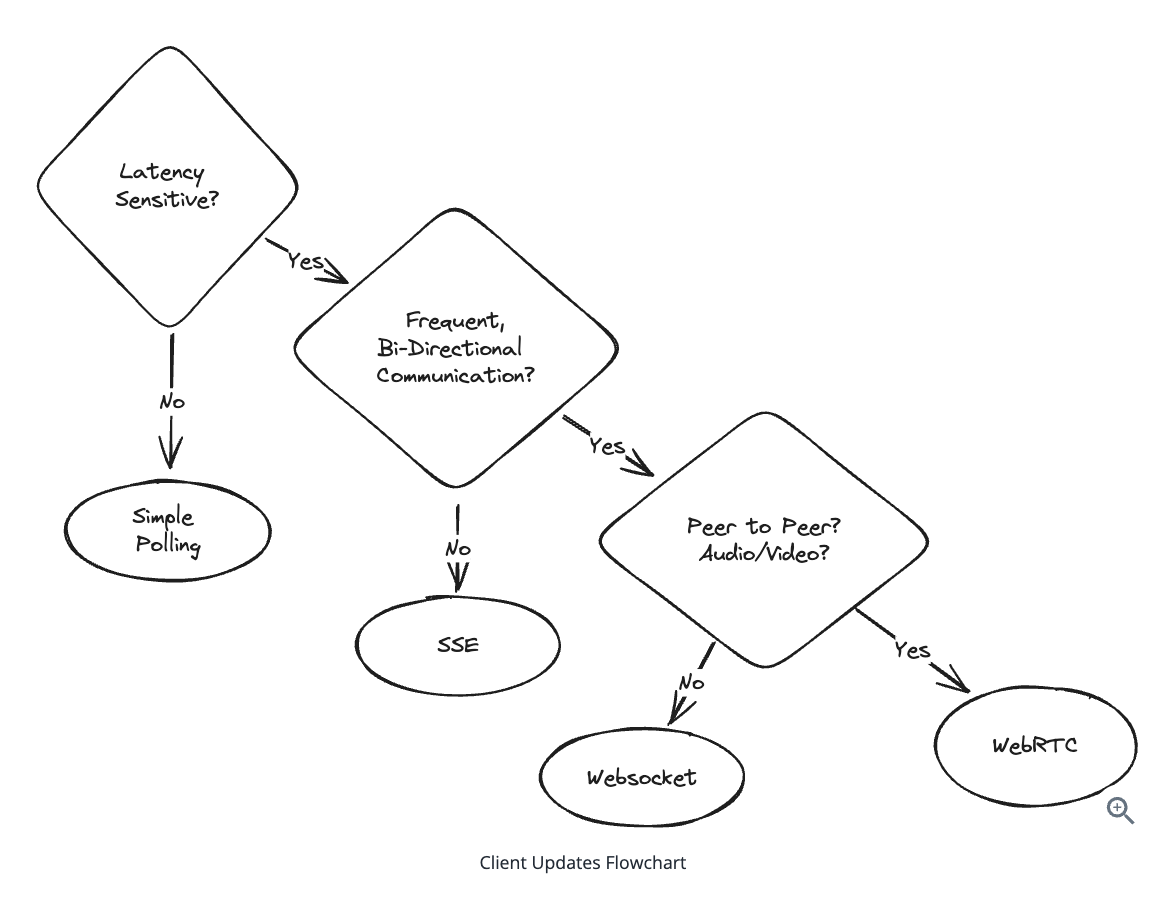
10.1.2. Client Updates
1. Simple Polling
Cons:
-
Can cause unnecessary network traffic (lots of requests with no new data).
-
Higher latency for real-time updates because client only checks periodically.
async function poll() {
const response = await fetch('/api/updates');
const data = await response.json();
processData(data);
}
// Poll every 2 seconds
setInterval(poll, 2000);
2. Long Polling
-
Server only requests when it have more data -> Else it hold the requests, client do not need to make requests.
- Step 1: Client makes HTTP request to server
- Step 2: Server holds request open until new data is available
- Step 3: Server responds with data
- Step 4: Client immediately makes new request
- Step 5: Process repeats
-
In simple polling, the client checks for new data only at fixed intervals (e.g., every 5 seconds). If new data arrives just after a check, the client has to wait until the next interval to find out — causing a delay that can be several seconds.
-
In long polling, the client sends a request and the server holds this request open until new data is available.
When the data arrives, the server immediately responds.
-
The client then instantly sends a new request to listen for more updates.
-
Because the server responds as soon as new data is available, the delay between data creation and client notification is minimized—usually just the network latency and processing time.
Cons:
-
More complex to implement.
-
Holding many open connections can strain the server.
Different Long Polling and Web Socket
-
Long polling: HTTP request/response cycle.
-
Web Socket: Persistent, full-duplex TCP
3. Server-Sent Events (SSE)
Cons:
-
Limited browser support EventSource.
-
One-way communication only: Server to Client.
4. WebSocket: The Full-Duplex Champion
Cons:
- More complex to implement.
- Requires special infrastructure.
- Stateful connections, can make load balancing and scaling more complex.
5. WebRTC: The Peer-to-Peer Solution
Use for video calling, peer-to-peer connection.
-
Peers discover each other through signaling server.
-
Exchange connection info (ICE candidates)
-
Establish direct peer connection, using STUN/TURN if needed
-
Stream audio/video or send data directly
WebSocket — When to Use
- Client-server communication: WebSocket creates a persistent, full-duplex connection between a client and a server.
WebRTC — When to Use
- Peer-to-peer communication: WebRTC enables direct, low-latency peer-to-peer connections between browsers/devices.
const config = {
iceServers: [{ urls: 'stun:stun.l.google.com:19302' }],
};
-
STUN server: Helps peers find their public IP addresses to connect through NATs/firewalls.
-
TURN server: Relays media/data if a direct peer-to-peer connection can’t be established (e.g., due to restrictive NATs).
10.1.3. Server Pull/Push
- Pulling with Simple Polling
Cons:
- High latency.
- Excess DB load when updates are infrequent and polling is frequent.
- Pushing via Consistent Hashes
- Each server -> Each client fixed.
Zookeepers is used to store metadata of clients and servers.
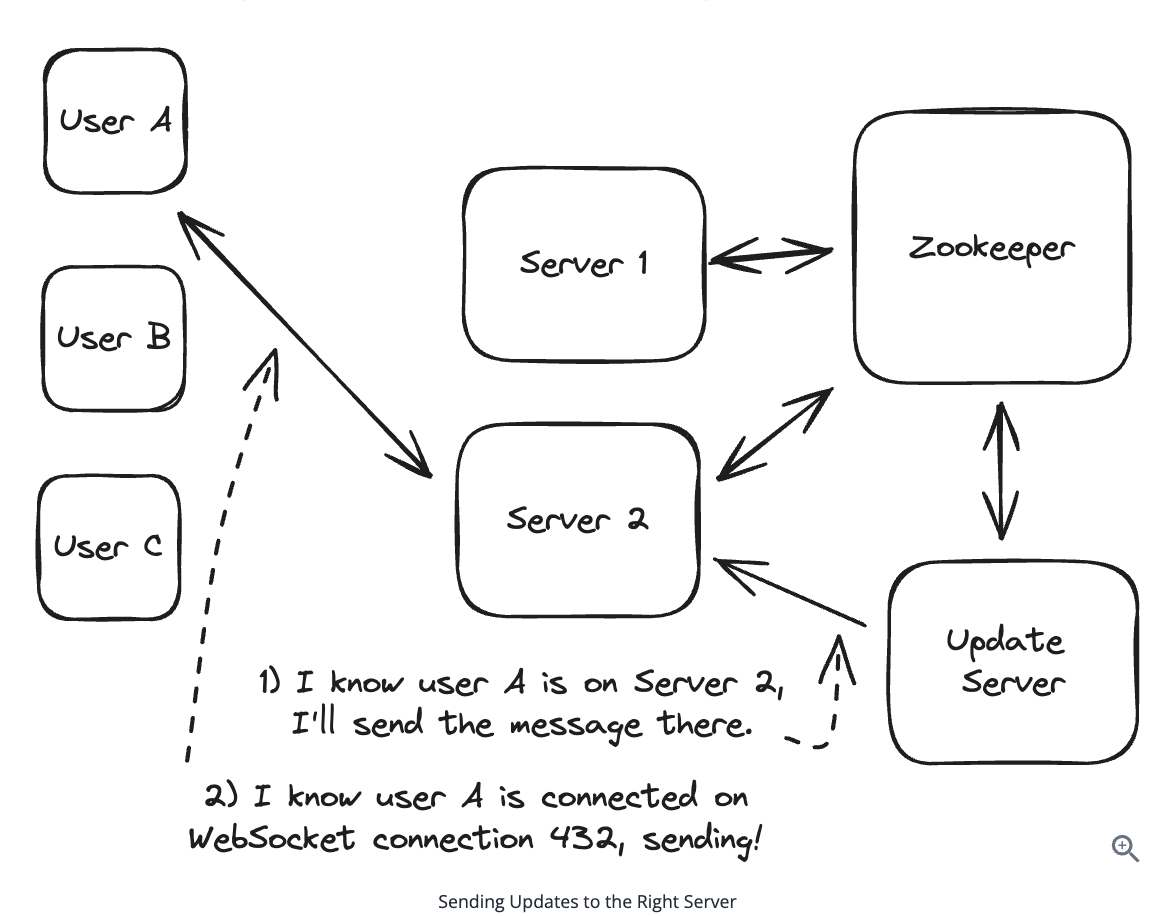
Cons:
-
Complex to implement correctly
-
Requires coordination service (like Zookeeper)
-
All servers need to maintain routing information
When to use:
-
WebSocket: stateful
-
Consistent hashing is ideal when you need to maintain persistent connections (WebSocket/SSE) and your system needs to scale dynamically, state ‘on’, ‘off’.
- Pushing via Pub/Sub
Cons:
- The Pub/Sub service becomes a single point of failure and bottleneck.
10.1.4. WebSockets require every intermediary (load balancers, proxies) between client and server to support the upgrade handshake.
- Yes
10.1.5. Which load balancer type (per the OSI model) is generally preferred when terminating long-lived WebSocket connections?
- L4 balancers operate at the TCP layer and preserve the single underlying connection, avoiding issues some L7 proxies have with WebSocket stickiness.
10.1.6. Consistent hashing reduces connection churn when scaling endpoint servers up or down.
-
True because it auto sharding to another nodes in ring architecture.
-
Only the keys mapping to the portion of the hash ring owned by added/removed nodes move, so most clients stay put.
10.1.7. In a pub/sub architecture, which component is responsible for routing published messages to all active subscribers?
- Message Queue.
10.1.8. WebRTC always guarantees a direct peer-to-peer path between browsers without relays.
-
Success: STUN: Help a client find its public IP address and port as seen from the internet (outside its NAT) - Session Traversal Utilities for NAT
-
Failed (Fallback): TURN: Relay data between peers when direct connection isn’t possible - Traversal Using Relays around NAT
-
When NAT traversal fails, TURN relays forward traffic, so not all flows are purely peer-to-peer.
10.1.9. Using a “least connections” strategy at the load balancer helps distribute WebSocket clients more evenly across endpoint servers.
- Yes
10.1.10. When would you MOST LIKELY choose consistent hashing over a pub/sub approach on the server side?
- If per-client state is heavy, pinning that user to one server (via hashing) avoids expensive state transfer and cache misses => Fixed some client state to server to save resources.
10.1.11. SSE streams can be buffered by misconfigured proxies, delaying updates to clients even though the server flushes chunks immediately.
- Proxies that don’t support Transfer-Encoding: chunked may wait for the full response before forwarding, defeating streaming semantics.
10.2. Dealing with Contention
10.2.1. Transaction
BEGIN TRANSACTION;
-- Debit Alice's account
UPDATE accounts SET balance = balance - 100 WHERE user_id = 'alice';
-- Credit Bob's account
UPDATE accounts SET balance = balance + 100 WHERE user_id = 'bob';
COMMIT; -- Both operations succeed together
Transaction
BEGIN TRANSACTION;
-- Check and reserve the seat
UPDATE concerts
SET available_seats = available_seats - 1
WHERE concert_id = 'weeknd_tour'
AND available_seats >= 1;
-- Create the ticket record
INSERT INTO tickets (user_id, concert_id, seat_number, purchase_time)
VALUES ('user123', 'weeknd_tour', 'A15', NOW());
COMMIT;
10.2.2. Pessimistic Locking
- “Pessimistic” about conflicts - assuming they will happen and preventing them.
When a transaction or thread wants to access a resource (like a row in a table), it locks it before reading or writing. Other transactions/threads must wait until the lock is released.
Types of Locks:
-
Read Lock (Shared Lock): Others can also read, but not write.
-
Write Lock (Exclusive Lock): Others can’t read or write.
BEGIN;
SELECT * FROM accounts WHERE id = 101 FOR UPDATE;
-- Do some update here
UPDATE accounts SET balance = balance - 100 WHERE id = 101;
COMMIT;
optimi
10.2.3. Optimistic locking
Update success
UPDATE accounts
SET balance = 900, version = 4
WHERE id = 1 AND version = 3;
Update failed
UPDATE accounts
SET balance = 800, version = 4
WHERE id = 1 AND version = 3;
10.2.4. Isolation Levels
-
READ UNCOMMITTED: Can see uncommitted changes from other transactions (rarely used)
-
READ COMMITTED: Can only see committed changes (default in PostgreSQL)
-
REPEATABLE READ: Same data read multiple times within a transaction stays consistent (default in MySQL)
-
SERIALIZABLE: Strongest isolation, transactions appear to run one after another
The defaults of either READ COMMITTED or REPEATABLE READ => still allows our concert ticket race condition because both Alice and Bob can read “1 seat available” simultaneously before updating.
Solution: Using SERIALIZABLE
-- Set isolation level for this transaction
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
UPDATE concerts
SET available_seats = available_seats - 1
WHERE concert_id = 'weeknd_tour'
AND available_seats >= 1;
-- Create the ticket record
INSERT INTO tickets (user_id, concert_id, seat_number, purchase_time)
VALUES ('user123', 'weeknd_tour', 'A15', NOW());
COMMIT;
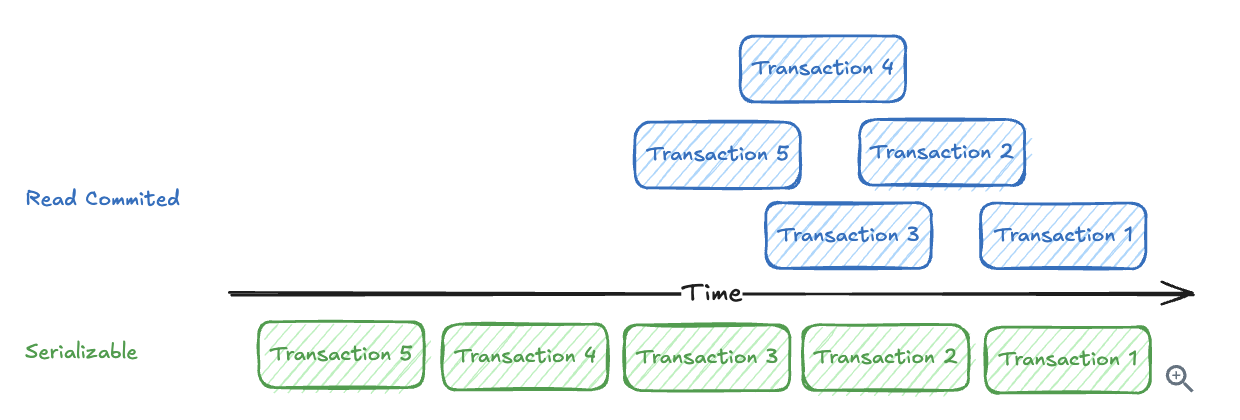
With SERIALIZABLE, the database automatically detects conflicts and aborts one transaction if they would interfere with each other.
10.2.5. Optimistic Concurrency Control
-- Alice reads: concert has 1 seat, version 42
-- Bob reads: concert has 1 seat, version 42
-- Alice tries to update first:
BEGIN TRANSACTION;
UPDATE concerts
SET available_seats = available_seats - 1, version = version + 1
WHERE concert_id = 'weeknd_tour'
AND version = 42; -- Expected version
INSERT INTO tickets (user_id, concert_id, seat_number, purchase_time)
VALUES ('alice', 'weeknd_tour', 'A15', NOW());
COMMIT;
-- Alice's update succeeds, seats = 0, version = 43
-- Bob tries to update:
BEGIN TRANSACTION;
UPDATE concerts
SET available_seats = available_seats - 1, version = version + 1
WHERE concert_id = 'weeknd_tour'
AND version = 42; -- Stale version!
-- Bob's update affects 0 rows - conflict detected, transaction rolls back
10.2.6. Multiple nodes
Two-phrase commit
- Step 1: Prepare, transaction stays open, waiting for coordinator’s decision
-- Database A during prepare phase
BEGIN TRANSACTION;
SELECT balance FROM accounts WHERE user_id = 'alice' FOR UPDATE;
-- Check if balance >= 100
UPDATE accounts SET balance = balance - 100 WHERE user_id = 'alice';
-- Transaction stays open, waiting for coordinator's decision
-- Database B during prepare phase
BEGIN TRANSACTION;
SELECT * FROM accounts WHERE user_id = 'bob' FOR UPDATE;
-- Verify account exists and is active
UPDATE accounts SET balance = balance + 100 WHERE user_id = 'bob';
-- Transaction stays open, waiting for coordinator's decision
- Step 2: Coordinator commit.
Distributed Locks
-
Redis with TTL
-
Database columns: Add status, expiration column.
-
ZooKeeper/etcd: Use coordination service to distribued lock. Both systems use consensus algorithms (Raft for etcd, ZAB for ZooKeeper) to maintain consistency across multiple nodes.
Saga Pattern
-
Step 1 - Debit $100 from Alice’s account in Database A, commit immediately
-
Step 2 - Credit $100 to Bob’s account in Database B, commit immediately
-
Step 3 - Send confirmation notifications and adjust rollup or commit.
![]()
Cons:
-
During saga execution, the system is temporarily inconsistent. After Step 1 completes, Alice’s account is debited but Bob’s account isn’t credited yet.
-
Other processes might see Alice’s balance as $100 lower during this window. If someone checks the total money in the system, it appears to have decreased temporarily.
When to use
Here are some bang on examples of when you might need to use contention patterns:
-
Multiple users competing for limited resources: concert tickets, auction bidding, flash sale inventory, or matching drivers with riders
-
Prevent double-booking or double-charging in scenarios: payment processing, seat reservations, or meeting room scheduling.
-
Ensure data consistency under high concurrency for operations: account balance updates, inventory management, or collaborative editing
-
Handle race conditions in distributed systems: where the same operation might happen simultaneously across multiple servers and where the outcome is sensitive to the order of operations.
When not to use:
- Read-heavy workloads: Handle write conflicts -> Impact read performance.
10.2.7. How do you prevent deadlocks with pessimistic locking?
-
Alice wants to transfer $100 to Bob, while Bob simultaneously wants to transfer $50 to Alice.
-
Transaction A locks Alice’s account first, then tries to lock Bob’s account.
-
Transaction B locks Bob’s account first, then tries to lock Alice’s account. Both transactions wait forever for the other to release their lock.
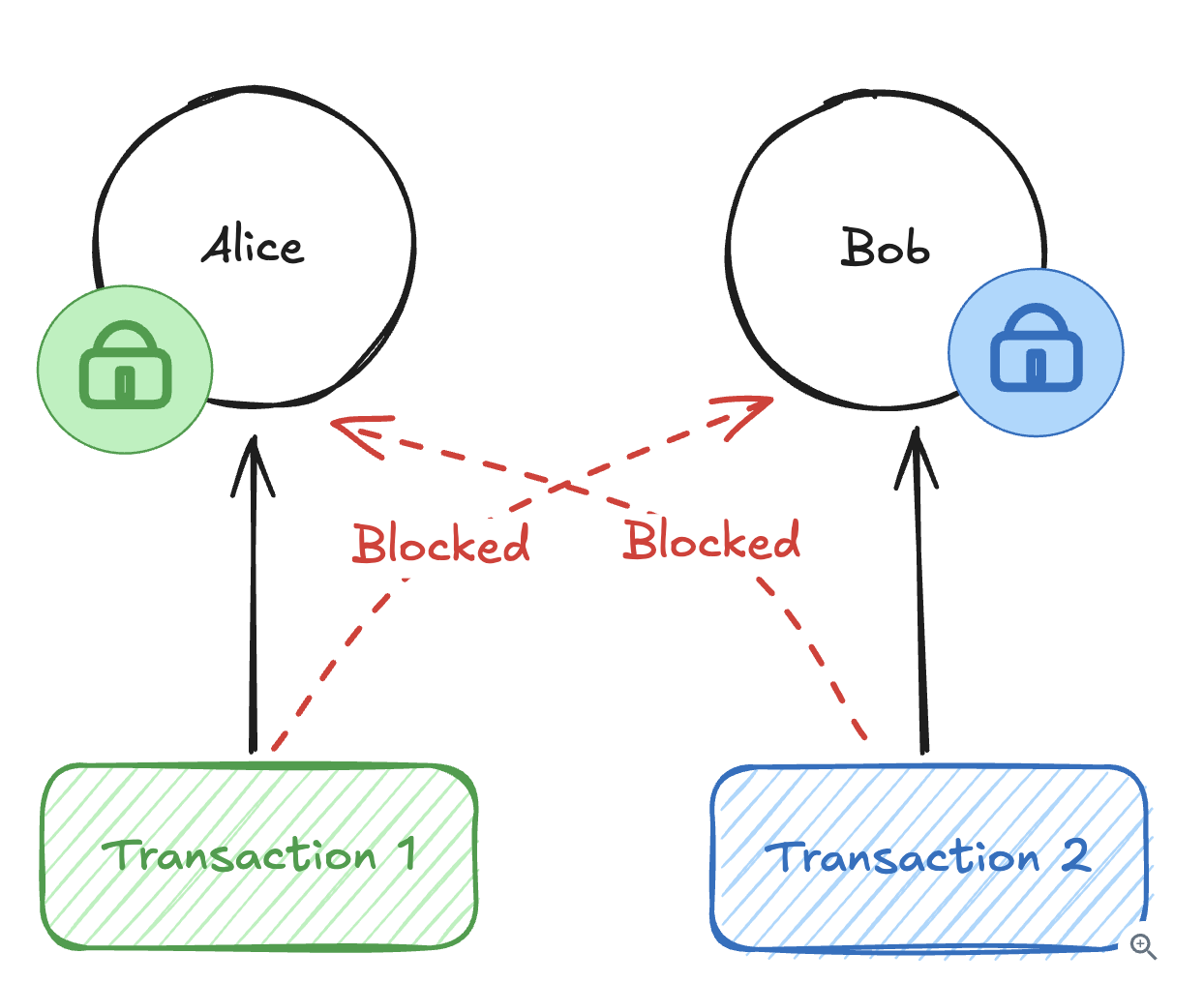
Solution:
-
Sort the resources you need to lock by some deterministic key like user ID, database primary key, or even memory address.
-
If you need to lock users 123 and 456, always lock 123 first even if your business logic processes 456 first.
-
Use database timeout for fallback => Most modern databases also have automatic deadlock detection that kills one transaction when cycles are detected.
10.2.8. What if your coordinator service crashes during a distributed transaction in 2-Phrase Commit ?
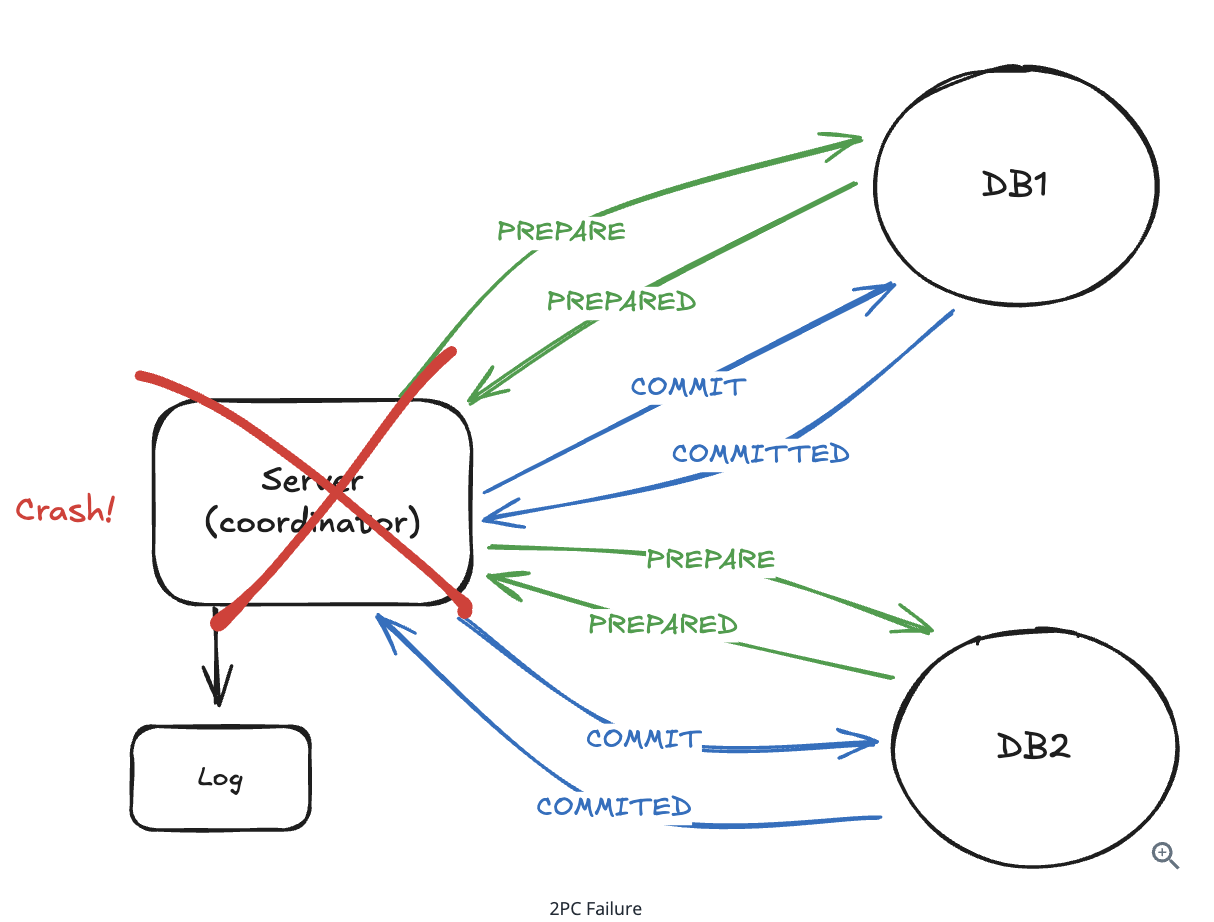
Production systems handle this with coordinator failover and transaction recovery
=> When a new coordinator starts up, it reads persistent logs to determine which transactions were in-flight and completes them.
10.2.9. How do you handle the ABA problem with optimistic concurrency
- Update the review_count for user know the problem.
-- Use review count as the "version" since it always increases
UPDATE restaurants
SET avg_rating = 4.1, review_count = review_count + 1
WHERE restaurant_id = 'pizza_palace'
AND review_count = 100; -- Expected current count
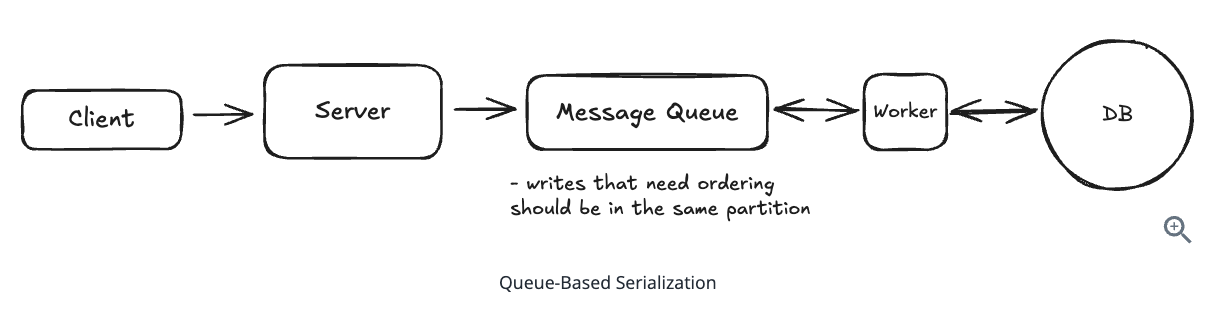
10.2.10. What about performance when everyone wants the same resource
10.2.11. What does the SQL ‘FOR UPDATE’ clause accomplish?
-
Exclusive lock: write.
-
Shared lock: read.
10.2.12. Pessimistic locking more efficient when conflicts are frequent.
- Optimistic concurrency control works best when conflicts are rare, multiple conflicts => multiple retries.
- Frequent conflicts mean lots of retries. making pessimistic locking more efficient.
10.2.13. In two-phase commit, transactions can stay open across network calls.
- This is actually a dangerous aspect of 2PC - open transactions hold locks during network coordination, which can cause problems if the coordinator crashes.
10.2.14. What is the standard solution for preventing deadlocks with pessimistic locking?
- Always acquire locks in a consistent order
10.2.15. Which approach works best for handling the ‘hot partition’ problem where everyone wants the same resource?
- Implement queue-based serialization
10.2.16. When should you choose pessimistic locking over optimistic concurrency control?
- Optimistic approaches that require rollback => Reduce the rollback rates.
10.2.17. What is the main advantage of keeping contended data in a single database?
- ACID transaction.
10.3. Multi-step Processes
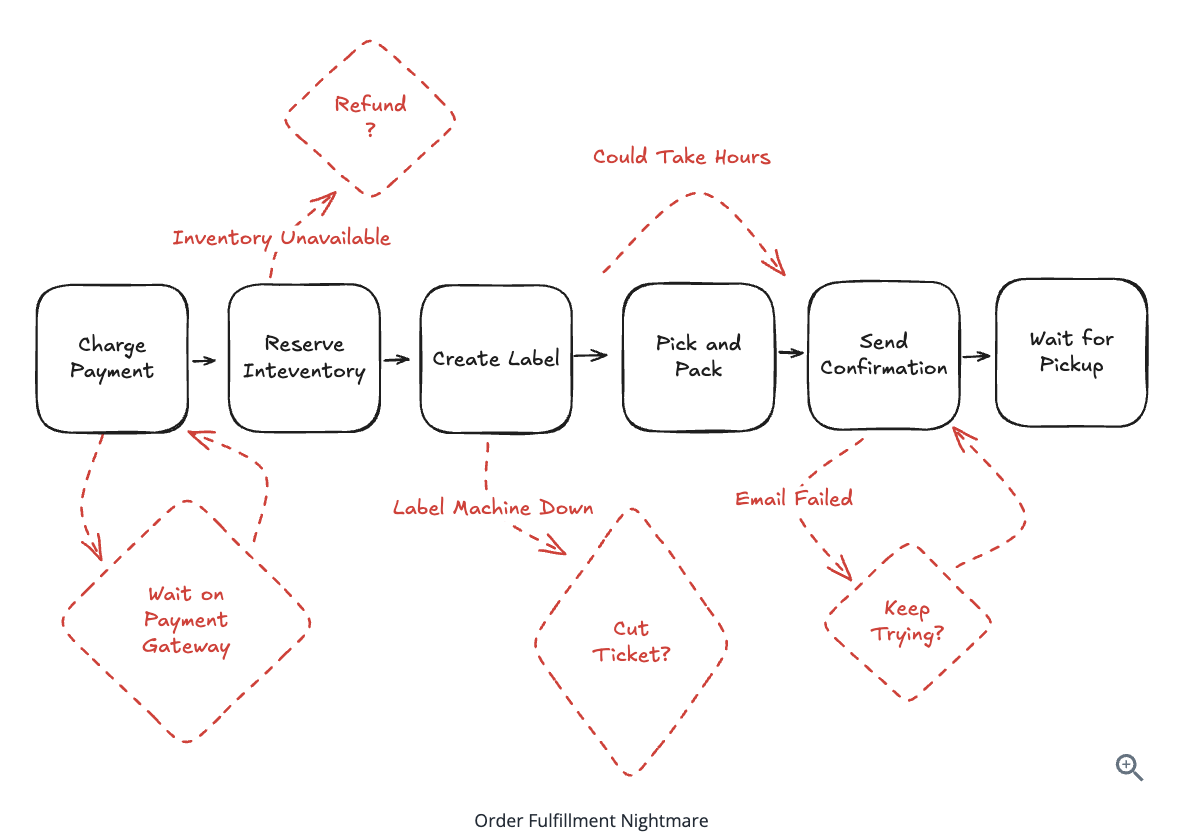
10.3.1. Order Messy State in real-world
10.3.2. Single Server Orchestration
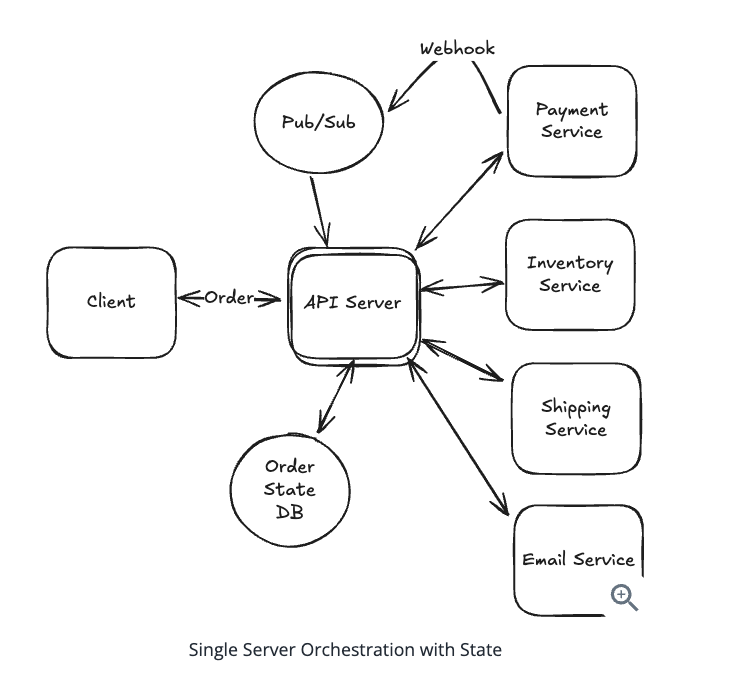
- Cons: It have to manually config event state and handle failure in each service.
10.3.3. Event Sourcing
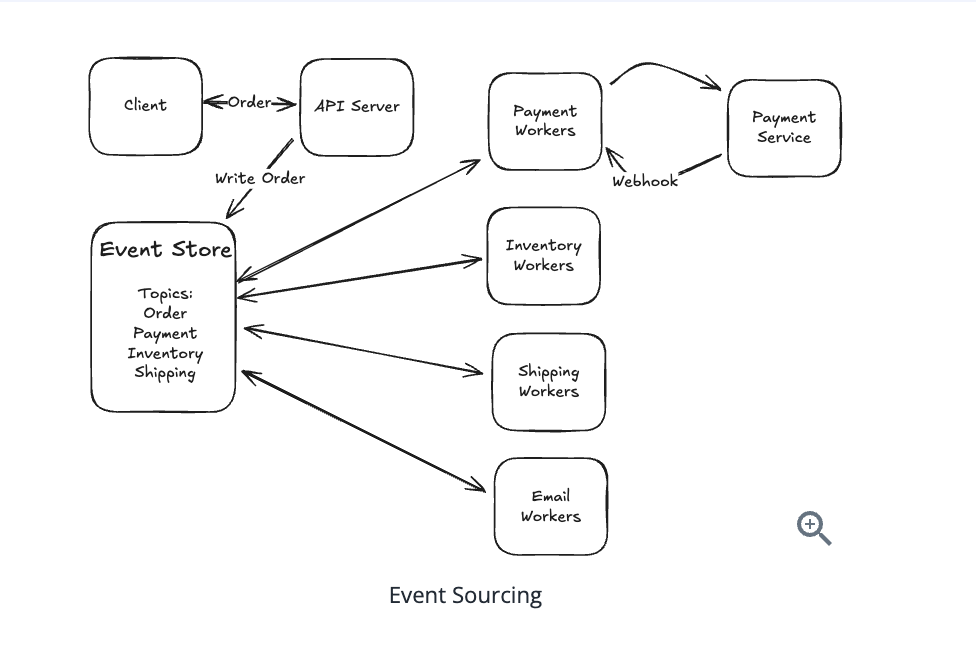
- Implement event sourcing patterns.
10.3.4. Workflow Management
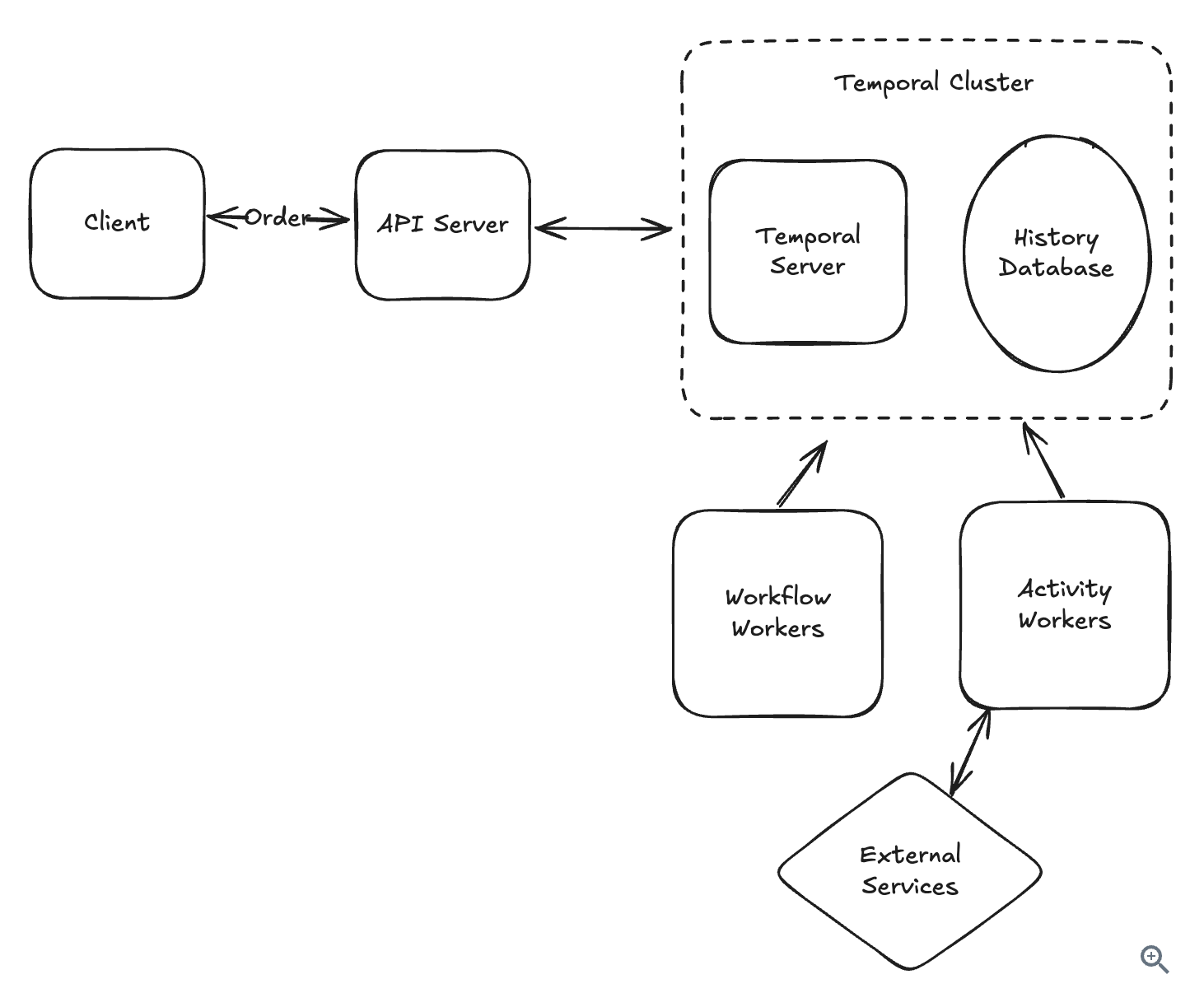
-
Manage state of transaction.
-
Query transaction by time.
Use for payment system, rail-hailing system.
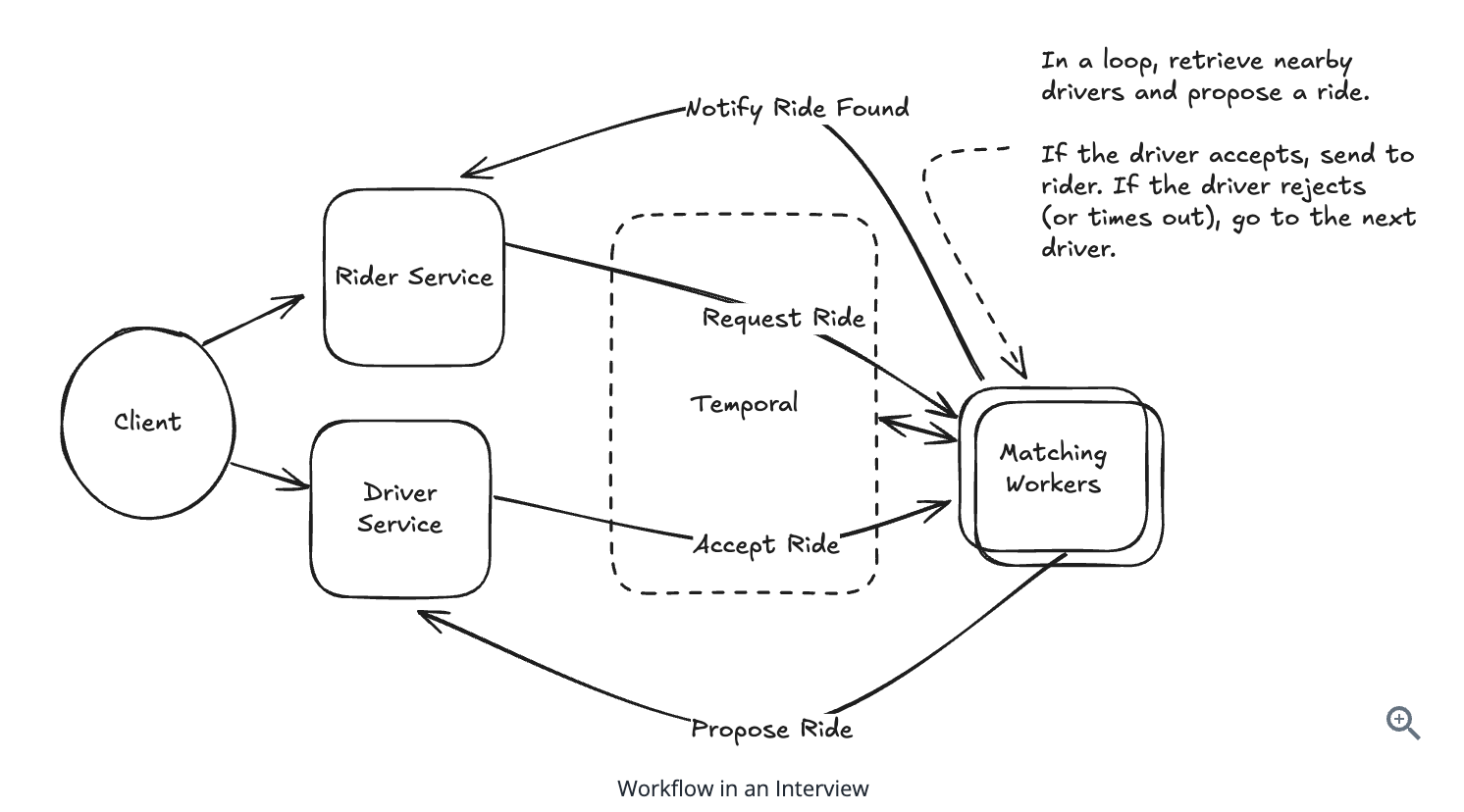
10.3.5. How will you handle updates to the workflow ?
-
Workflow Versioning.
-
Workflow Migrations
10.3.6. How do we keep the workflow state size in check
-
First, we should try to minimize the size of the activity input and results.
-
Second, we can keep our workflows lean by periodically recreating them. If you have a long-running workflow with lots of history, you can periodically recreate the workflow from the beginning, passing only the required inputs to the new workflow to keep going.
10.3.7. How do we deal with external events
-
External systems send signals through the workflow engine’s API. The workflow suspends efficiently - no polling, no resource consumption.
-
This pattern handles human tasks, webhook callbacks, and integration with external systems.
10.3.8. How can we ensure X step runs exactly once
-
Most workflow systems provide a way to ensure an activity runs exactly once … for a very specific definition of “run”.
-
The solution is to make the activity idempotent. This means that the activity can be called multiple times with the same inputs and get the same result.
10.3.9. What is the primary challenge that multi-step processes address in distributed systems?
- Coordinating multiple services reliably across failures and retries
10.3.10. What is the key principle behind event sourcing?
- Store a sequence of events that represent what happened
10.3.11. In event sourcing architecture, what triggers the next step in a workflow?
- Workers consuming events from the event store => change state.
10.3.12. Workflow systems eliminate the need for building custom infrastructure for state management and orchestration.
- Workflow systems and durable execution engines provide the benefits of event sourcing and state management => without requiring you to build the infrastructure yourself.
10.3.13. In Temporal workflows, what is the key requirement for workflows vs activities?
-
Workflows must be deterministic (same inputs and history produce same decisions) to enable replay-based recovery.
-
Activities must be idempotent (can be called multiple times with same result) but won’t be retried once they succeed.
10.3.14. Temporal uses a history database to remember activity results during workflow replay.
-
Each activity run is recorded in a history database.
-
If a workflow runner crashes, another runner can replay the workflow and use the history to remember what happened with each activity invocation.
10.3.15. How do managed workflow systems like AWS Step Functions differ from durable execution engines like Temporal?
- They use declarative definitions (JSON/YAML) instead of code
10.3.16. How do workflow systems handle external events like waiting for user input?
- Workflows use signals to wait for external events efficiently.
10.3.17. Apache Airflow is better suited for event-driven, long-running user-facing workflows than scheduled batch workflows
- Apache Airflow excels at scheduled batch workflows like ETL and data pipelines, do not use for user-facing workflows.
10.4. Scaling Reads
10.4.1. Problem
Consider an Instagram feed. When you open the app, you’re immediately hit with dozens of photos, each requiring multiple database queries to fetch the image metadata, user information, like counts, and comment previews. That’s potentially 100+ read operations just to load your feed.
Meanwhile, you might only post one photo per day - a single write operation.
=> It’s not code problem, it’s physics problems about CPU, data, and disk I/O is bounded
10.4.2. Solution
-
Optimize read performance within your database
-
Scale your database horizontally
-
Add external caching layers
10.4.3. Optimize read performance within your database
-
Indexing.
-
Hardware Upgrades.
-
Denormalization Strategies.
-
Materialized views: Precomputing expensive aggregations
10.4.4. Scale your database horizontally
-
Read Replicas.
-
Database Sharding
-
Geographic sharding.
10.4.5. Add External Caching Layers
-
Application-Level Caching: Redis, Memcache.
-
CDN.
10.4.6. Do not apply for write-heavy system
10.4.7. What happens when your queries start taking longer as your dataset grows ?
-
Add index.
-
Using EXPLAIN to check.
10.4.8. How do you handle millions of concurrent reads for the same cached data - Hotpots Problem ?
-
Request coalescing: Query data for first requests and add to memcache.
-
Distributed load: feed:taylor-swift:1, feed:taylor-swift:2 => in multiple reading shards.
10.4.9. What happens when multiple requests try to rebuild an expired cache entry simultaneously?
- When that hour passes and the entry expires, all 100,000 requests suddenly see a cache miss in the same instant.
=> Your database, sized to handle maybe 1,000 queries per second during normal cache misses, suddenly gets hit with 100,000 identical queries.
-
Solution:
-
Distributed Cache: Only first requests hit the database => Lock other requests, consider it will peak the server.
-
Stale-while-revalidate: This refreshes cache entries before they expire, but not all at once.
-
10.4.10. How do you handle cache invalidation when data updates need to be immediately visible?
-
Write-through caching: Change the value of cache when updating.
-
Delete item in cache, after a time => query db and update cache.
-
CDN Caching: More complexity, using TTLs in edge caching.
10.4.11. Modern hardware and database engines handle write well-designed multiple indexes efficiently.
10.4.12. What is the main trade-off when using denormalization for read scaling?
-
Increased storage for faster reads
-
Denormalization trades storage space for read speed by storing redundant data to avoid expensive joins.
10.4.13. What is the key challenge with read replicas in leader-follower replication?
- Replication lag causing potentially stale reads
10.4.14. Synchronous replication ensures consistency but introduces latency, while asynchronous replication is faster but potentially serves stale data.
- Yes
10.4.15. When does functional sharding make sense for read scaling?
- When different business domains have different access patterns
10.4.16. Why do most applications benefit significantly from caching?
- Access patterns are highly skewed - popular content gets requested repeatedly
10.4.17. CDNs only make sense for data accessed by multiple users.
10.4.18. How should cache TTL be determined?
- Based on non-functional requirements, such as: search results should be no more than 30 seconds stale
10.4.19. What is the key benefit of request coalescing for handling hot keys?
- Request coalescing ensures that even if millions of users want the same data simultaneously, your backend only receives N requests - one per application server doing the coalescing.
10.4.20. What is the ‘stale-while-revalidate’ pattern for cache stampede prevention?
- Serving old data while refreshing in the background
10.4.21. Cache versioning avoids invalidation complexity by changing cache keys when data updates, making old entries naturally unreachable.
- Yes
10.5. Scaling Writes
10.5.1. Problem
- Bursty, high-throughput writes with lots of contention is a problem.
10.5.2. Solution
-
Vertical Scaling and Write Optimization
-
Sharding and Partitioning
-
Handling Bursts with Queues and Load Shedding
-
Batching and Hierarchical Aggregation
10.5.3. Vertical Scaling and Database types (Different Write Strategy)
-
Vertical Scaling
-
Database Choices: Cassandra write-heavy database, handle 10k rps rather than 1000 rps of DBMS.
-
Cassandra achieves superior write throughput through its append-only commit log architecture, instead of updating data in place.
Database types:
-
Time-series databases
-
Log-structured databases
-
Column stores
Others:
-
Disable expensive features like foreign key constraints, complex triggers, or full-text search indexing during high-write periods
-
Tune write-ahead logging - databases like PostgreSQL can batch multiple transactions before flushing to disk
-
Reduce index overhead - fewer indexes mean faster writes, though you’ll pay for it on reads
10.5.4. Why we do not use Horizontal Scaling for write-heavy database
-
Writes need to be consistent across all nodes.
-
In a distributed setup, synchronizing writes across nodes introduces latency and increases the chance of conflicts.
-
Horizontal Scaling for read-heavy.
10.5.5. Sharding and Partitioning
Horizontal Sharding
- Selecting a Good Partitioning Key
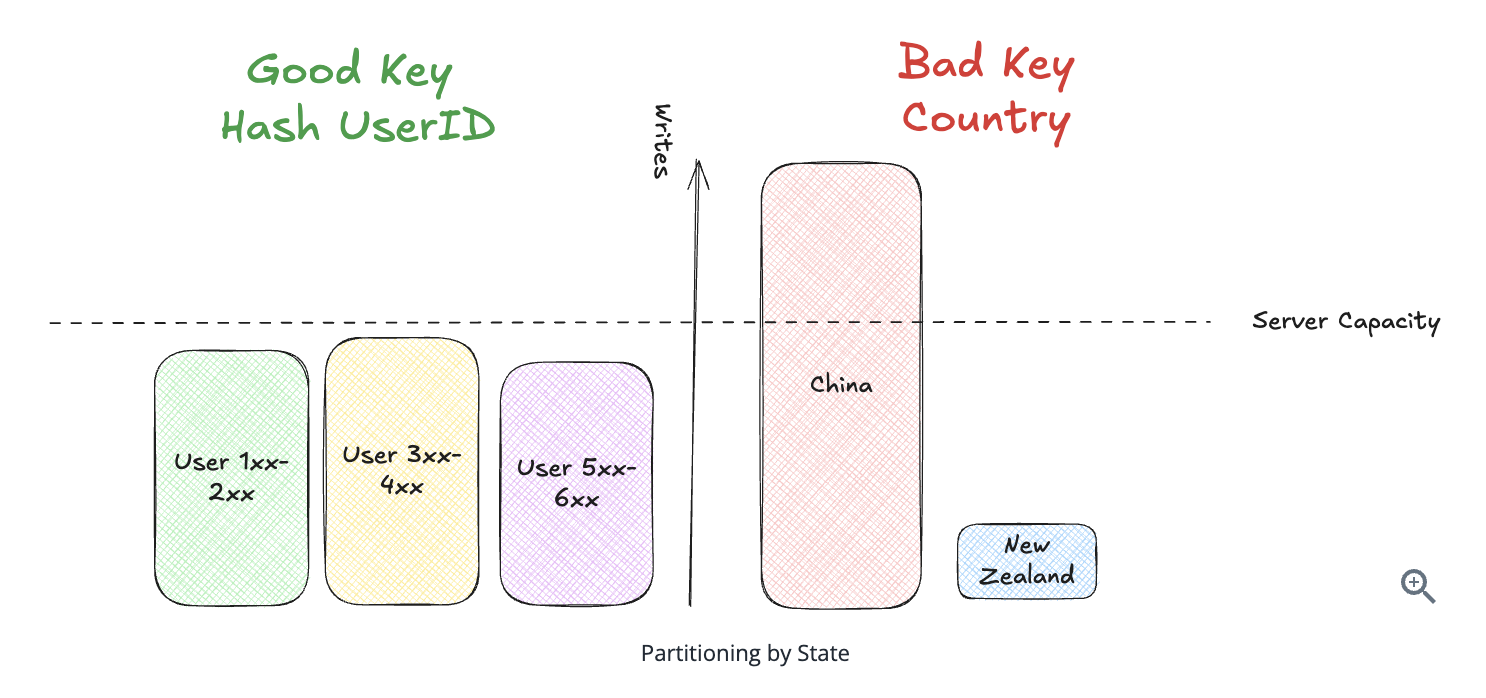
Vertical Sharding
- Split by table view, some table heavy-write, some table heavy-read, other append-once, time-series
For Post content we’ll use traditional B-tree indexes and is optimized for read performance For Post metrics we might use in-memory storage or specialized counters for high-frequency updates For Post analytics we can use time-series optimized storage or database with column-oriented compression
-- Core post content (write-once, read-many)
TABLE post_content (
post_id BIGINT PRIMARY KEY,
user_id BIGINT,
content TEXT,
media_urls TEXT[],
created_at TIMESTAMP
);
-- Engagement metrics (high-frequency writes)
TABLE post_metrics (
post_id BIGINT PRIMARY KEY,
like_count INTEGER DEFAULT 0,
comment_count INTEGER DEFAULT 0,
share_count INTEGER DEFAULT 0,
view_count INTEGER DEFAULT 0,
last_updated TIMESTAMP
);
-- Analytics data (append-only, time-series)
TABLE post_analytics (
post_id BIGINT,
event_type VARCHAR(50),
timestamp TIMESTAMP,
user_id BIGINT,
metadata JSONB
);
-
For Post content: we’ll use traditional B-tree indexes and is optimized for read performance
-
For Post metrics: we might use in-memory storage or specialized counters for high-frequency updates
-
For Post analytics: we can use time-series optimized storage or database with column-oriented compression
10.5.6. Handling Bursts with Queues and Load Shedding
Write Queues for Burst Handling
- This approach provides a few benefits, but the most important is burst absorption: the queue acts as a buffer, smoothing out traffic spikes.
Load Shedding Strategies
-
When your system is overwhelmed, you need to decide which writes to accept and which to reject.
-
This is called load shedding, and it’s better than letting everything fail.
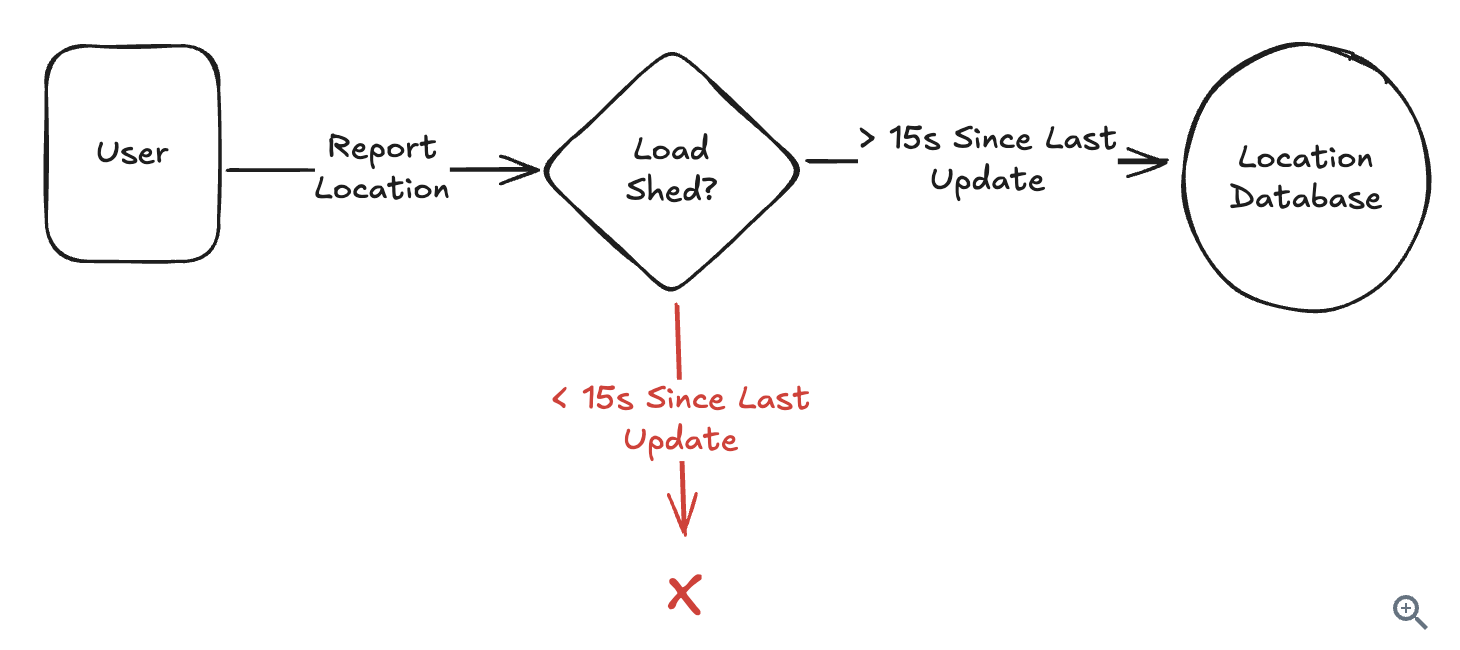
10.5.7. Batching and Hierarchical Aggregation
- Batching and preprocessing immediately.
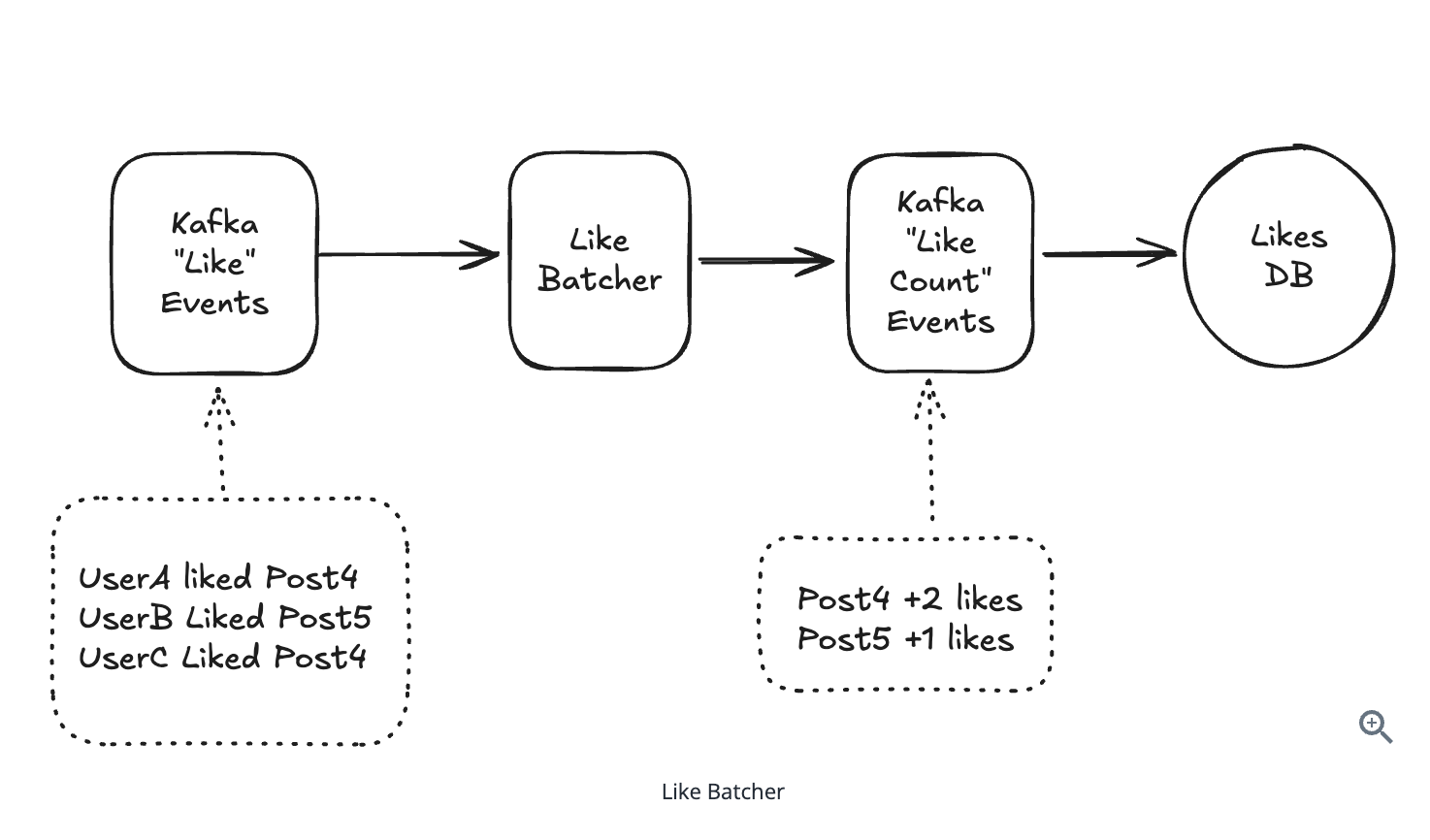
10.5.8. Streaming Problems (Write Heavy)
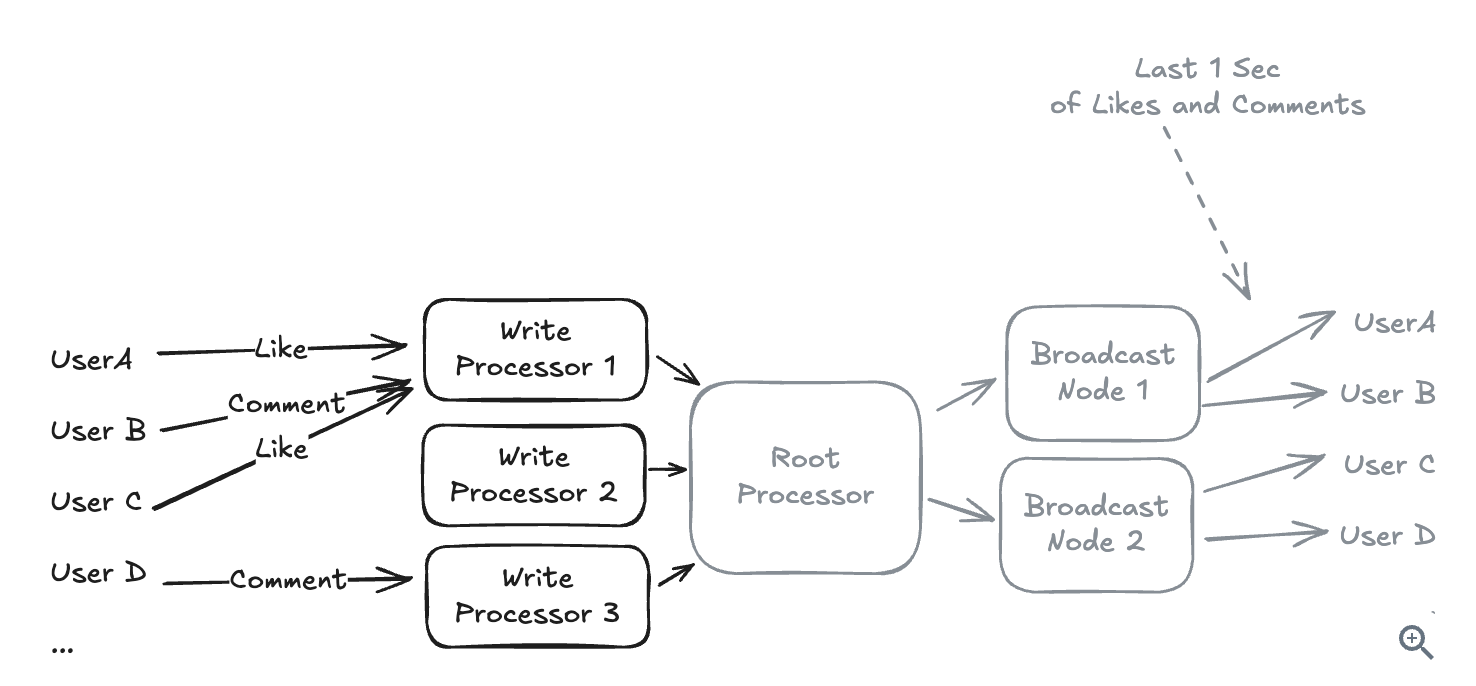
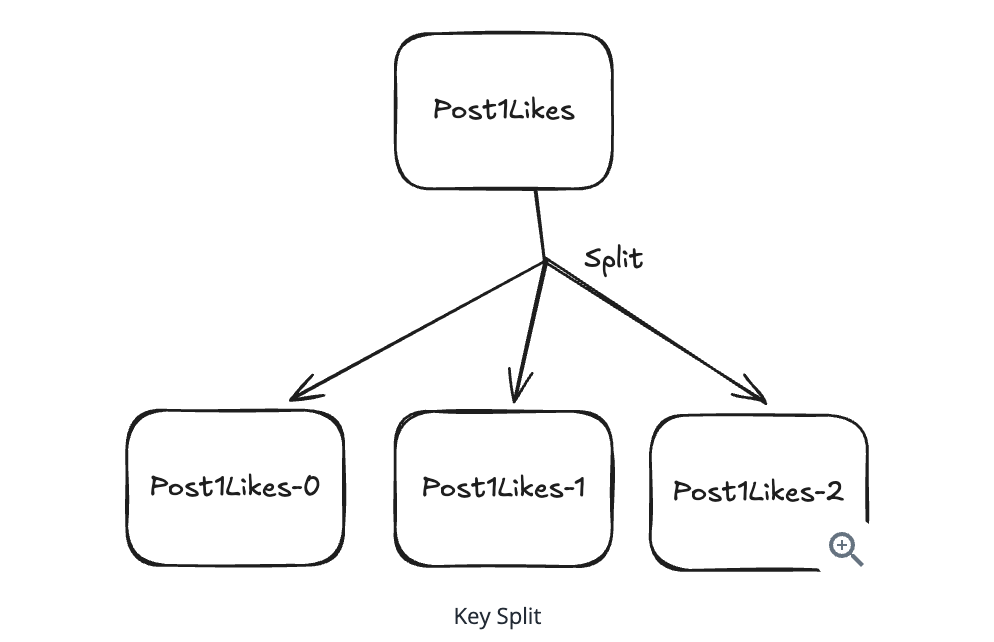
10.5.9. What happens when you have a hot key that’s too popular for even a single shard
- Split All Keys to multiple shards
10.5.10. How do you handle resharding when you need to add more shards?
-
Take the system offline, rehash all data, and move it to new shards.
-
Production systems use gradual migration which targets writes to both location background => gradually migration.
10.5.11. When choosing a partitioning key for sharding, what should be the primary goal?
-
Balancing is good.
-
Do not any sharding exceed the average performace.
10.5.12. What is the main difference between horizontal and vertical partitioning?
-
Both split to multiple servers
-
Horizontal splits rows, vertical splits columns
10.5.13. Write queues are always the best solution for handling traffic bursts.
- Write timestamp client, because queue my delay.
10.5.14. When might load shedding be preferable to queuing for handling write bursts?
-
When writes are frequently updated (like location updates)
-
Have multiple event, lost some events is not considerable.
10.5.15. Gracefully shutdown
- Handle all batching requests before shut down.
10.5.16. What is the primary purpose of hierarchical aggregation in write scaling?
-
Hierarchical aggregation processes data in stages, reducing volume at each step.
-
It’s used for high-volume data where you need aggregated views rather than individual events.
10.5.17. When resharding a database, the dual-write phase ensures no data is lost during migration.
- During resharding, you write to both old and new shards but read with preference for the new shard.
10.5.18. Splitting hot keys dynamically requires both readers and writers to agree on which keys are hot.
- If writers spread writes across multiple sub-keys but readers don’t check all sub-keys, you have inconsistent data.
10.5.19 (Hay). What is the fundamental principle behind all write scaling strategies?
- Reduce throughput per component
10.5.20. LSM Tree (Log-Structured Merge-tree)
– Built for heavy write volume.
- Appends in memory then merges on disk. Point reads cost extra hops.
10.6. Handling Large Blobs
10.6.1. Pre-signed url:
- Use for clients temporary, scoped credentials to interact directly with storage.
10.6.2. Simple Direct Upload
-
content-length-range: Set min/max file sizes to prevent someone uploading 10GB when you expect 10MB
-
content-type: Ensure that profile picture endpoint only accepts images, not videos
10.6.3. Simple Direct Download
-
Blob storage signatures (like S3 presigned URLs): are validated by the storage service using your cloud credentials. The storage service has your secret key and can verify that you generated the signature.
-
CDN signatures (like CloudFront signed URLs): are validated by the CDN edge servers using public/private key cryptography.
10.6.4. Resumable Uploads for Large Files
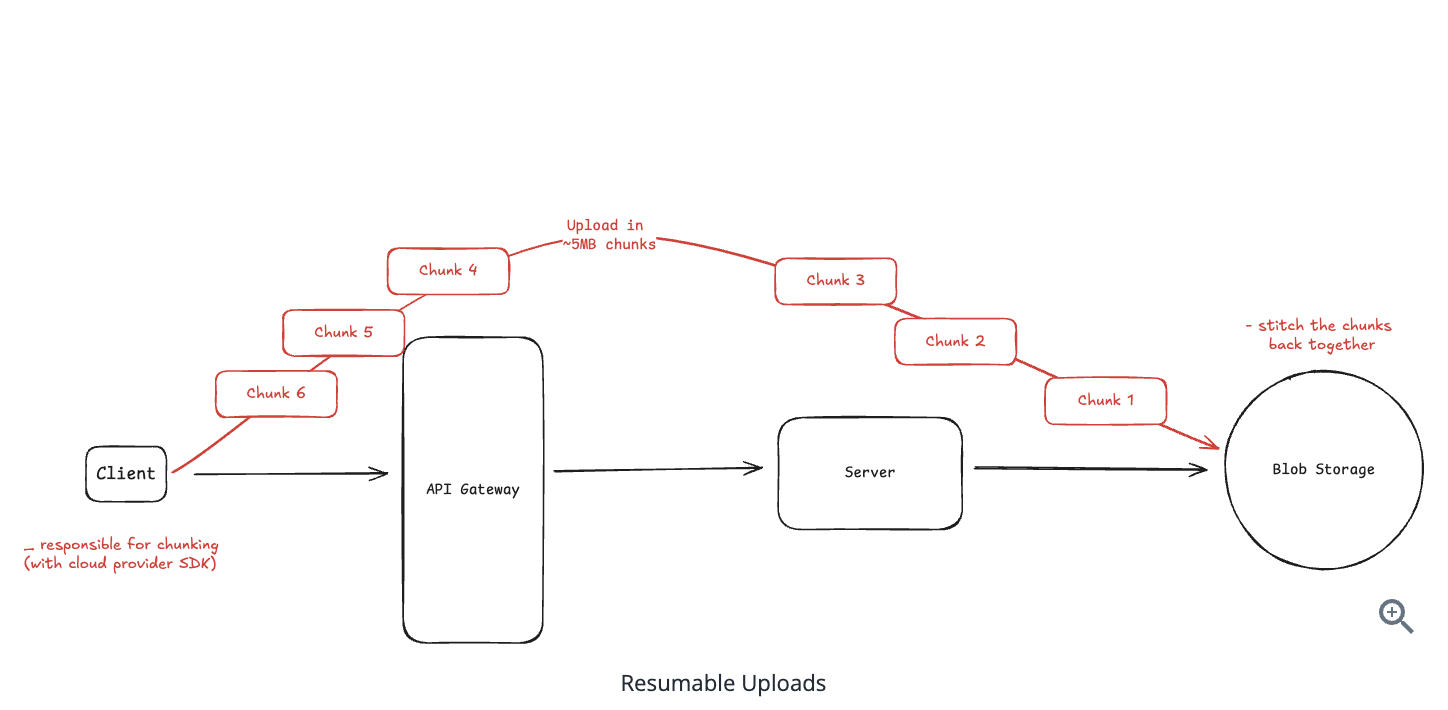
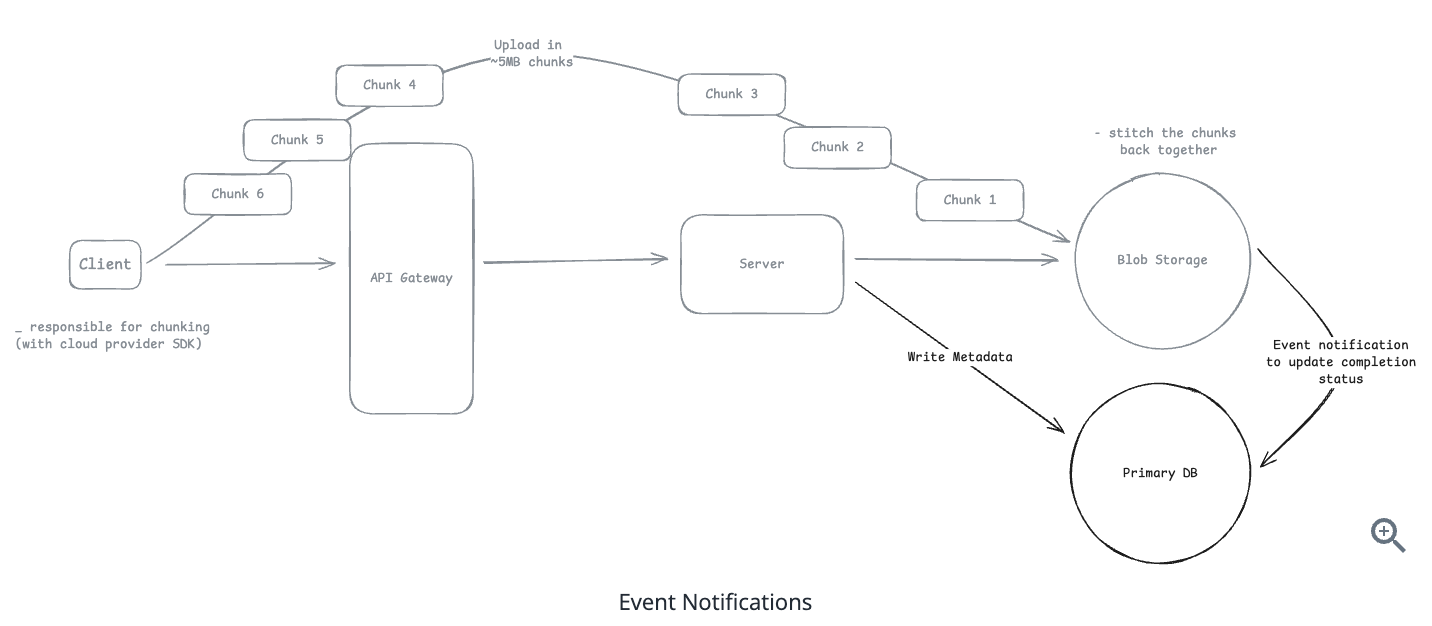
10.6.5. State Synchronization Challenges
Use database to track it
CREATE TABLE files (
id UUID PRIMARY KEY,
user_id UUID NOT NULL,
filename VARCHAR(255),
size_bytes BIGINT,
content_type VARCHAR(100),
storage_key VARCHAR(500), -- s3://bucket/user123/files/abc-123.pdf
status VARCHAR(50), -- 'pending', 'uploading', 'completed', 'failed'
created_at TIMESTAMP,
updated_at TIMESTAMP
);
-
Race conditions: The database might show ‘completed’ before the file actually exists in storage
-
Orphaned files: The client might crash after uploading but before notifying you, leaving files in storage with no database record
-
Malicious clients: Users could mark uploads as complete without actually uploading anything
-
Network failures: The completion notification might fail to reach your servers
10.6.6. What if the upload fails at 99%?
-
When files exceed 100MB, you should use chunked uploads - S3 multipart uploads (5MB+ parts), GCS resumable uploads (any chunk size), or Azure block blobs (4MB+ blocks).
-
When a connection drops, the client doesn’t start over. Instead, it queries which parts already uploaded; using ListParts in S3, checking the resumable session status in GCS, or listing committed blocks in Azure.
-
If parts 1-19 succeeded but part 20 failed, the client resumes from part 20.
10.6.7. How do you prevent abuse
-
Run virus scans, content validation, and any other checks before moving files to the public bucket.
-
Only after these checks pass do you move the file to its final location and update the database status to “available.”
10.6.8. How do you handle metadata
-
The storage key is your connection point. Use a consistent pattern like uploads/{user_id}/{timestamp}/{uuid} that includes useful info but prevents collisions.
-
Add metadata with: who uploaded it, what it’s for, processing instructions
-
Generate the hash key.
10.6.9. How do you ensure downloads are fast
-
CDNs solve the geography problem by caching content at edge locations worldwide.
-
The solution is range requests - HTTP’s ability to download specific byte ranges of a file bytes=0-10485759 (first 10MB)
GET /large-file.zip
Range: bytes=0-10485759 (first 10MB)
-
Resumes download feature: Modern browsers and download managers handle this automatically if your storage and CDN support range requests
-
The pragmatic approach: serve everything through CDN with appropriate cache headers. Ensure range requests work for large files. Let the CDN and browser handle the optimization.
10.6.10. What is the primary problem with proxying large files through application servers?
- Application servers become bottlenecks with no added value
10.6.11. Generate presigned urls
- Presigned urls are generated entirely in your application’s memory using your cloud credentials - no network call to storage is needed.
10.6.12. What should you include in presigned URLs to prevent abuse?
- Content-length-range and content-type restrictions
10.6.13. With chunked uploads, the storage service tracks which parts uploaded successfully.
- The storage service maintains state about completed parts using session IDs, allowing clients to query which parts need to be retried.
10.6.14. What is the main challenge with state synchronization in direct uploads?
- Since uploads bypass your servers, your database metadata can become out of sync with what actually exists in blob storage, requiring event notifications and reconciliation.
10.6.15. How do cloud storage services help with state synchronization?
- Storage services publish events (S3 to SNS/SQS, GCS to Pub/Sub) when files are uploaded, letting your system update database status reliably.
10.6.16. CDN signatures are validated by the storage service using public/private key cryptography
10.6.17. At what file size should you typically consider using direct uploads instead of proxying through servers?
-
Around 100MB
-
Direct Upload: Return presigned url for client, client upload to S3.
-
Proxy through server: Upload -> Server -> S3.
10.6.18. After multipart upload completion, object storage combine all the multi-parts to a file
- Once multipart upload completes, the storage service combines all parts into a single object - the individual chunks no longer exist from the storage perspective.
10.6.19 (Hay). When should you NOT use direct uploads in a system design?
-
Need for real-time content validation during upload
-
You can control direct upload from client
10.6.20. Range requests enable resumable downloads for large files.
- Yes
10.7. Managing Long Running Tasks (Async Worker)
10.7.1. Problem
-
When user generate the PDF report => The whole process takes at least 45 seconds => blocking in the UI.
-
With synchronous processing, the user’s browser sits waiting for 45 seconds. Most web servers and load balancers enforce timeout limits around 30-60 seconds, so the request might not even complete.
10.7.2. Solution
- Split it to 2 parts: We’re generating your report + We’ll notify you when it’s ready
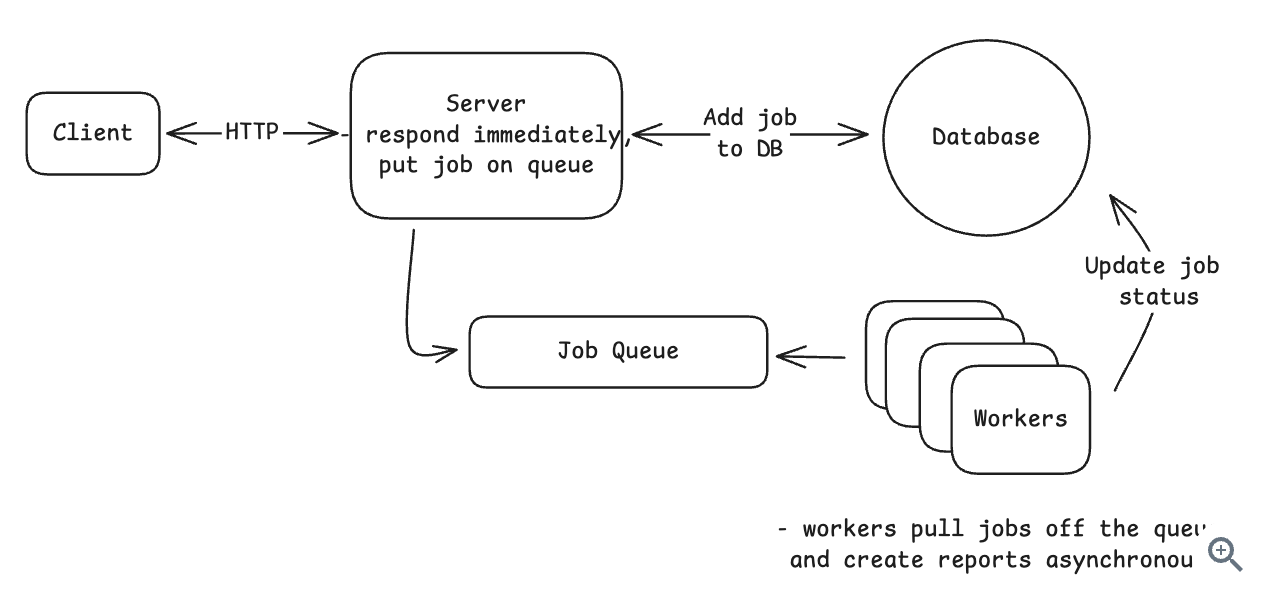
10.7.3. When to use
- The moment you hear “video transcoding”, “image processing”, “PDF generation”, “sending bulk emails”, or “data exports” that’s your cue.
10.7.4. Handling Failures
-
What happens if the worker crashes while working the job? => The job will be retried by another worker.
-
Typically, you’ll have a heartbeat mechanism that periodically checks in with the queue to let it know that the worker is still alive.
-
The interval of the heartbeat is a key design decision.
Message queue:
-
SQS: visibility timeout.
-
RabbitMQ: heartbeat interval.
-
Kafka: session timeout.
10.7.5. Handling Repeated Failures
Question: What happens if a job keeps failing? Maybe there’s a bug in your code or bad input data that crashes the worker every time.
Solution: Add to dead letter queue
Message queue:
-
SQS: redrive policy.
-
RabbitMQ: dead letter exchange.
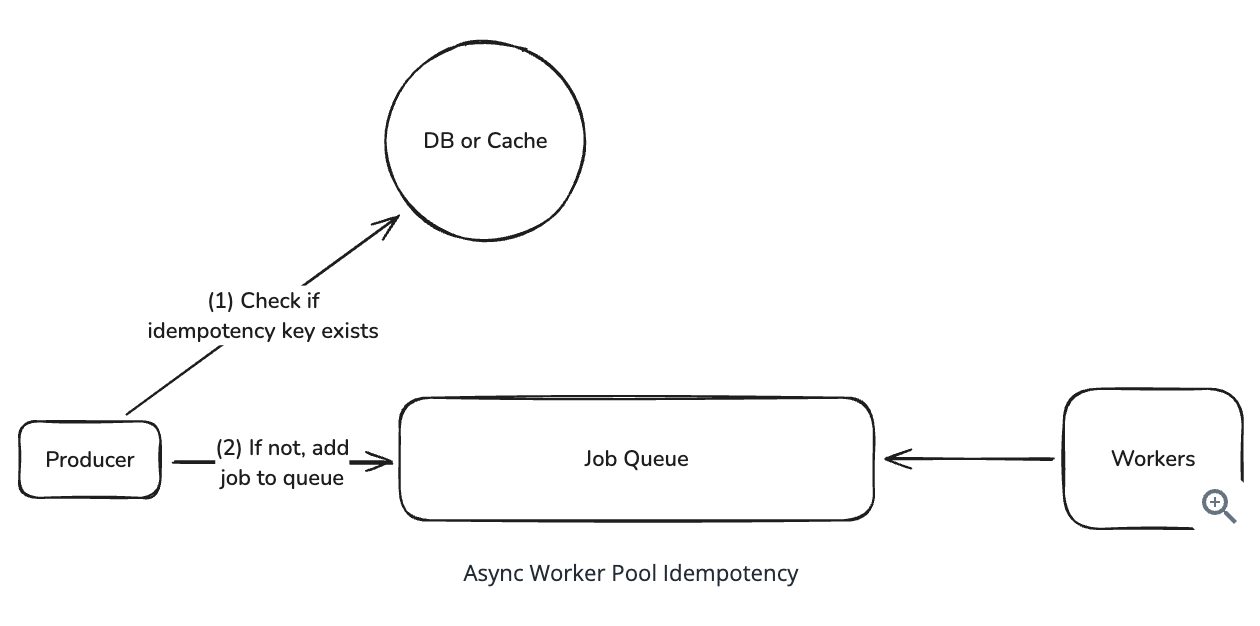
10.7.6. Preventing Duplicate Work
Question: A user gets impatient and clicks ‘Generate Report’ three times. Now you have three identical jobs in the queue. How do you prevent doing the same work multiple times ?
Solution: Use idempotency keys (hash the deterministic IDs from input data)
10.7.7. Managing Queue Backpressure
Question: It’s Black Friday and suddenly you’re getting 10x more jobs than usual. Your workers can’t keep up. The queue grows to millions of pending jobs. What do you do?
- When queue is full => blocking the tasks.
Solution: Use backpressure => Add the depth limits and reject new jobs when the queue are full => “System Busy” response, rather than accepting work that you can’t handle.
10.7.8. Handling Mixed Workloads
Question: Some of your PDF reports take 5 seconds, but end-of-year reports take 5 hours. They’re all in the same queue. What problems does this cause?
Problem:
- Long jobs block short ones. A user requesting a simple report waits hours behind someone’s massive year-end export
Solution:
- Split multiple queues due to job type and expected duration
queues:
fast:
max_duration: 60s
worker_count: 50
instance_type: t3.medium
slow:
max_duration: 6h
worker_count: 10
instance_type: c5.xlarge
10.7.9. Orchestrating Job Dependencies
Question: What if generating a report requires three steps: fetch data, generate PDF, then email it. How do you handle jobs that depend on other jobs
Solution: Using workflow machine.
{
"workflow_id": "report_123",
"step": "generate_pdf",
"previous_steps": ["fetch_data"],
"context": {
"user_id": 456,
"data_s3_url": "s3://bucket/data.json"
}
}
10.7.10. In the async worker pattern, the web server’s job is to perform the actual heavy processing work.
- Web Servers is only receive the jobs.
10.7.11. Redis with Bull/BullMQ
- It is in-memory queue, allow: delayed, stalled, completed, failed,…
10.7.12. What is the main advantage of separating web servers from worker processes?
- Independent scaling based on specific needs
10.7.13. Serverless functions are ideal for processing jobs that take several hours to complete.
- No, because serverless functions have execution time limits (typically 15 minutes)
10.7.14. What is a Dead Letter Queue (DLQ) used for?
- A DLQ isolates jobs that fail repeatedly (after 3-5 retries) to prevent poison messages => retry 3 - 5 failed to DLQ.
10.7.15. How do you prevent duplicate work when a user clicks ‘Generate Report’ multiple times?
- Prevent duplicates => Use Idempotency keys
10.7.16. When implementing backpressure, you should reject new jobs when the queue depth exceeds a threshold.
- Yes
10.7.17. What metric should you monitor for autoscaling workers?
- Queue depth is the key metric for worker autoscaling - by the time CPU is high, your queue is already backed up
10.7.18. How should you handle mixed workloads where some jobs take 5 seconds and others take 5 hours?
- Separate queues by job type or duration
10.7.19. For complex workflows with job dependencies, what should you consider using?
- Workflow orchestrators like AWS Step Functions or Temporal
10.7.20. When should you proactively suggest async workers in a system design interview?
- Operations that take seconds to minutes (video transcoding, image processing, PDF generation, bulk emails) are clear signals for async processing.
10.7.21. The async worker pattern introduces eventual consistency since work isn’t done when the API returns.
- This is a key tradeoff - users might see stale data until background processing completes, but they get immediate response and better overall system performance.
10.7.22. What is the main benefit of using Kafka for job queues compared to Redis?
- Kafka’s append-only log allows message replay, fan-out to multiple consumers, and maintains strict ordering
=> Kafka strict ordering guarantees.
11. Advanced Data Structure
11.1. Bloom Filter (Yes or No)
- Tests if an element is possibly in a set
11.2. Count-Min Sketch (Frequency)
- Approximates frequency counts of items
11.3. Hyperloglog (Number of unique item)
- Estimates the cardinality (number of unique items)
12. Payment System
12.1. Functional Requirements:
-
Merchants should be able to initiate payment requests (charge a customer for a specific amount).
-
Users should be able to pay for products with credit/debit cards.
-
Merchants should be able to view status updates for payments (e.g., pending, success, failed).
12.2. Non-funtional requirements

12.3. Entities:

12.4. API Design:
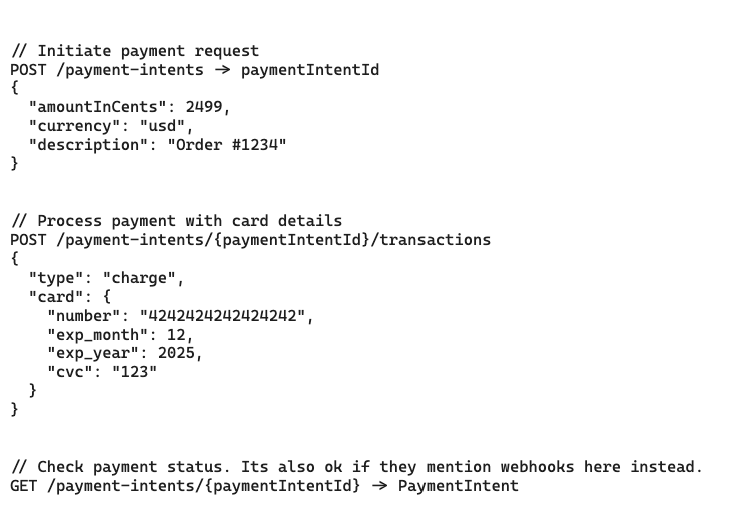
12.5. How will merchants be able to initiate payment requests?
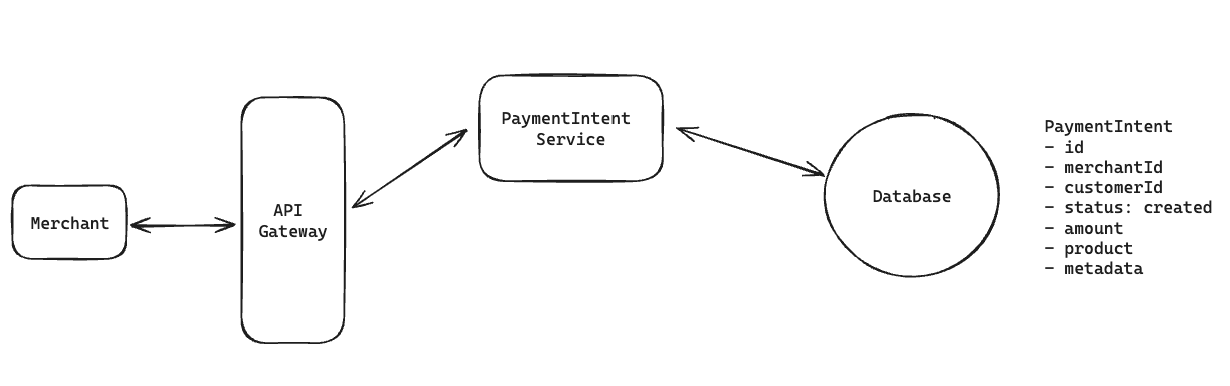
12.6. How will users be able to pay for products with credit/debit cards?
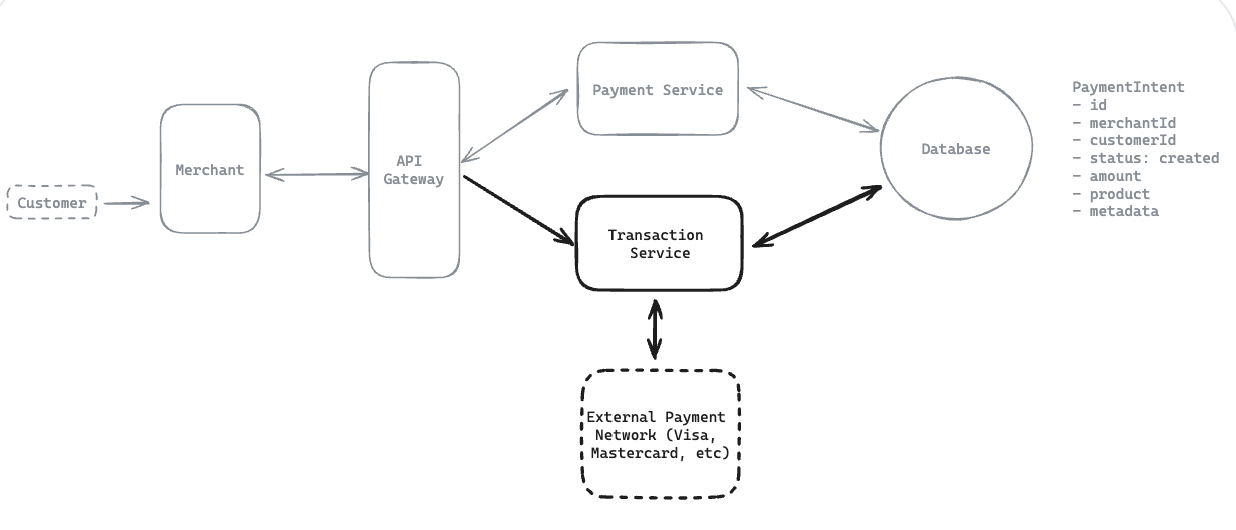
12.7. How will merchants be able to view status updates for payments?
Notes: Client -> API Gateway -> Service -> Database (Every functional requirements => can be implement with this patterns)
- Implement query transaction API, with status: ‘created’, ‘processing’, ‘succeeded’, or ‘failed’
12.8. How would you ensure secure authentication for merchants using the payment system?
Notes: Client -> API Gateway -> Service -> Database (Every functional requirements => can be implement with this patterns)
-
To ensure secure merchant authentication, we’ll implement API key management with request signing.
-
Each merchant gets both a public API key for identification and a private secret key for generating time-bound signatures.
=> Merchant use private key to hash the requests, public key Zalopay to encrypt it => Zalopay engine use private key to decode the payload + merchant key to resolve it.
12.9. How would you secure customer credit card information while in transit?
Notes: Client -> API Gateway -> Service -> Database (Every functional requirements => can be implement with this patterns)
-
Our JavaScript SDK immediately encrypts card details using Zalopay public key before data leaves the customer’s browser.
-
After processing, only store tokens as payment methods, never the card details => Merchant use the token for next payment.
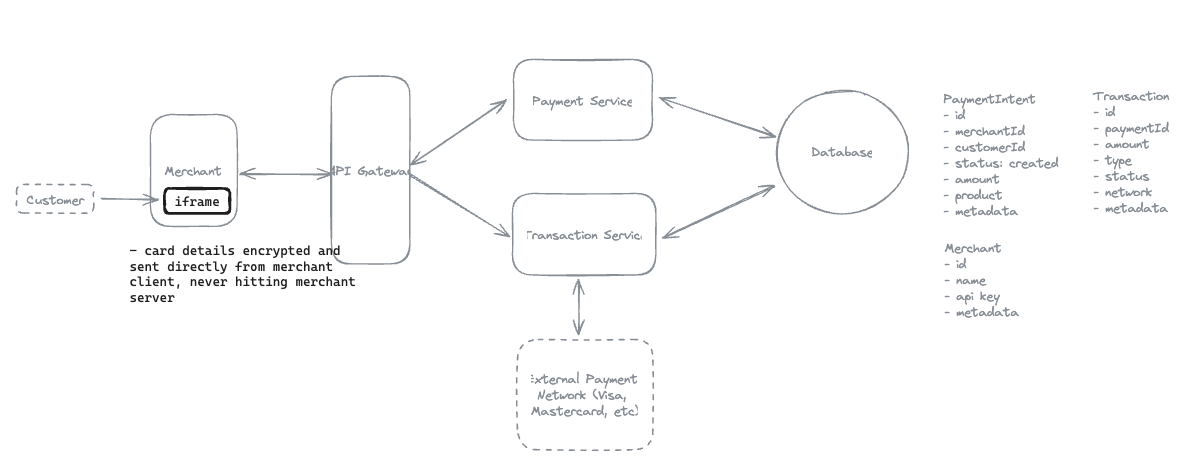
12.10. How would you ensure that no transaction data is ever lost and maintain complete auditability for compliance?
Notes: Client -> API Gateway -> Service -> Database (Every functional requirements => can be implement with this patterns)
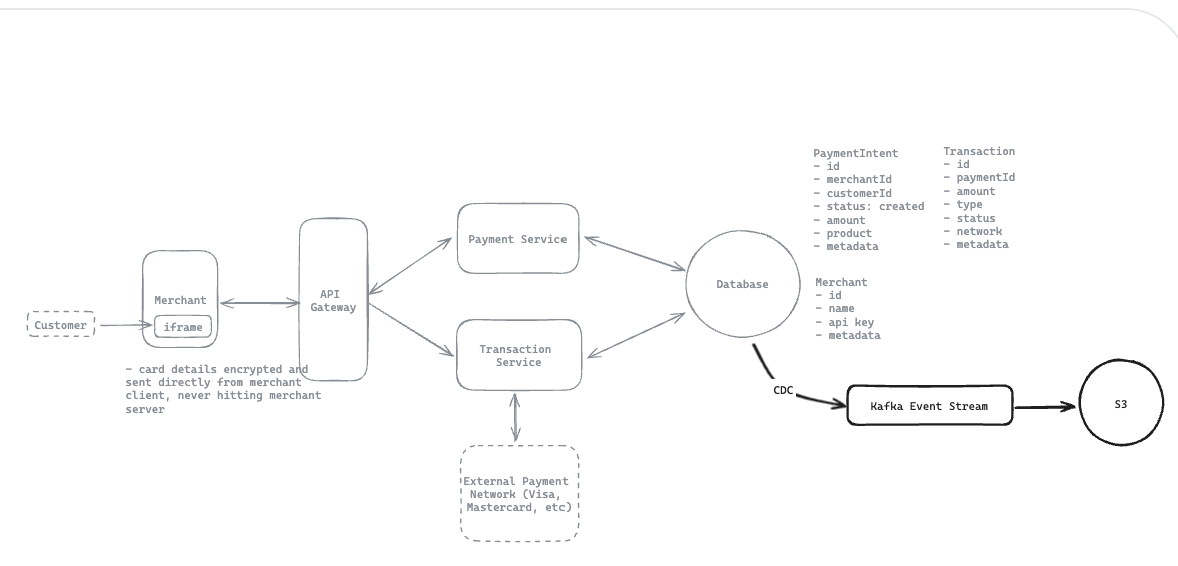
12.11. How would you ensure transaction safety and financial integrity despite the inherently asynchronous nature of external payment networks?
-
To ensure transaction safety despite asynchronous payment networks, we’ll implement an event sourcing architecture with reconciliation.
-
Implement reconcile workers to make sure transaction work.
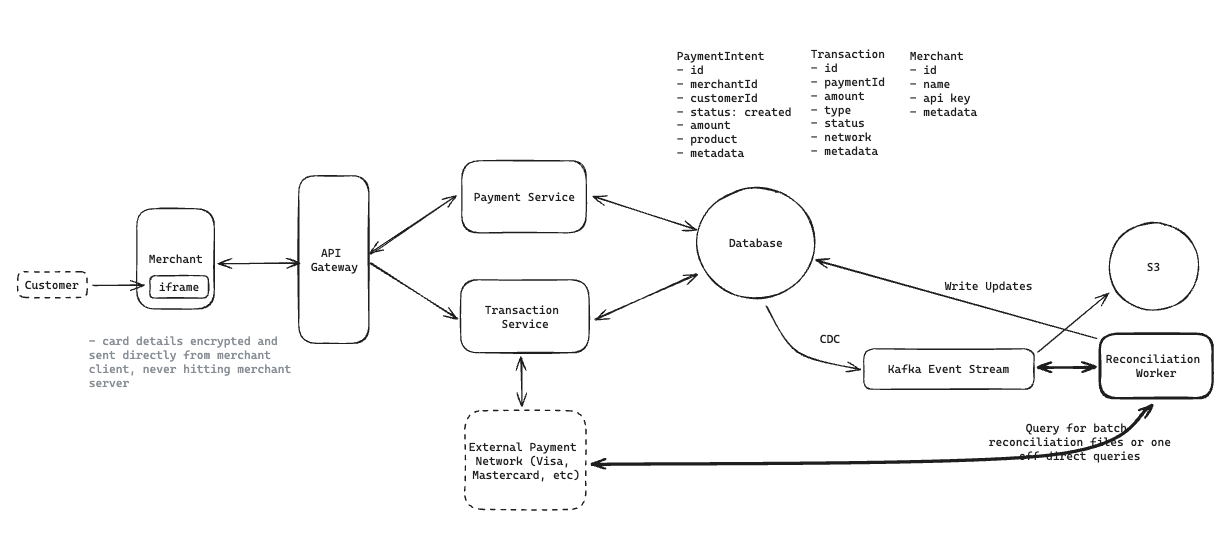
12.12. How would you scale the payment system to handle 10,000+ transactions per second?
Notes: Client -> API Gateway -> Service -> Database (Every functional requirements => can be implement with this patterns)
-
Horizontal scaling with load balancers distributing traffic across stateless service instances.
-
For Kafka, our event log, we’ll set up multiple partitions (3-5) to handle our throughput needs, payment_intent_id to ensure ordering.
-
Our database, handling around 1,000 write operations per second (an order of magnitude smaller than our event log), can be managed with a well-optimized PostgreSQL instance with read replicas for distributing read operations.
-
Data retention policy.
![]()
12.13. Idempotent operations ensure repeated requests produce the same final state.
- True
12.14. Payment systems must handle the inherently asynchronous nature of external payment networks like Visa and Mastercard.
- Yes
12.15. Which technique BEST prevents duplicate charges when external service calls may time out?
- Idempotency keys on client requests
12.16. A payment processor must absorb 10,000 transactions per second spikes. Which scaling pattern distributes load horizontally with minimal coordination?
- Stateless microservices behind a load balancer
12.17. Message queues offering at-least-once delivery can result in duplicate message processing after consumer failures.
- If a consumer crashes before acknowledging a message, the broker re-delivers it to another consumer.
12.18. Which security technique limits a merchant’s PCI DSS scope by never exposing card data to their servers?
- Tokenization with client-side encryption.
12.19. What happens when a duplicate idempotency key is received for an already successful charge?
- The original result is returned without a new charge
12.20. Marking a transaction as ‘pending verification’ after a network timeout avoids overcharging customers.
-
Yes
-
Deferred verification acknowledges uncertainty instead of assuming failure.
-
Preventing merchants from retrying prematurely and creating duplicate charges while the processor reconciles the real outcome.
12.21. Event sourcing allows rebuilding current payment state by replaying immutable events.
- Storing every state-changing event in an append-only log lets systems materialize fresh views at any time, aiding auditing, recovery, and debugging.
12.22. In an event-driven payment system with reconciliation, what enables correlating internal attempts with external payment network events?
-
Recording attempt details before calling payment networks.
-
The reconciliation service can later correlate external events from payment networks with our internal attempts to resolve any discrepancies.
12.23. A merchant receives a ‘payment.succeeded’ webhook. Which property ensures they can safely retry webhook processing after a crash?
- Idempotent webhook handler on the merchant server => guaranteeing at-least-once delivery semantics without duplicating fulfillment actions.
12.24. Which approach BEST ensures no payment transaction data is ever lost while maintaining audit compliance?
- CDC automatically captures all database changes at the database level and feeds them to an immutable event stream (like Kafka), guaranteeing no audit data is lost regardless of application bugs
12.25. When a payment request to an external network times out, what should a payment system do to ensure transaction safety ?
- Mark the payment as ‘pending verification’ and reconcile later => queries the payment network to determine what actually happened, preventing double-charging.
12.26. Change Data Capture (CDC) operates at the database level, guaranteeing that application bugs cannot skip audit logging.
- CDC monitors the database’s write-ahead log or oplog, capturing every committed change automatically => do not depend on application level.
13. Design Robinhood
13.1. Functional Requirements
-
Users can see live prices of stocks
-
Users can create orders for stocks
-
Users can see their orders for stocks
13.2. Non-functional requirements
-
Low latency price updates.
-
High consistency for orders.
-
Minimize exchange API connections.
13.3. Entities

13.4. API Design

13.5. How will users be able to see live prices of stocks?
Notes: Client -> API Gateway -> Service -> Database (Every functional requirements => can be implement with this patterns)
13.6. How will users be able to create orders for stocks?
13.7. How will users be able to see their orders for stocks?
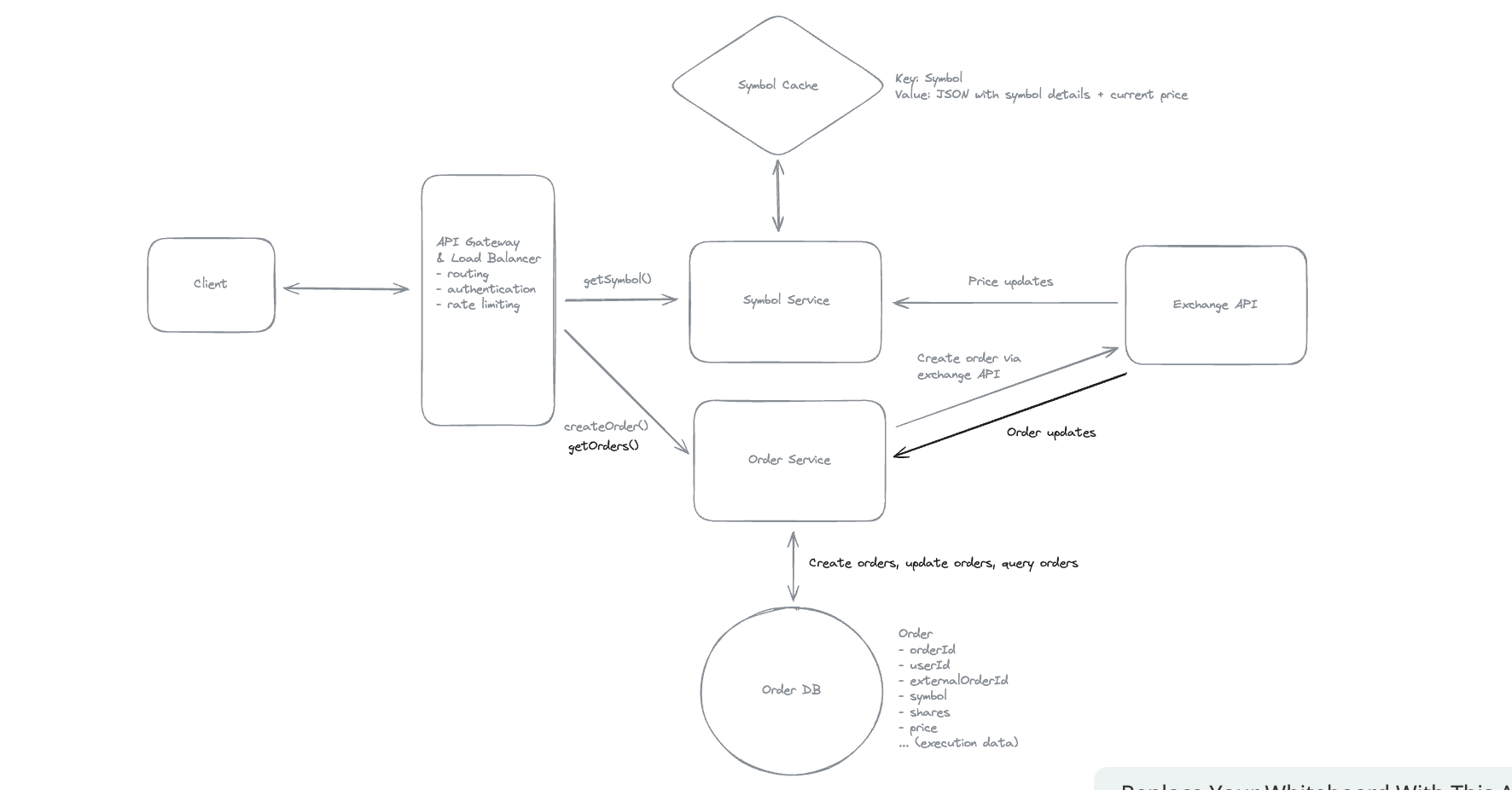
13.8. How would the system ensure real-time price updates?
- Using SSE, Websocket.
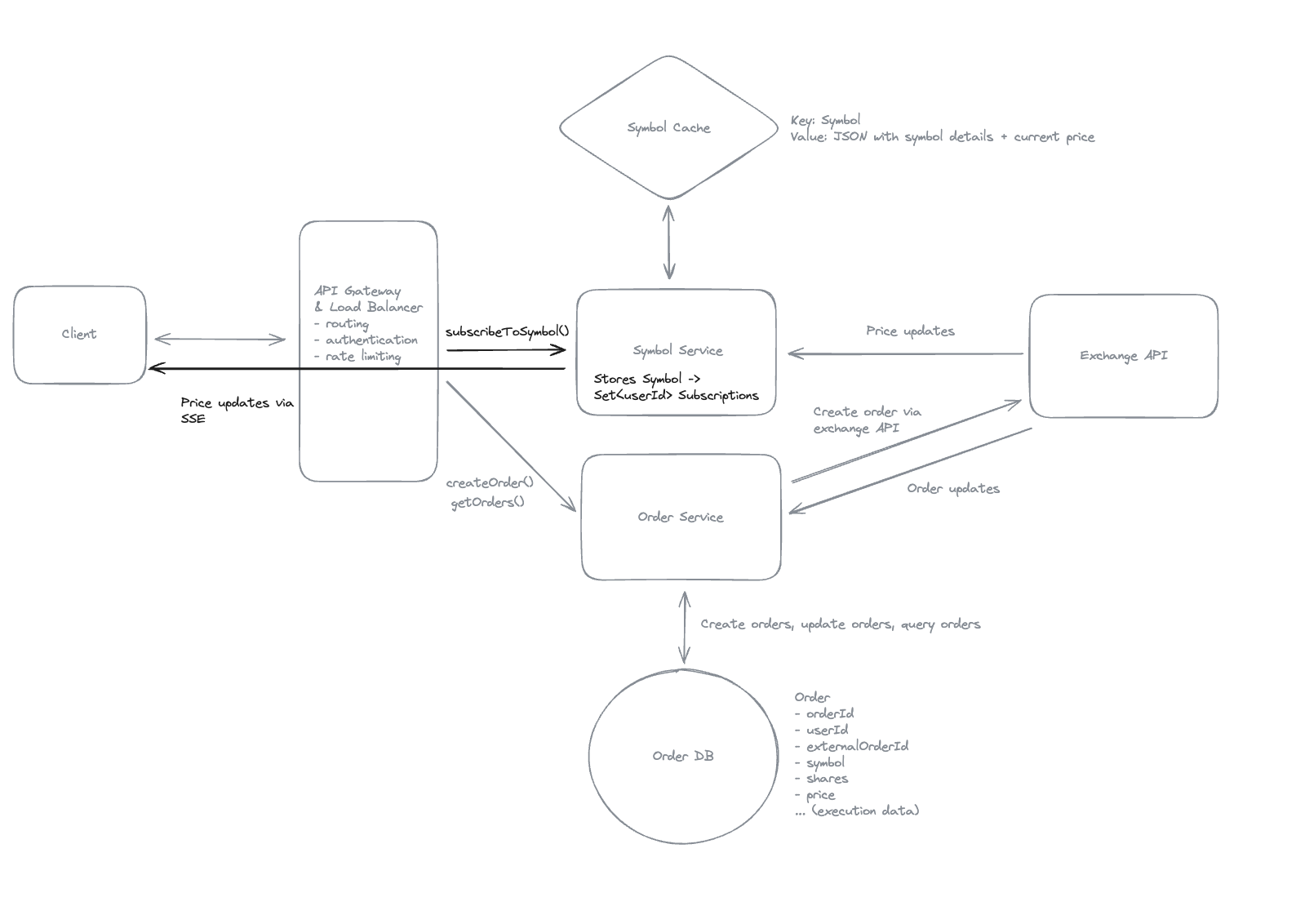
13.9. How would the system manage a large volume of price updates sent to a large number of users?
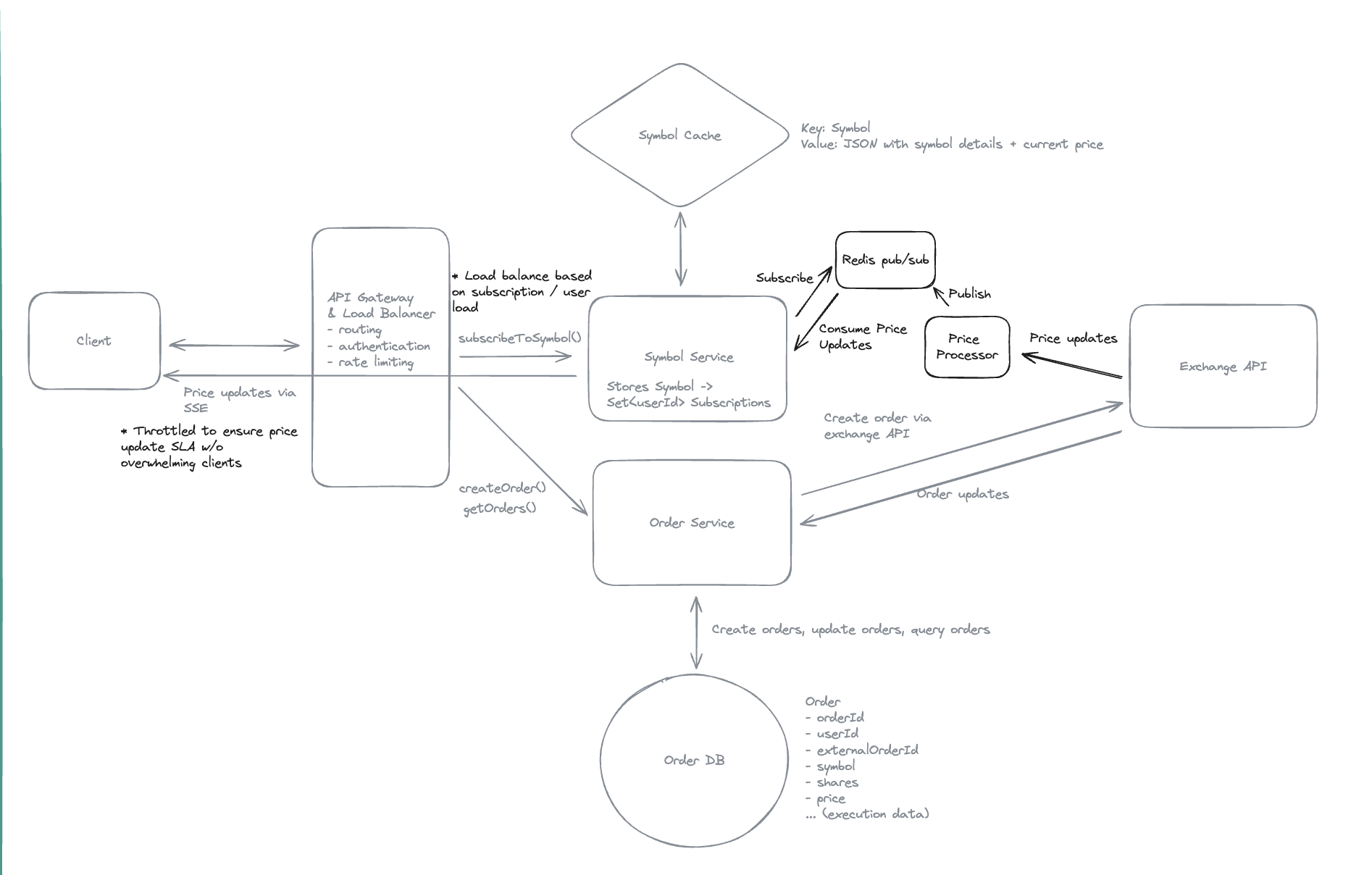
13.10. How would you ensure high order consistency?
- This ensures that order updates are atomic and also that the system guarantees read-your-writes consistency. This also guarantees that all orders for a user are on a single partition => workflow machine.
-
Store an order in the order database with “pending” as the status. It’s important that this is stored first because we reliably document the order intent. If we didn’t store this first, then the client could create an order on the exchange, the system could fail, and then our system has no way of knowing there’s an outstanding order.
-
Submit the order to the exchange. Get back externalOrderId immediately (the order submission is synchronous).
-
Write externalOrderId to our key-value database and update the order in the order database with status as “submitted” and externalOrderId as the ID received from the DB.
-
Respond to the client that the order was successful.
- If the system fails to submit an order to the exchange, we can record the order as “failed”. If the system fails right before submitting an order, then it will be in a “pending” state. We could easily run a periodic job to mark “pending” orders as “failed”, as these never made it to the exchange.
14. Design Uber
14.1. Functional Requirements
-
Riders should be able to input a start location and a destination and get a fare estimate
-
Riders should be able to request a ride based on the estimated fare
-
Drivers should be able to accept/decline a request and navigate to pickup/drop-off
14.2. Non-functional requirements

14.3. What are the core entities of the system?

14.4. API Design

14.5. How would you give users a estimated fare based on their start location and destination?
Notes: Client -> API Gateway -> Service -> Database (Every functional requirements => can be implement with this patterns)
- he service then calls a third-party mapping API to obtain route information, including distance and estimated travel time => estimated travel time.
14.5. How will riders be able to request a ride based on the estimated fare?
-
Components, Method, Patterns.
-
The client initiates a POST request to the /rides endpoint, including the fareId that was returned during fare estimation in the request body.
-
The service first validates that the fare estimate exists and is still accurate. It then creates a new Ride entity in the database with a status of ‘requested’
=> Not have driver_id
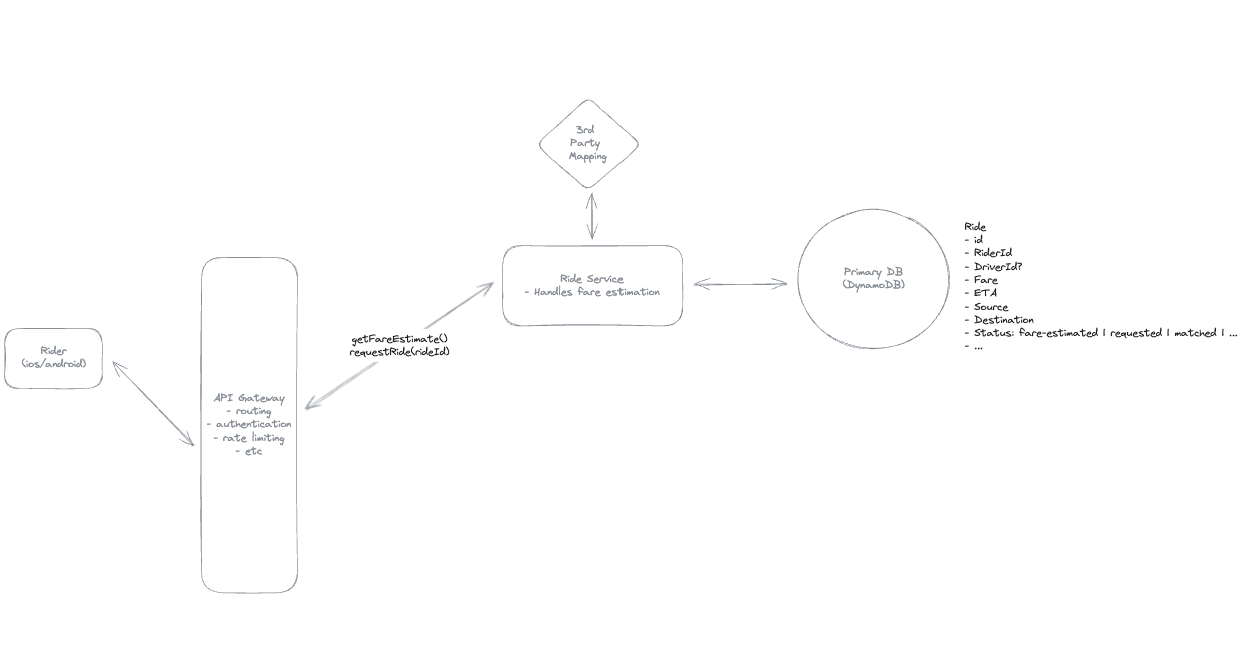
14.6. How does your system match riders to the best driver for their ride?
-
When a ride is requested, we trigger the Matching Service. This service queries a Location Database to find nearby available drivers.
-
Drivers periodically update their locations by sending POST requests to a /drivers/location endpoint.
-
The Matching Service uses this data to perform a proximity search => Send a ride that they can confirm or deny.
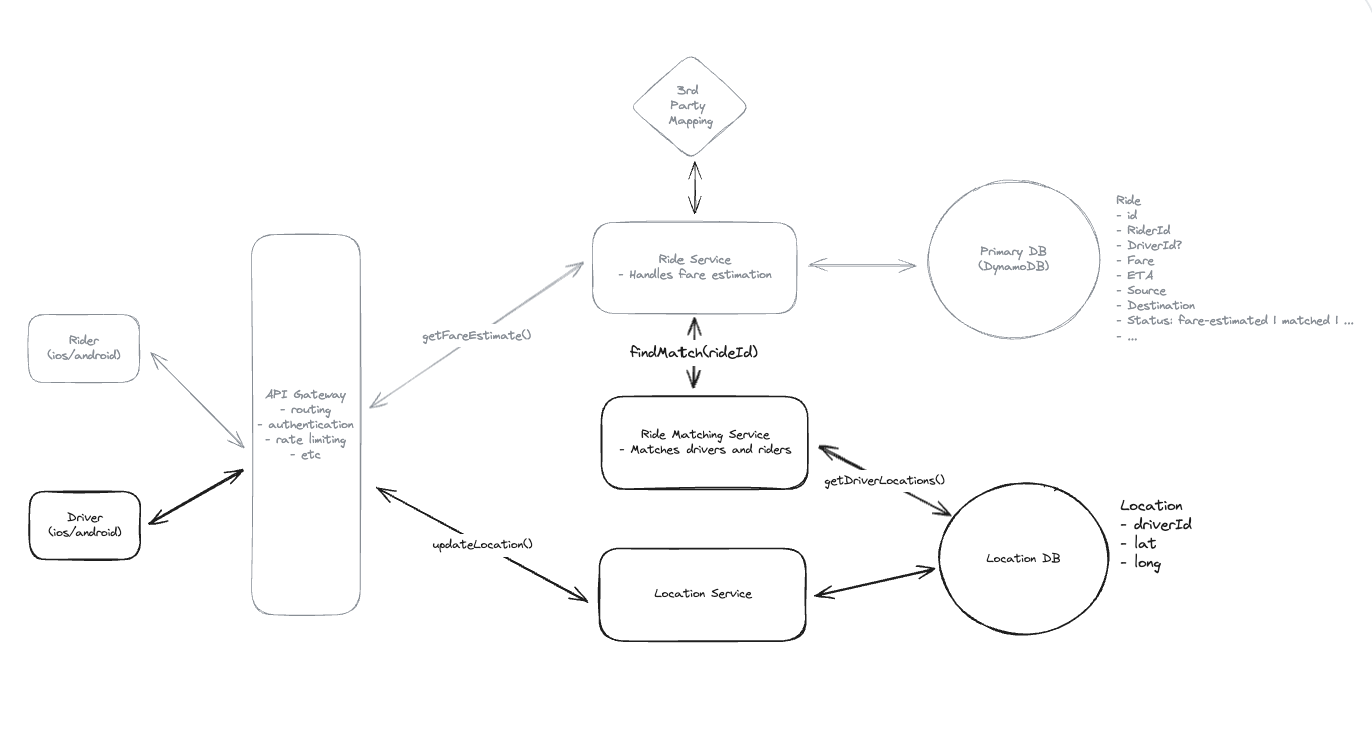
14.7. How does your system notify matched drivers and allow them to accept/decline rides?
-
Once a driver is matched to a ride request, the Matching Service sends a message to a Notification Service.
-
This service sends a push notification to the driver’s mobile app about the new ride request.
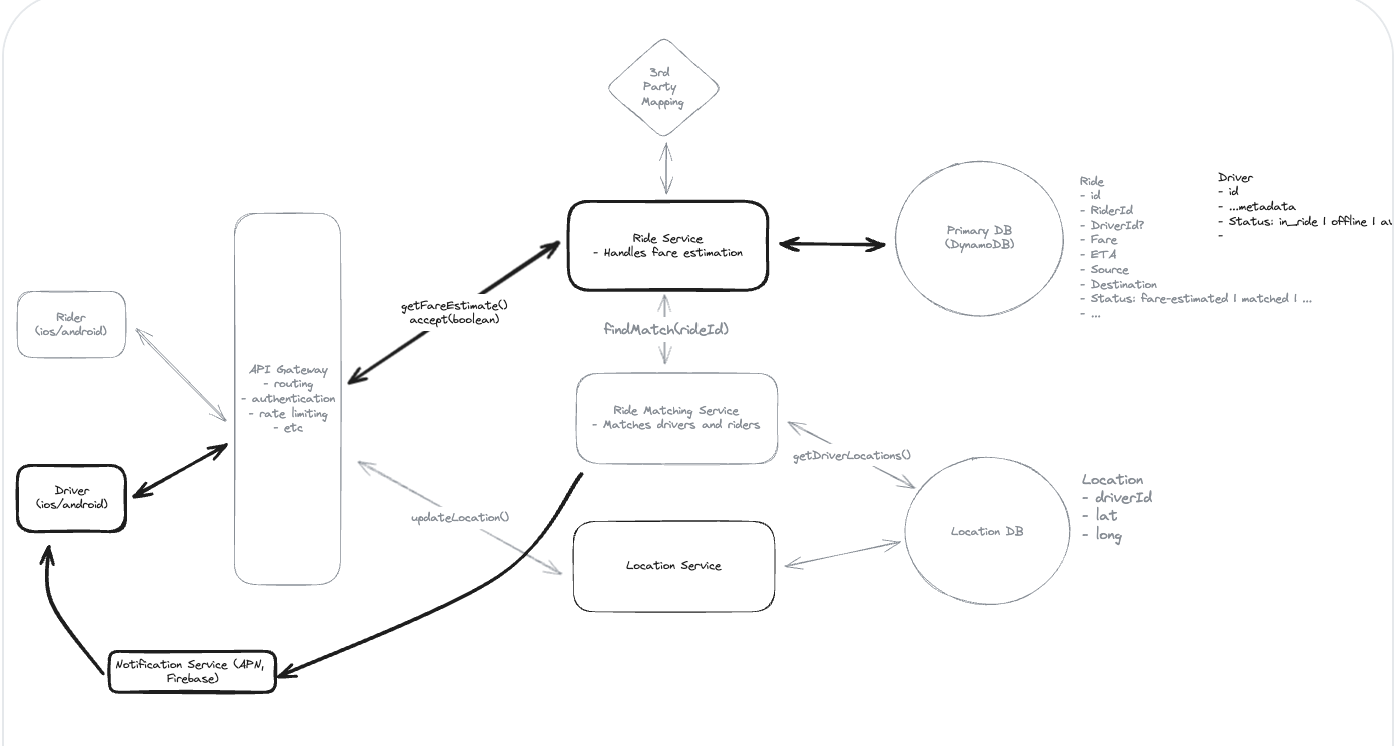
14.8. How can you handle the high write throughput from drivers sending location updates every couple seconds and efficiently perform proximity searches for matching?
-
We can use Redis with its geospatial indexing capabilities to efficiently handle high write throughput and perform proximity searches.
-
We use Redis’s GEOSEARCH command together with the WITHDIST option
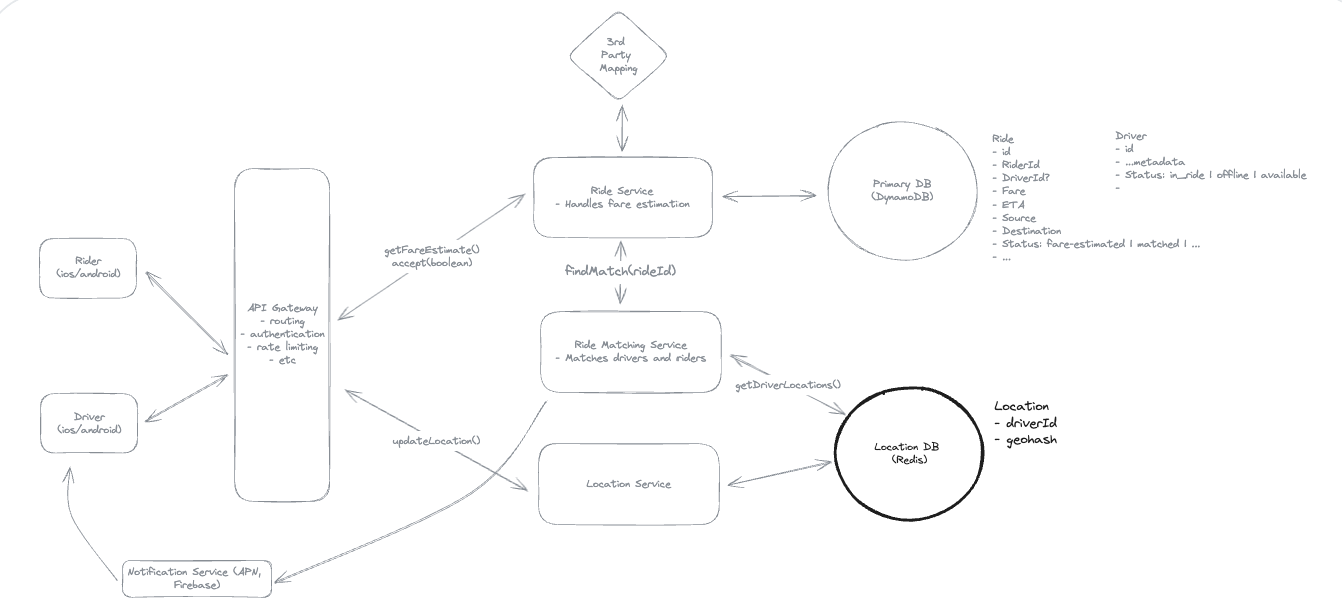
14.9. How do we guarantee each driver receives at most one ride request at a time?
-
We can use Redis to implement a distributed lock system
-
When a ride request is sent to a driver, the Ride Matching Service creates a lock in Redis with the driver’s ID as the key and a 10-second TTL.
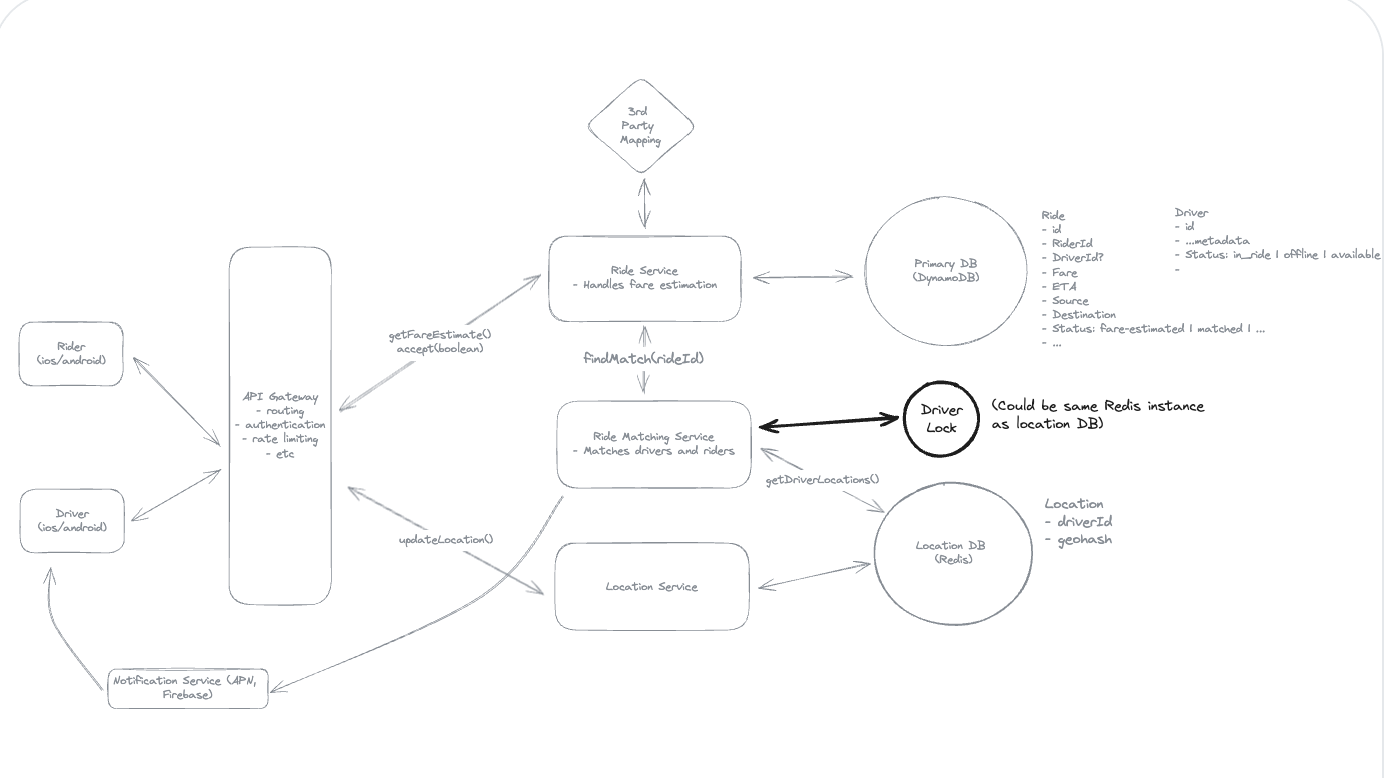
14.10. How can we ensure no ride requests are dropped during peak demand periods?
-
We can introduce Kafka as a buffer to increase durability.
-
When a ride request needs matching, it’s added to a Kafka topic partitioned by geographic region.
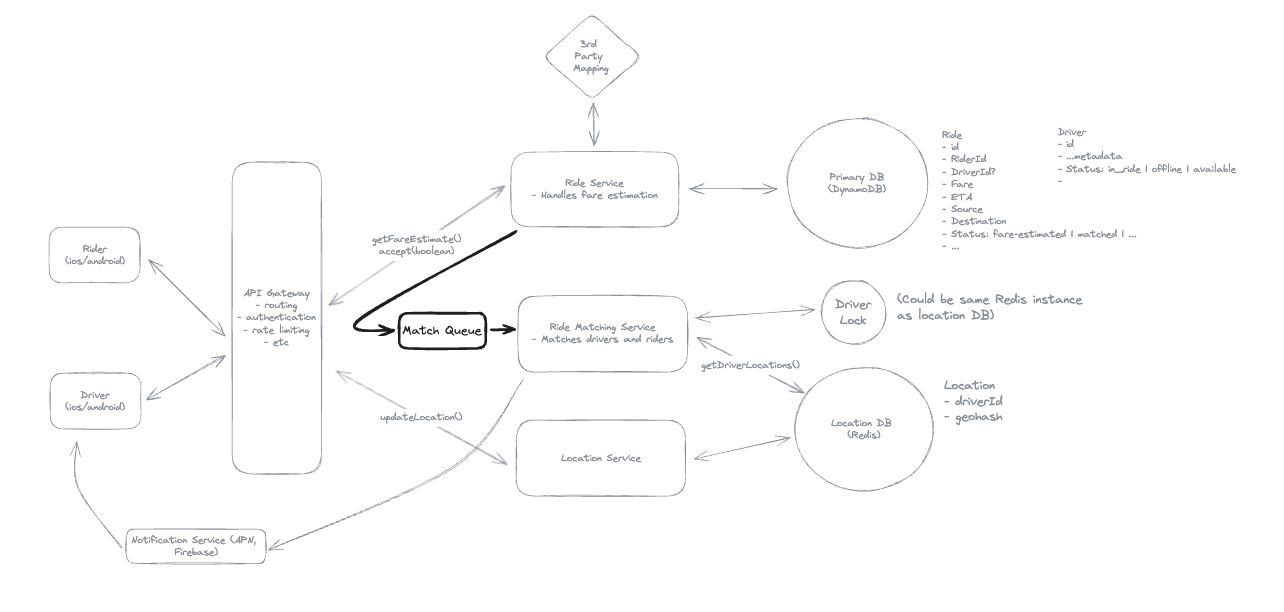
14.11. In-memory databases provide faster access than disk storage.
- Yes
14.12. Which data structure efficiently partitions 2D space for proximity searches?
-
Quad-trees recursively partition 2D space into quadrants,
-
B-trees are for 1D data
14.13. Which technique reduces database write load during high-frequency updates?
- Batch processing aggregates multiple updates into single write operations, significantly reducing database load.
14.14. What component routes requests and handles authentication in microservices?
- API Gateway
14.15. Geographic sharding reduces latency by distributing data closer to users.
- Yes
14.16. How do systems prevent dropped requests during traffic spikes?
- Using queue.
14.17. Strong consistency prevents double-booking of shared resources.
- Yes
14.18. Which scaling approach provides better fault tolerance?
- Horizontal scaling
14.19. Message queues with offset commits ensure no data loss during failures.
-
Offset commits: in message queues like Kafka track processing progress.
-
If a consumer fails, unprocessed messages remain in the queue for retry, ensuring reliable delivery and no data loss.
14.20. What is one way mobile applications receive real-time notifications from servers?
- Push notification services like APN/FCM
14.21. What is one way systems can efficiently store and query geographic coordinates?
- Geohashing: encodes latitude/longitude into strings that preserve spatial locality - nearby locations have similar hash prefixes.
14.22. In a geographically sharded system, proximity searches near shard boundaries require querying multiple shards to get complete results.
-
When searching for nearby drivers or locations near the edge of a geographic shard (like city boundaries), the closest results might be in adjacent shards.
-
To ensure completeness, the system must query multiple shards and aggregate results - this is called a scatter-gather pattern.
14.23. What happens when geographic shards become unbalanced?
- Unbalanced shards create hot spots where some servers are overloaded while others are underutilized.
=> This degrades performance through increased latency and potential timeouts on overloaded shards.
15. Design Leetcode
15.1. Functional Requirements
-
Users should be able to view a list of coding problems.
-
Users should be able to view a given problem, code a solution in multiple languages.
-
Users should be able to submit their solution and get instant feedback.
-
Users should be able to view a live leaderboard for competitions.

15.2. Entities

15.3. API Design
GET /problems/:id?language={language} -> Problem
POST /problems/:id/submit -> Submission
{
code: string,
language: string
}
GET /leaderboard/:competitionId?page=1&limit=100 -> Leaderboard
15.4. Users should be able to view a list of coding problems
15.5. Users should be able to view a given problem and code a solution
15.6. Users should be able to submit their solution and get instant feedback
- Run code in serverless environment.
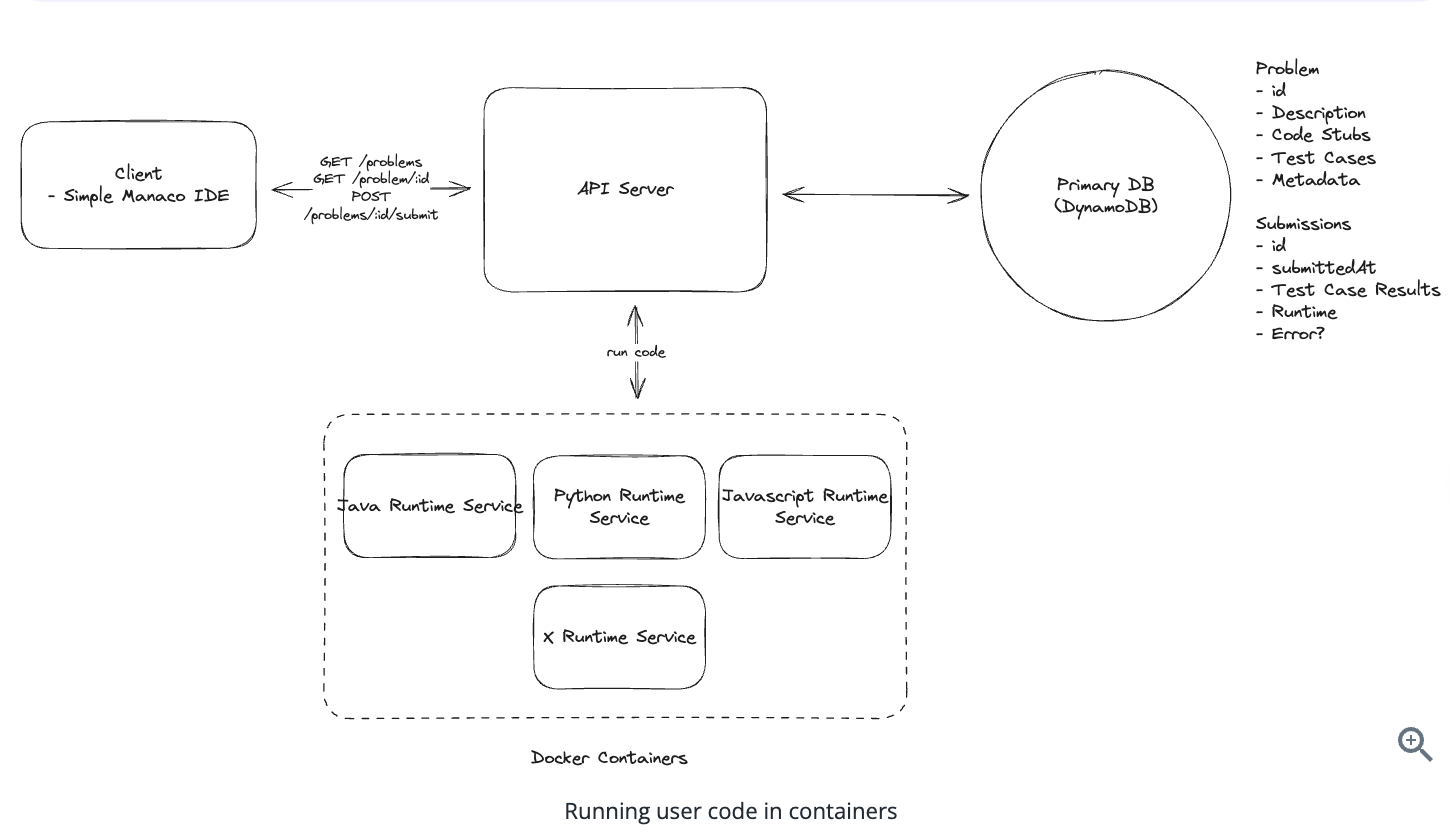
15.7. Users should be able to view a live leaderboard for competitions
- In a NoSQL DB like DynamoDB, you’d need to have the partition key be the competitionId. Then you’d pull all items into memory and group and sort.
15.8. How will the system support isolation and security when running user code?
Security
- Docker for isolation
- Read only filesystem (writes to tmp)
- CPU and memory bounds
- Explicit timeout per execution
- VPC for network controls
- No system calls (seccomp)
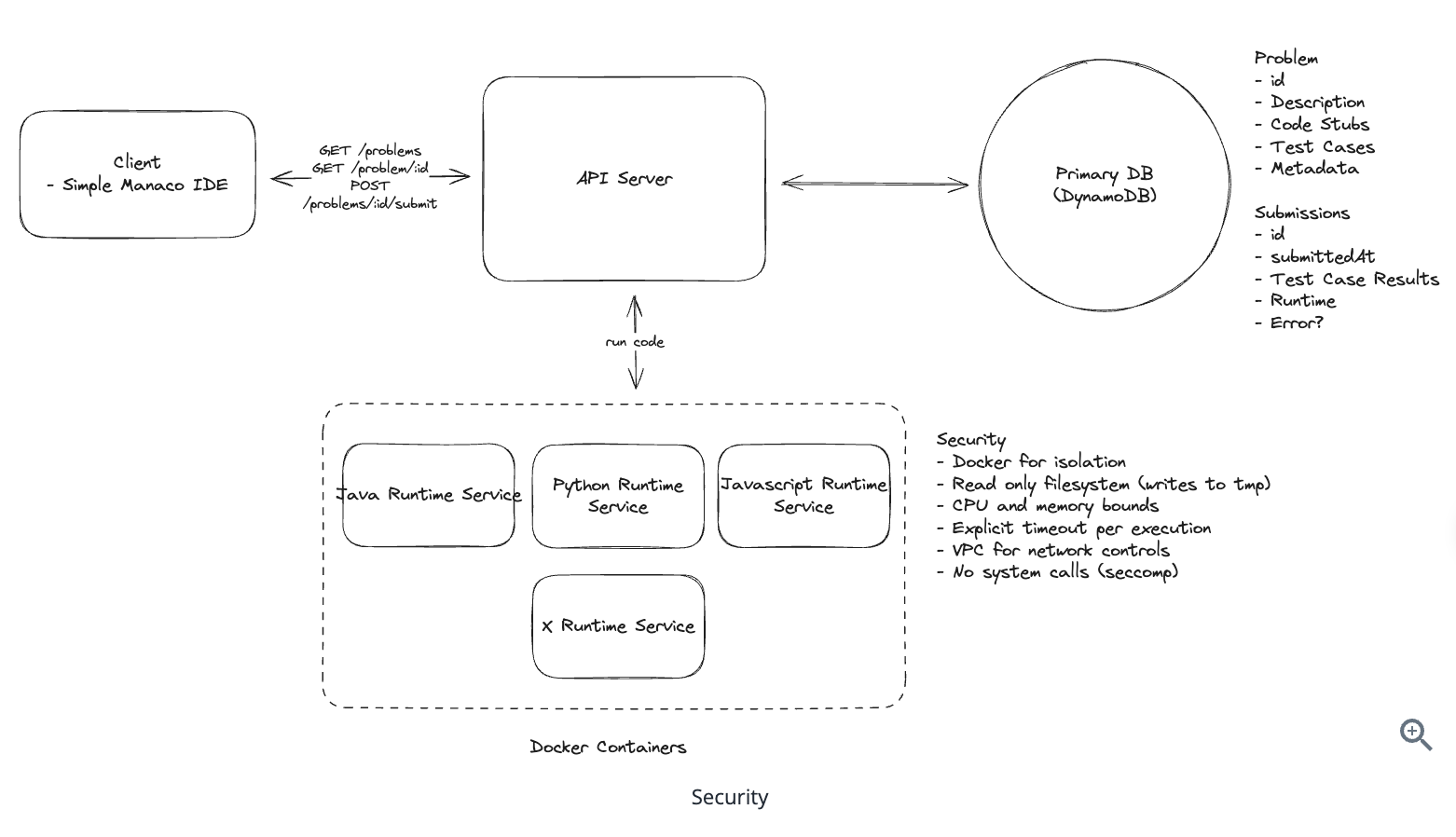
15.9. How would you make fetching the leaderboard more efficient?
- Redis sorted set with periodic polling.
Using:
-
ZADD competition:leaderboard
-
ZREVRANGE competition:leaderboard:{competitionId} 0 N-1 WITHSCORES
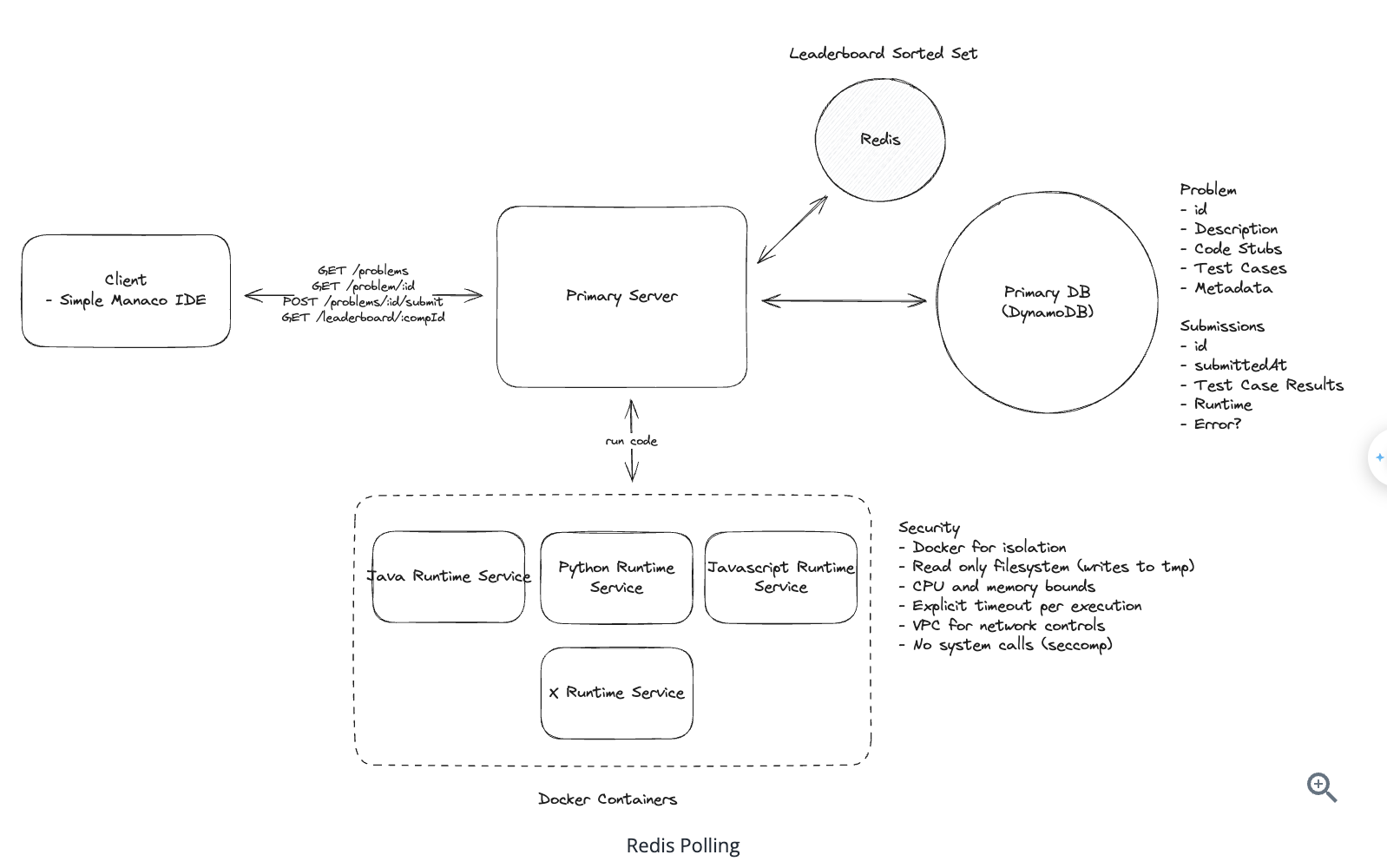
15.10. How would the system scale to support competitions with 100,000 users?
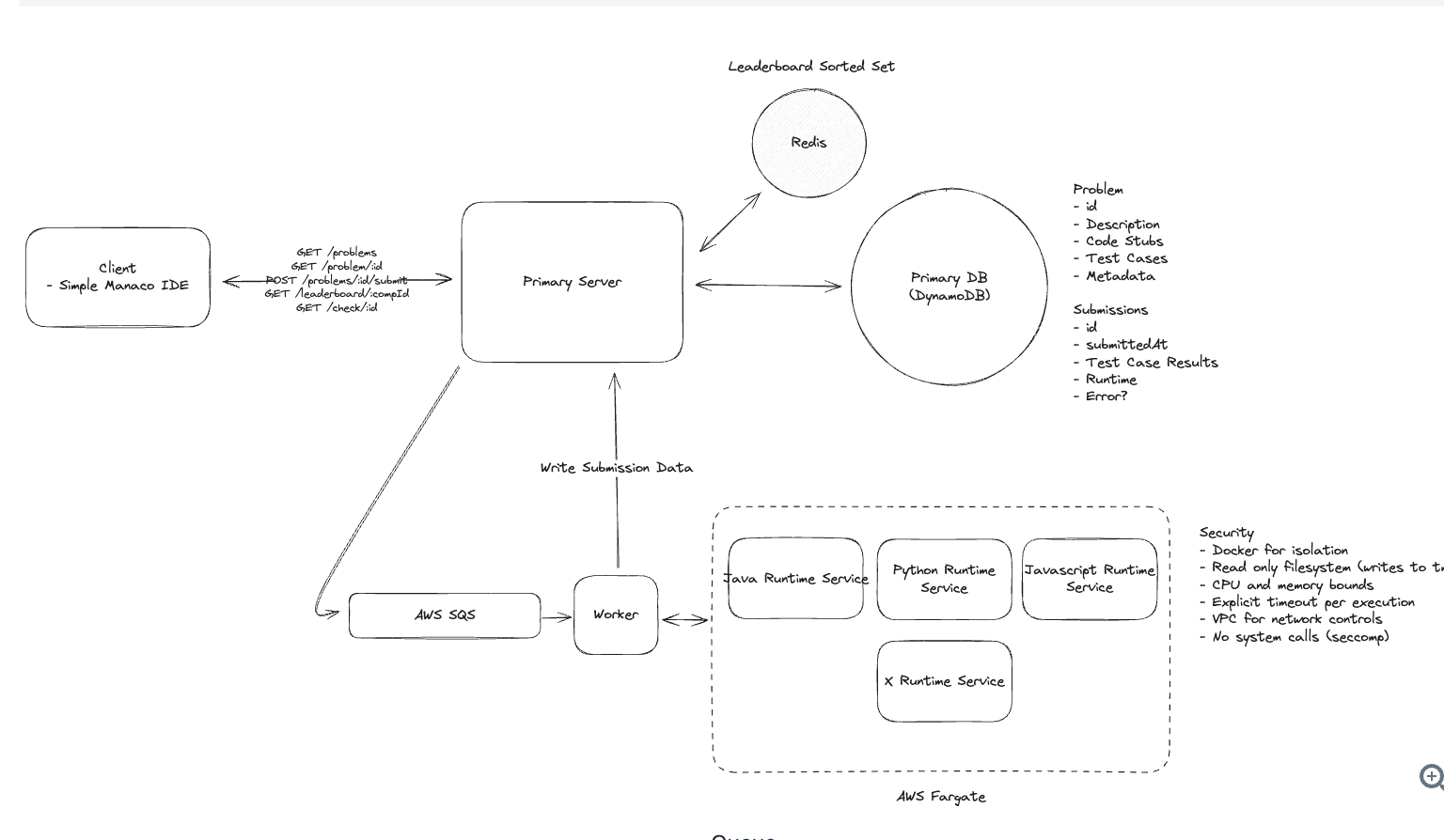
15.11. How would the system handle running test cases?
- We’d need to define the serialization strategy for each data structure and ensure that the test harness for each language can deserialize the input and compare the output to the expected output.
15.12. Containers provide process isolation from the host operating system.
- Yes, this isolation prevents processes in one container from affecting the host system or other containers.
15.13. Resource limits can prevent untrusted code from consuming unlimited system resources.
- Yes
15.14. Which technique prevents infinite loops in user-submitted code?
- Execution timeouts
15.15. Timestamps that need to be trusted should be generated on the server not the client.
- Client-provided timestamps can be easily manipulated or incorrect due to clock skew.
15.16. Which is NOT a secure way to handle user authentication?
- URL parameters are visible in browser history, server logs, and can be easily intercepted or shared inadvertently.
15.17. Message queues primarily help systems handle which challenge?
- Load spikes
15.18. Which approach works BEST for CPU-intensive code execution at scale?
- Asynchronous processing allows systems to handle CPU-intensive tasks without blocking other operations.
15.19. Caching reduces database load by storing frequently accessed data in memory.
- Yes
15.20. Which Redis data structure can enable efficient real-time leaderboard updates?
- Sorted set
15.21. Load balancers distribute traffic across multiple servers to prevent bottlenecks.
- Yes
15.22. What is the MOST important factor when running untrusted user code?
- Security isolation is paramount when executing untrusted code to prevent malicious or buggy code from compromising the host system, accessing sensitive data, or affecting other users
15.23. What is the primary advantage of containers over virtual machines for code execution?
- Lower resource overhead
15.24. When processing millions of database queries per second, which optimization helps most?
- In-memory caching
15.25. Systems can prioritize availability over consistency for non-critical features like leaderboards.
- Yes
15.26. What is the most important consideration when running user-inputted code?
- Security isolation is the paramount concern when executing untrusted user code.
16. Design Distributed Cache
16.1. Requirements
-
Users should be able to set, get, and delete key-value pairs.
-
Users should be able to configure the expiration time for key-value pairs.
-
Data should be evicted according to Least Recently Used (LRU) policy.
16.2. Non-functional requirements
-
The system should be highly available. Eventual consistency is acceptable.
-
The system should support low latency operations (< 10ms for get and set requests).
-
The system should be scalable to support the expected 1TB of data and 100k requests per second
16.3. Core Entities
-
Key.
-
Value.
16.4. API Design
POST /:key
{
"value": "..."
}
GET /:key -> {value: "..."}
DELETE /:key
16.5. Users should be able to set, get, and delete key-value pairs
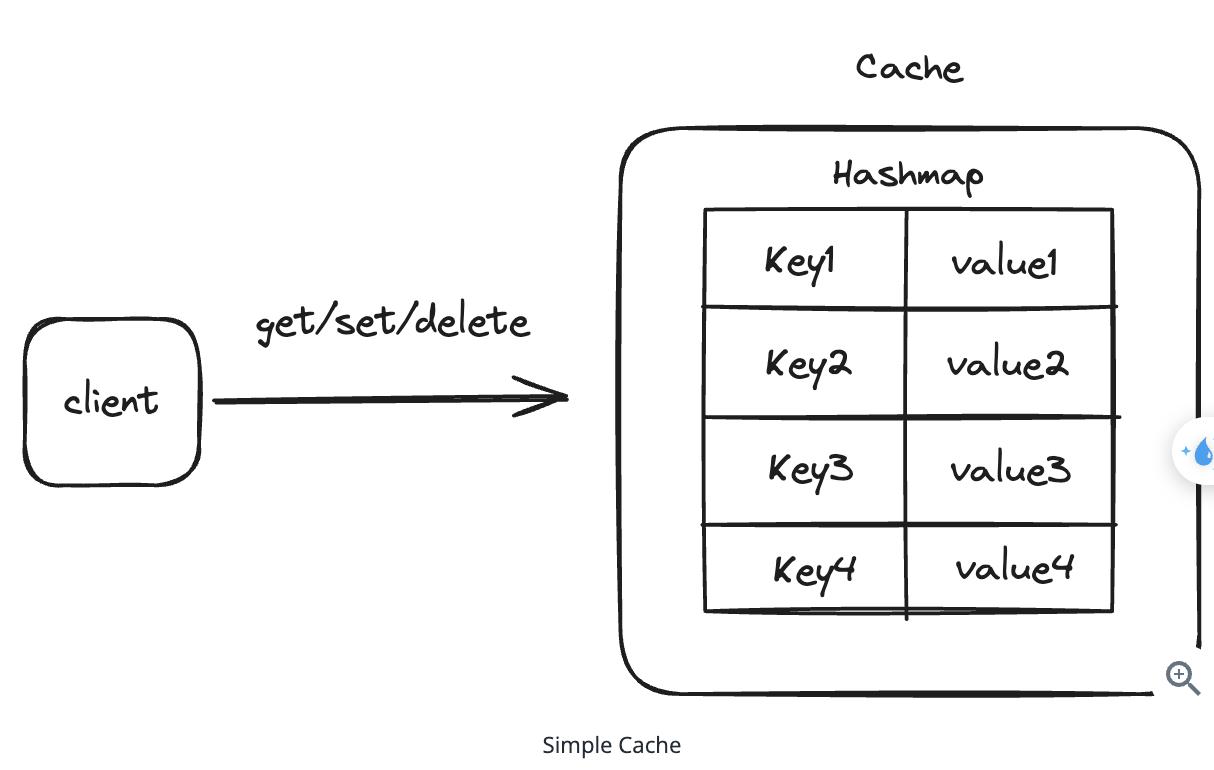
16.6. Users should be able to configure the expiration time for key-value pairs
- Running the background process to clen cache, called Janitors
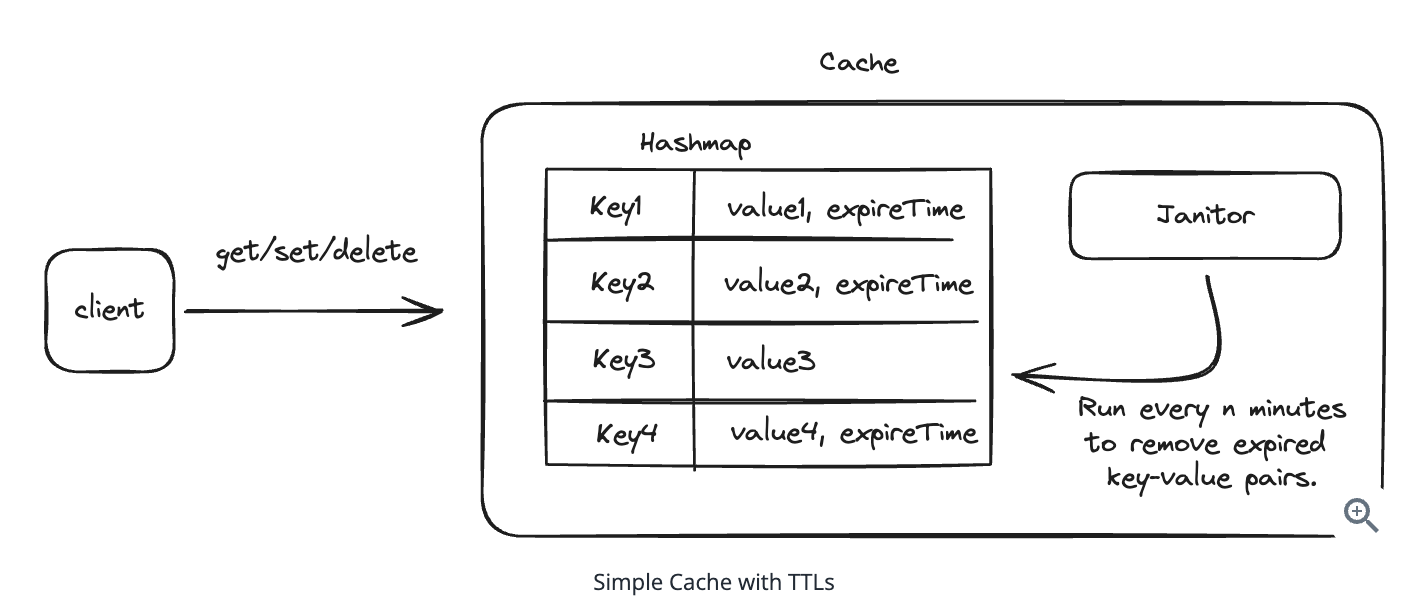
16.7. Data should be evicted according to LRU policy
- When cache is full, we need to implement LRU Strategy for storage.
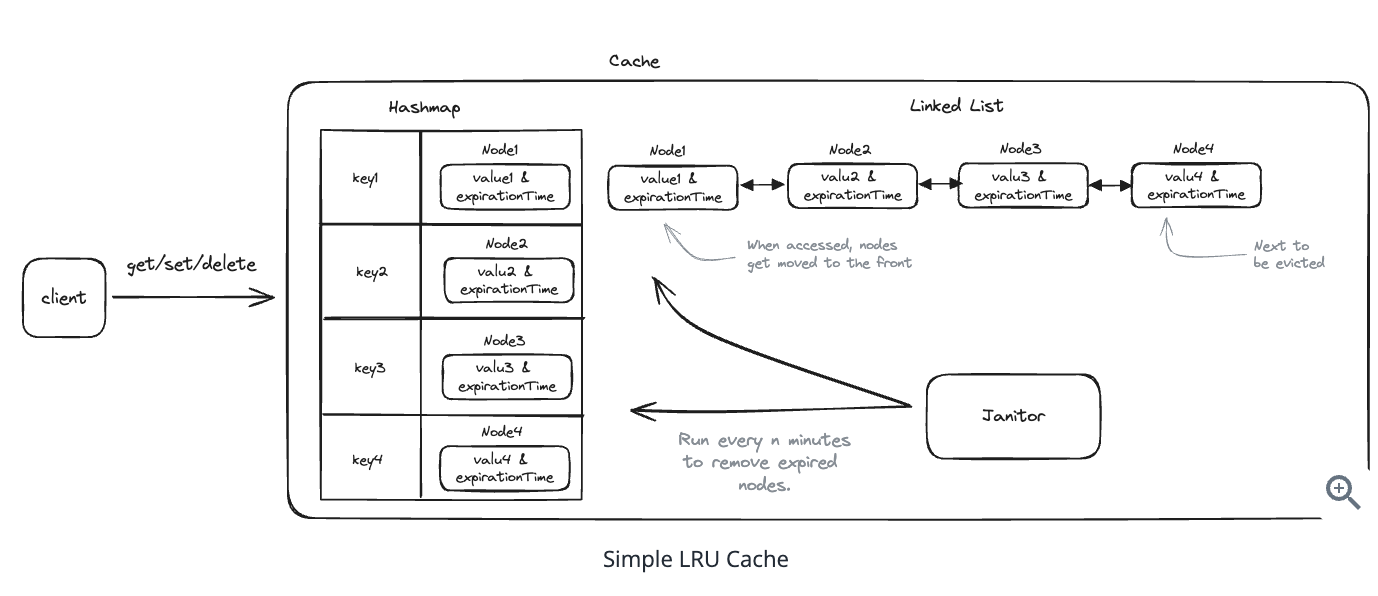
16.8. How do we ensure our cache is highly available and fault tolerant?
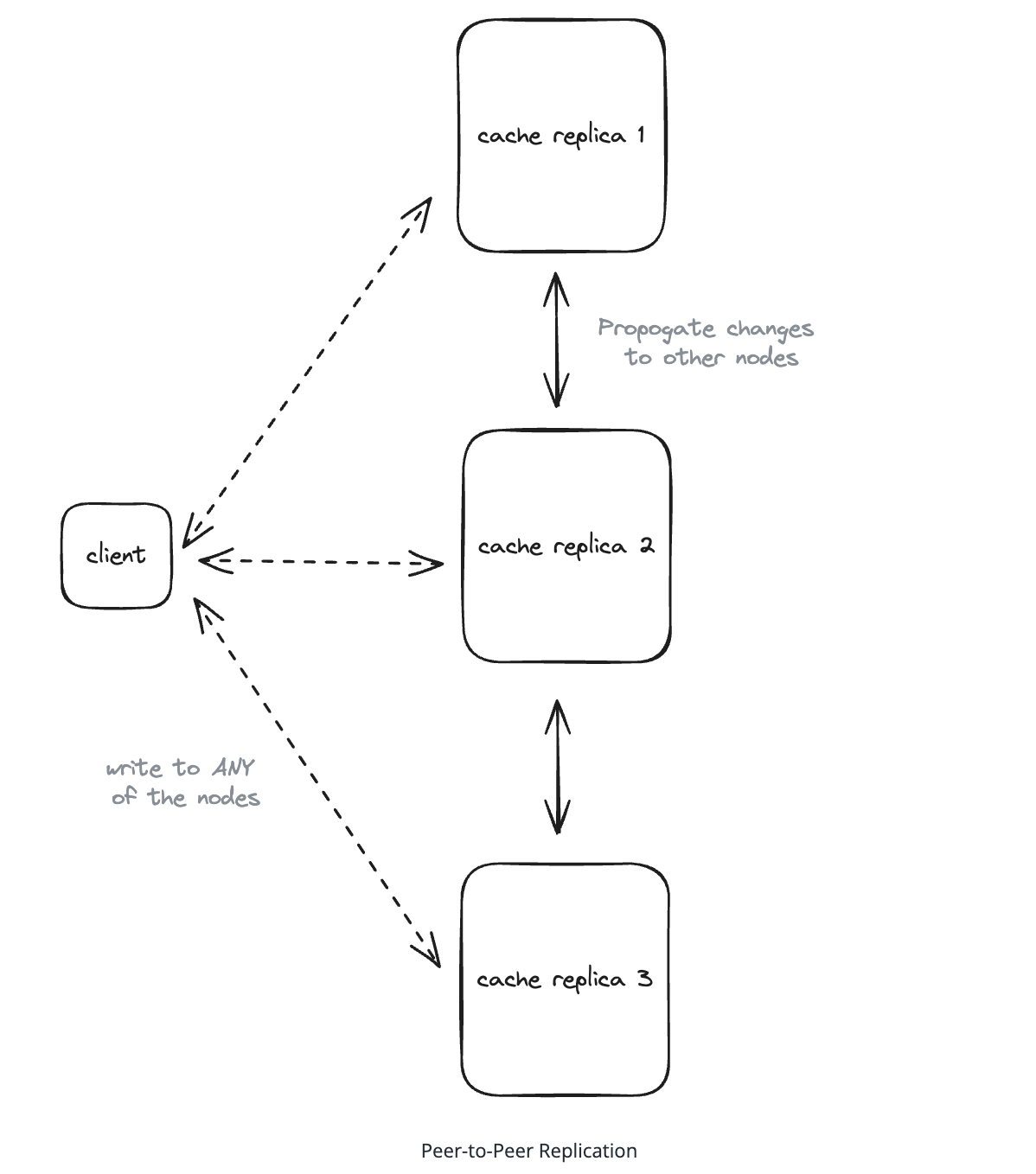
16.9. How do we ensure our cache is scalable?
-
Let’s start with throughput. 1 node 20,000 requests per second => we would need at least 100,000 / 20,000 = 5 nodes to handle our throughput requirements.
-
For storage requirement, 1 node 32GB RAM can use 24GB for cache data => 1024GB / 24GB = 43 nodes just for storage.
-
Choose the max value to use is 43 nodes => around to 50 nodes.
16.10. How can we ensure an even distribution of keys across our nodes?
- We can use distributed hashing.
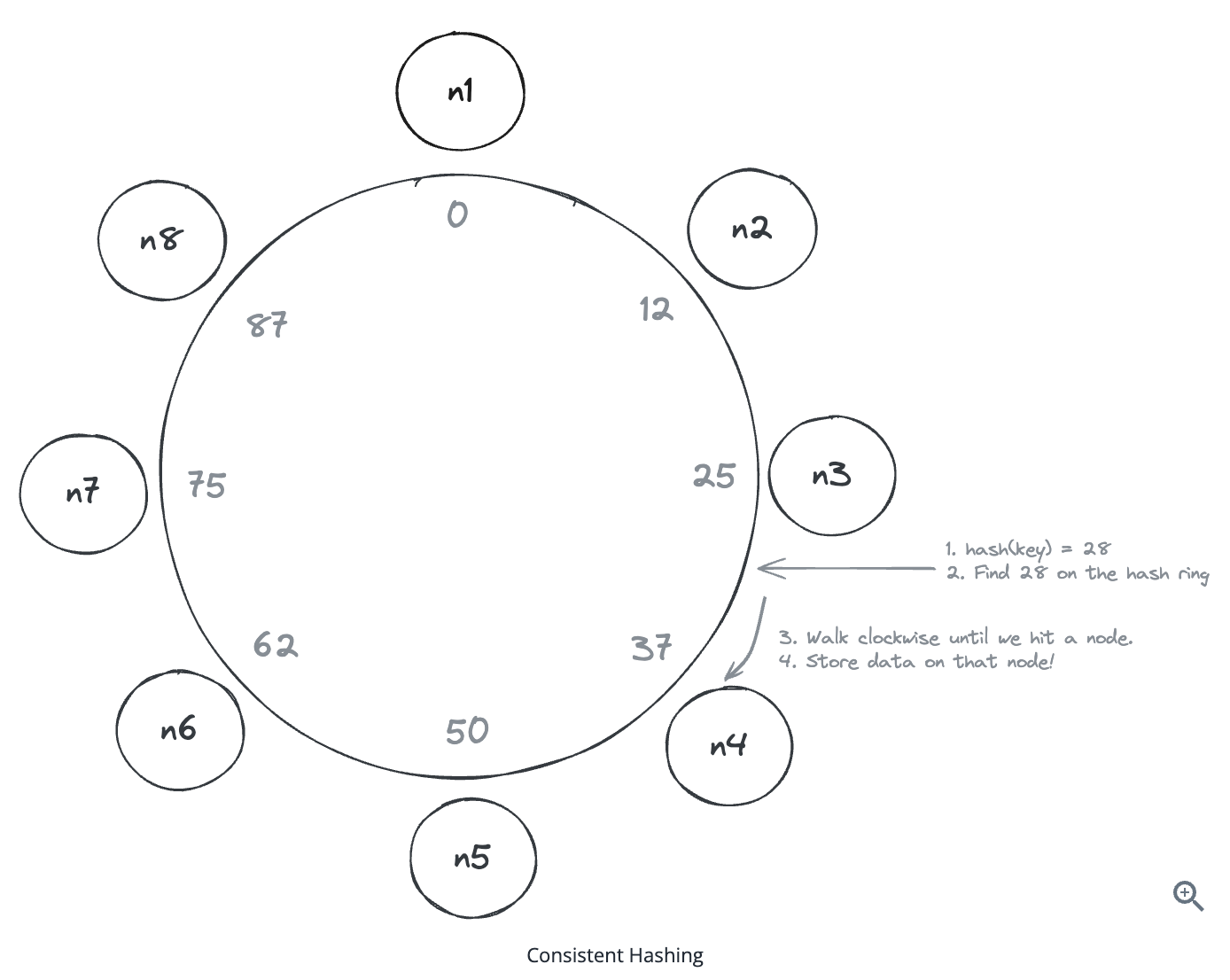
16.11. What happens if you have a hot key that is being read from a lot? (Heavy-read)
Some hot keys:
-
Hot reads: Keys that receive an extremely high volume of read requests, like a viral tweet’s data that millions of users are trying to view simultaneously.
-
Hot writes: Keys that receive many concurrent write requests, like a counter tracking real-time votes.
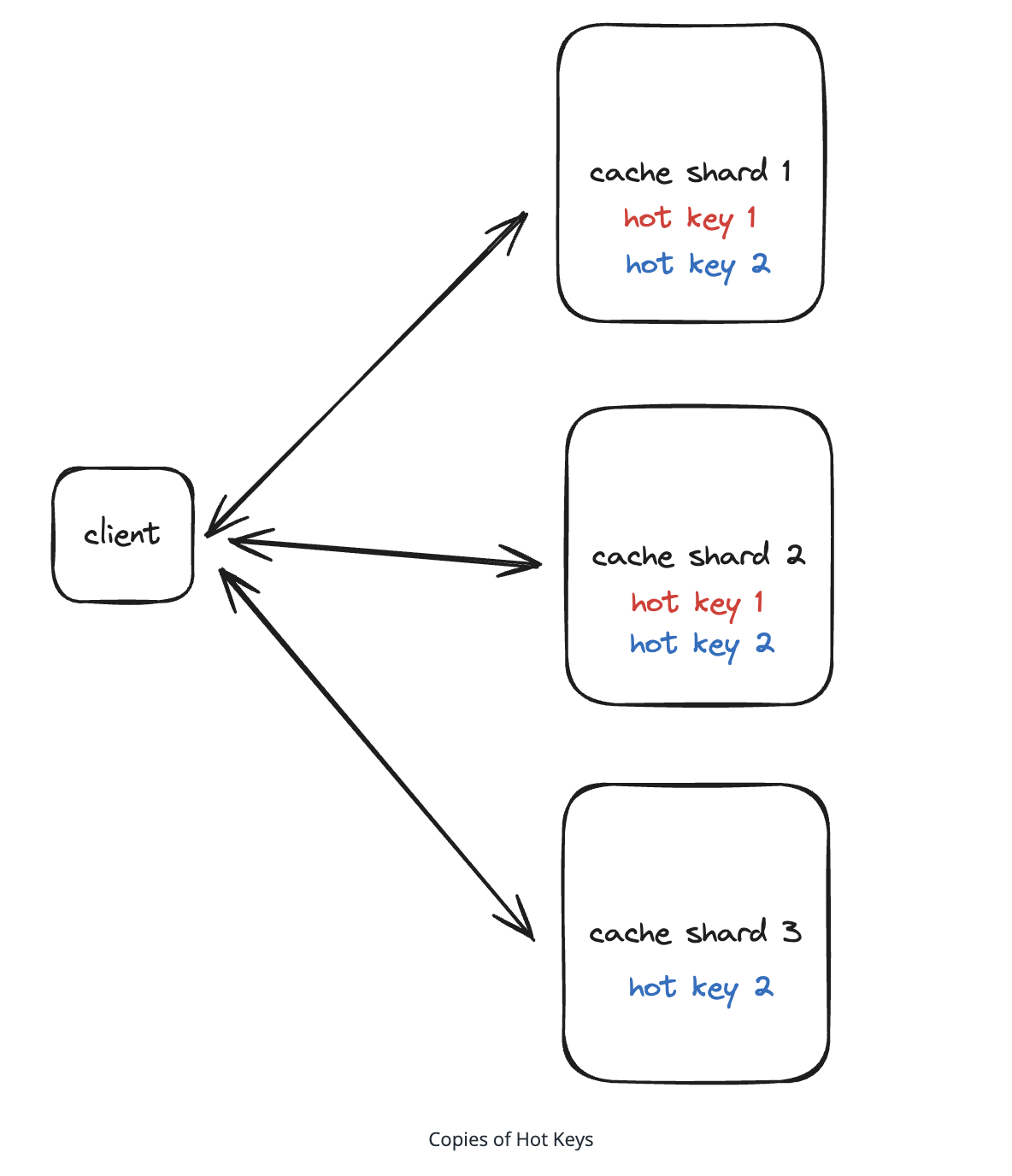
Patterns:
- user:123#1 -> Node A stores a copy
- user:123#2 -> Node B stores a copy
- user:123#3 -> Node C stores a copy
Challenges;
- The main challenge is keeping all copies in sync when data changes => manual management.
16.12. What happens if you have a hot key that is being written to a lot? (Heavy-write)
-
Key sharding takes a different approach to handling hot writes by splitting a single hot key into multiple sub-keys distributed across different nodes => Counting problem.
-
For example, a hot counter key “views:video123” might be split into 10 shards: “views:video123:1” through “views:video123:10”
-
When a write arrives, the system randomly selects one of these shards to update.
=> When reading the total value, the system simply needs to sum the values from all shards.
Challenges:
- The primary challenge with key sharding is the increased complexity of read operations, which now need to aggregate data from multiple shards.
16.23. How do we ensure our cache is performant?
- But as we grow our system into a large, distributed cache spanning dozens or even hundreds of nodes => It’s about how quickly clients can find the right node and aggreated data better.
Solution:
-
Request batching
-
Consistent Hashing.
-
Connection Pooling.
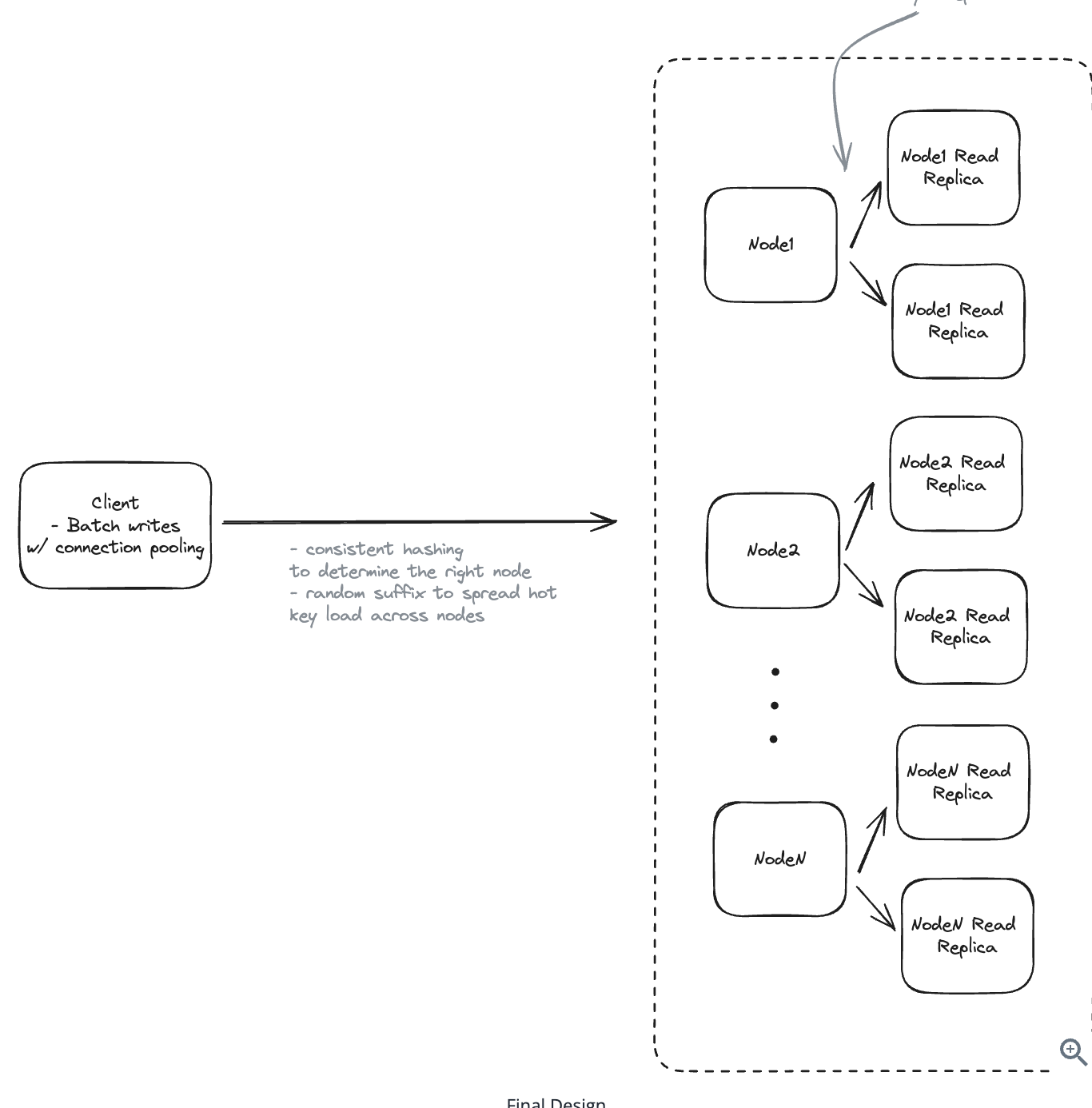
16.24. Which data structure combination enables efficient LRU cache implementation?
- Hash table and doubly linked list
16.25. All of the following improve system performance through TTL mechanisms EXCEPT:
- Guaranteed data consistency
16.26. In-memory storage provides faster access than disk-based storage systems.
- Yes
16.27. Which approach BEST handles hot keys receiving excessive read traffic?
- Create copies of hot keys across nodes
16.28. Consistent hashing minimizes key remapping when nodes are added or removed.
- Consistent hashing arranges keys and nodes on a circular space, ensuring only keys between the new/removed node and its successor need remapping.
16.29. When prioritizing availability over consistency in distributed caches, which replication approach works best?
- Asynchronous replication from primary
16.30. Connection pooling reduces network latency by eliminating connection establishment overhead.
- Yes
16.31. What does write batching accomplish in high-throughput systems?
- Reduces individual operation overhead
16.32. What happens when a cache node fails in an asynchronously replicated system?
- Write failed, data stale => but continue to read old data.
16.33. Distributed cache eviction policies must consider memory constraints to prevent system overload and maintain performance.
- Yes
16.34. For a viral content key receiving millions of reads per second, which strategy provides the most effective load distribution?
- Creating multiple copies with random suffix selection
16.35. Which approach BEST handles scaling distributed cache storage to multiple terabytes?
- Horizontal sharding across many nodes
16.36. Asynchronous replication improves write availability compared to synchronous replication approaches.
-
Asynchronous replication allows writes to complete immediately without waiting for replica confirmation, maintaining availability even when replicas are slow or unreachable
-
Synchronous replication blocks writes until all replicas confirm, reducing availability during network issues.
16.37. When should background cleanup processes run to optimize system performance?
-
Solution: When should background cleanup processes run to optimize system performance?
-
Background cleanup should run during low-traffic periods to avoid competing with user requests for CPU and memory resources.
-
It can also be triggered by memory pressure thresholds, balancing cleanup efficiency with system responsiveness to user traffic.
17. Design Web Crawler
17.1. Functional Requirements
-
Crawl the web starting from a given set of seed URLs.
-
Extract text data from each web page and store the text for later processing.
17.2. Non-functional requirements

17.3. System Interface
17.4. Create a simple outline of the data flow of the system. This is just a numbered list of steps showing how we get from the input to the output.
-
Extract text in the website.
-
Extract text in the hyperlink of the website.

17.5. What is a simple, high-level design for the system that allows us to start from seed urls and crawl the web?
-
Step 1: Using a temp queue for storing url.
-
Step 2: Pre-processing text push to S3.
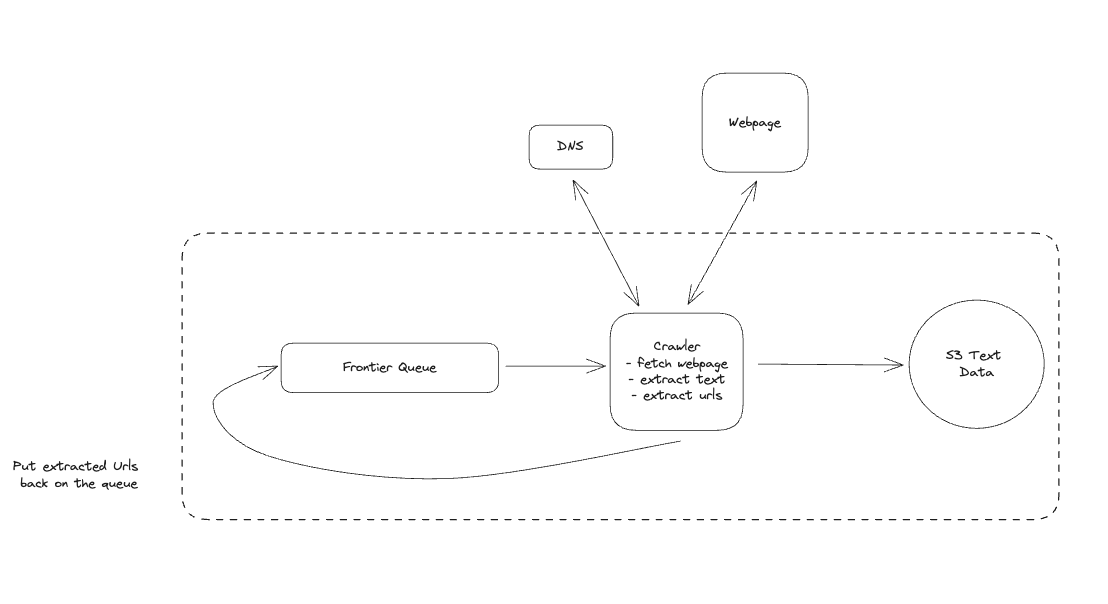
17.6. How can you ensure the system retries URLs that failed to download?
- Since SQS natively supports retries through its “visibility timeout”, we can set this timeout to something like 30 second
=> It doesn’t consume the message, another crawler will pick it up again.
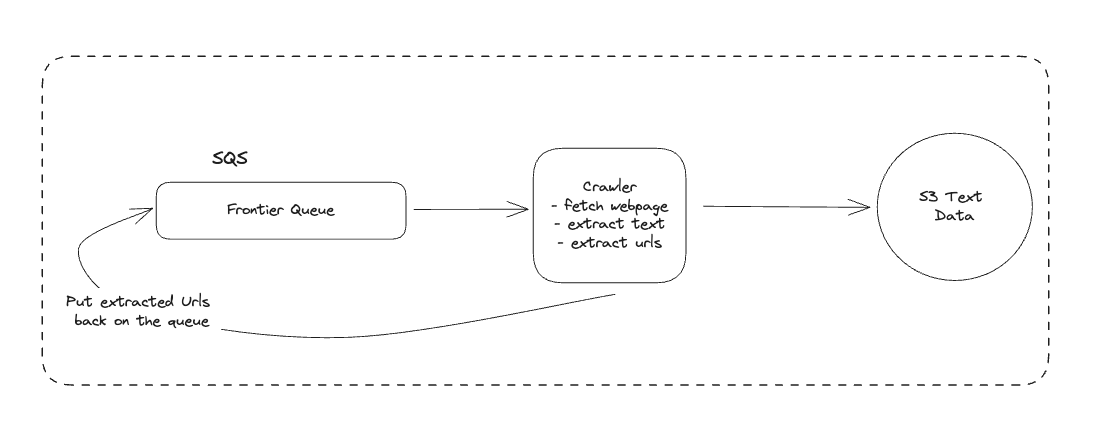
17.7. How can you ensure politeness and adhere to robots.txt?
- When a URL is first pulled, we’ll make a request to Redis to see if the robots.txt has already been pulled.
A robots.txt file is used to guide web crawlers (also known as bots or spiders) on which parts of a website they should or should not access.
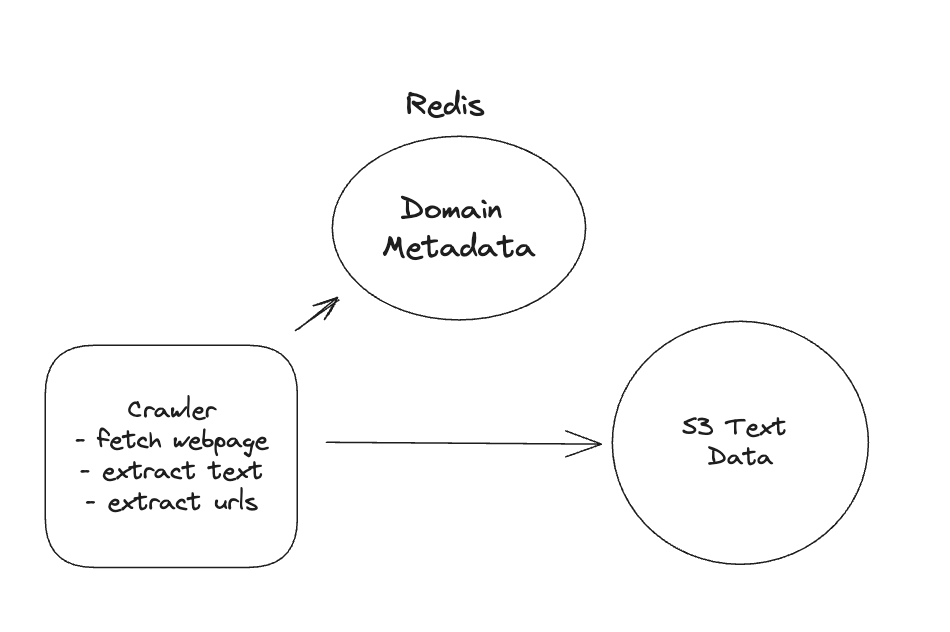
17.8. How can you avoid crawling duplicate content across different URLs?
-
To avoid processing the same page repeatedly, we can store URL metadata in a separate database.
-
If the page has already been processed before by virtue of the existing hash, we’ll skip processing it again.
17.9. How would you implement parallelization to ensure the system could efficiently crawl 10 billion pages in under 5 days? Think deeply about any bottlenecks.
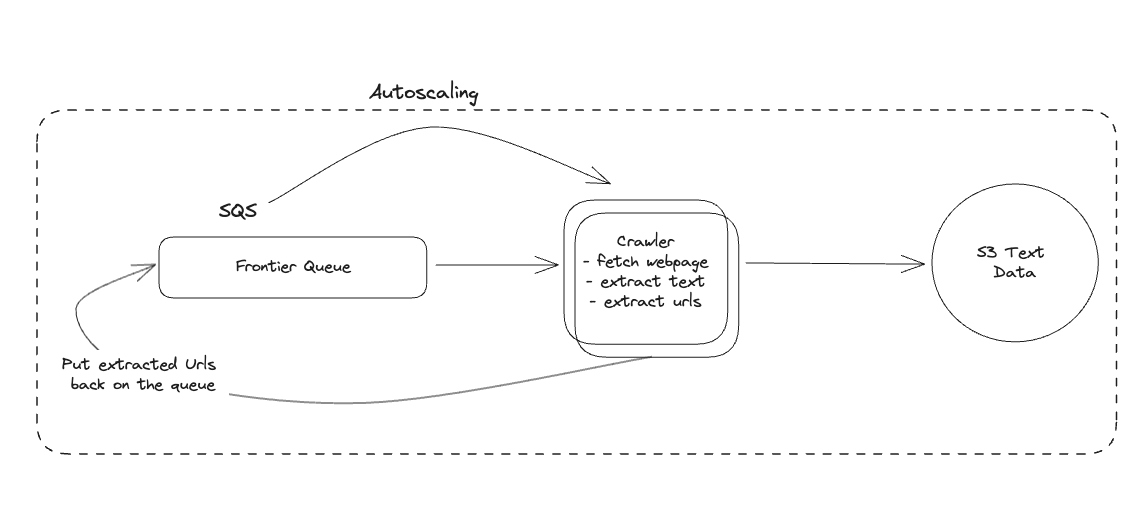
-
We aren’t wasting resources when the queue is too small
-
We can increase our crawl velocity as we go deeper into the crawl.
17.10. How would you modify the system to ensure the extracted text data remains up-to-date? Consider that we now require the data to be fresh and regularly updated.
-
Add a re-crawl cron job.
-
We may want to set a floor (say, one a quarter) where we crawl every page and then for “hot” pages which change a lot we can increase the frequency.
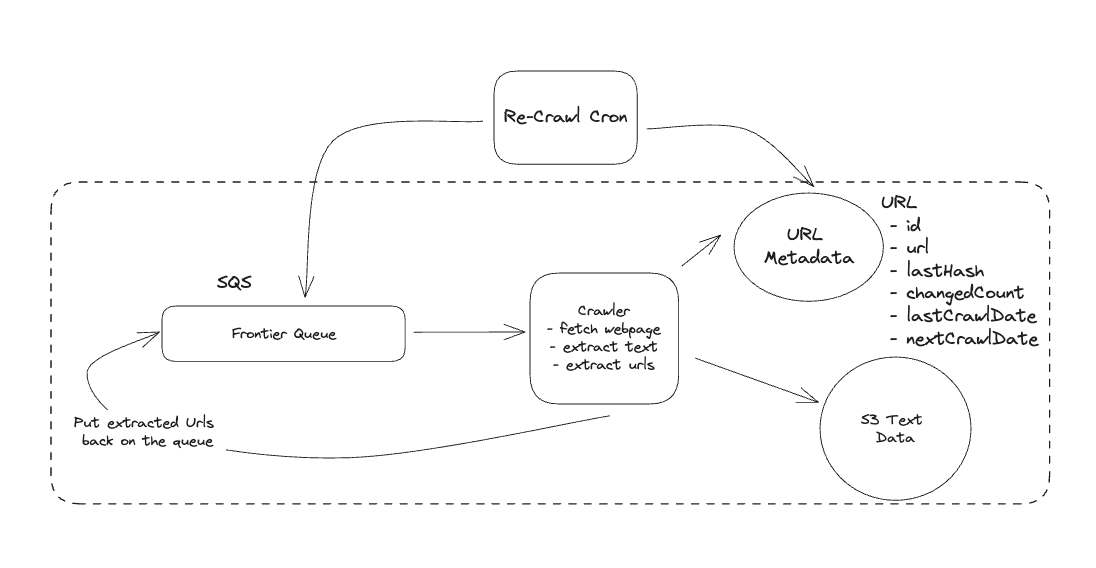
17.11. Pipeline architectures improve fault tolerance by isolating failures to individual stages.
- Yes
17.12. Which pattern ensures work is not lost when distributed workers fail unexpectedly?
-
At-least-once delivery guarantees that messages will be processed even if workers fail => make sure 100% message in kafka have been consumed.
-
The system retains messages until successful processing is confirmed, ensuring no work is lost due to failures.
17.13. Which is benefit of implementing rate limiting?
-
Prevents system overload
-
Reduces thundering herd effects: multiple jobs run the same time.
17.14. Exponential backoff reduces system load by increasing delays between retry attempts.
- Increases wait times between retries (1s, 2s, 4s, 8s…), which reduces load on failing systems and gives them time to recover.
17.15. Which SQS feature allows messages to become available again when workers fail during processing?
-
Visibility timeout
-
Dead letter queue: message consume many times but not success => add to dead letter queue.
17.16. Which approach works BEST for detecting duplicate content across different URLs?
- Using Content hashing: creates unique fingerprints of page content
17.17. A system processes millions of network requests per second. Which factor limits throughput?
- Network bandwidth
17.18. Bloom filters can produce false positives but never false negatives.
- Yes
17.19. Which technique prevents DNS resolution from becoming a system bottleneck?
Problems: DNS Resolver overload.
- DNS caching stores resolved IP addresses locally, eliminating repeated lookups for the same domains
=> Query IP in local browser/cache first, move to DNS later.
17.20. Robots.txt files specify both allowed pages and crawl delay requirements.
- Yes.
17.21. Which does prevent synchronized behavior in distributed rate limiting?
-
Add Random jitter: Add random deplay for the requests.
-
Using sliding windows
-
Implement backoff strategies.
17.22. What happens when a SQS queue’s visibility timeout expires during processing?
- Message becomes visible to other workers
17.23. Which strategy BEST prevents crawlers from getting stuck in infinite loops?
- Maximum crawl depth => Do not query hyperlinks forever.
17.24. Bandwidth limitations typically determine crawler throughput in I/O intensive web crawling systems.
-
Drawbacks: I/O Bound and network bandwidth.
-
Advantages: CPU and memory not the problems.
17.25. What should happen to messages that fail processing repeatedly in messaging systems?
- They are moved to a dead letter queue
18. Salary Negotiation
18.1. Recruiter has a approved salary, above than first offer
-
If you accept immediately, you have almost certainly not reached the “best and final” offer.
-
Try to find another allowed offer.
18.2. Silence can signal disinterest
-
Deal to show that you are find it interest.
-
Deal to shows enthusiasm and loyalty.
18.3. Not negotiating undermines your future leverage
-
Your starting point shapes future raises.
-
Negotiation is about more than this offer. It’s about anchoring your value for the long run.
18.4. What would jeopardize my offer?
Talking Numbers Too Soon
- Get more information before talks about the offers.
Inconsistent Storytelling
- Peg your decisions to a data-backed narrative and stick to it.
Negotiating with the Hiring Manager
-
The hiring manager has already championed you
-
Use HR to protect you, voice about your offers.
Ignoring Non-Cash Levers
- Think about benefits, profits above the money.
Accepting too quickly
- Kindly express your excitement and gratitude, but ask to take time to process and digest the offer
18.5. The Offer Negotiation (step-by-step) & How We Can Help
Step 1: Passing Interviews
Step 2: Team Matching
Step 3: Moving to Offers
Step 4: Recruiter Compensation Call
- Because HR have a pressure to finish the offers on-time => Make them become friends.
Step 5: Verbal Offer
-
Base Salary.
-
Equity.
-
A sign-on bonus
Step 6: Counter Offer
- Use markers like current compensation, competitive offers, even equity or bonuses left behind to drive your offer higher => Show that you are do not comfortable with a lower number.
Written Offer
- It is much easier to make changes BEFORE the written offer letter is signed.
19. Knowing Who You’re Talking To
19.1. Hiring Manager
=> Make they trust you.
- The more certain the hiring manager feels about you, the more they will be willing to exercise any influence they have with finance.
Feel Free to Ask: Questions about roles and responsibilities, scope and influence, or even current and future roadmap. Keep it specific to day-to-day and career focus.
19.2. Recruiter
- They have KPIs attached to the number of closed candidates in a given quarter, half, or year; they are also judged on their offer-to-close ratio
=> They protect the candidates => Get their trust.
19.3. Finance Team
- They fallback on market data and established pay bands.
=> Use the salary, payroll to convince them.
20. Compensation Breakdown
20.1. Base Salary
- Fixed cost of the company + benefits (stocks, facilities)
20.2. Equity
-
Stocks
-
Equities is a broader term that includes all types of ownership interest in publicly traded companies
20.3. Sign-On Bonus
- Bonus, Relocation fee or insurance inadequacies
20.4. Performance Bonus
- Performance Bonus is a yearly sum earned on top of base salary.
21. How to Negotiate
21.1. Assess Your Position
- Know who you are in the market => What is your value.
21.2. Introduce a Competitor
- Use your old company as a competitor.
21.3. Tell a Consistent Story
- Tell a consistent story for recruitment => recruitment will deal with finance team.
22. Behavioural Interview
22.1. Conflict Resolution
-
Disagreed with leaders/collegers.
-
What do you priority.
22.2. Perseverance
-
You had to push through setbacks
-
You refused to give up despite challenges
22.3. Adaptability
-
Everything changed unexpectedly.
-
You worked outside your comfort zone.
-
You had to be flexible with your approach.
22.4. Growth
-
You made significant mistakes
-
You received tough feedback and learning from feedback.
22.5. Collaboration
-
You built bridges between groups.
-
You helped others succeed
22.6. Results
-
Performance Imrpovement.
-
You get kudos from your managers and peers.
-
You created something net-new
-
You created a tool that solved a problem for you or your team
-
You released something which users loved
23. Conflict Resolution
-
Did you clearly identify who was involved and what they wanted?
-
Did you explain what caused the conflict at its core?
-
Did you describe your specific role (participant, mediator, observer)?
-
Did you demonstrate active listening and empathy?
-
Did you explain how the conflict was resolved?
-
Did you reflect on what you learned?
-
Did you focus on facts rather than emotions?
-
Did you try to understand the other person’s perspective?
-
Did you take initiative to help resolve the conflict?
-
Did you help find middle ground?
-
Did you use data to support your position?
-
Did you focus on strategic approaches to resolution?
-
Did you demonstrate influence and consensus-building?
-
Did you achieve measurable business outcomes?
-
Did you address conflicts affecting multiple teams/departments?
-
Did you influence senior stakeholders effectively?
-
Did you identify and address systemic causes?
-
Did you have an effective mental model of your counterparty?
-
Did you focus on resolving interpersonal conflicts within your team and improving team dynamics?
-
Did you help coach team members to navigate their own conflicts (vs triangulating them)?
-
Did you reach a conclusion which built trust and respect between parties while also keeping the organization’s goals in mind?
24. Perseverance
-
Did you clearly define the challenge or obstacle faced?
-
Did you explain why perseverance was required (complexity, failures, resistance)?
-
Did you demonstrate repeated efforts and refusal to give up?
-
Did you show how you adapted your approach based on feedback?
-
Did you highlight determination and resourcefulness?
-
Did you focus on the process, not just the outcome?
-
Did you demonstrate self-awareness about strengths/weaknesses?
-
Did you highlight specific actions taken to overcome the challenge?
-
Did you focus on concrete steps rather than just general effort?
-
Did you show how you adapted your approach based on results and feedback?
-
Did you demonstrate initiative in finding solutions?
-
Did you effectively communicate progress and setbacks?
-
Did you tackle a complex, long-term challenge with significant business consequences?
-
Did you demonstrate data-driven decision making and resourcefulness?
-
Did you show leadership in guiding others through difficulties?
-
Did you address challenges requiring long-term commitment and strategic thinking?
-
Did you maintain momentum despite significant obstacles?
-
Did you offer sufficient context so that a 3rd party could understand the depth of the challenge?
-
Did you demonstrate organizational influence and resilience?
-
Did you describe a challenge you faced in managing your team (e.g., performance issues, resource constraints)?
-
Did you show how you supported your team members through difficult situations?
25. Adaptability
-
Did you clearly describe what changed or what disruption occurred?
-
Did you explain why adaptation was necessary?
-
Did you demonstrate quick assessment and decision-making?
-
Did you show how you adjusted your plans or approach?
-
Did you demonstrate flexibility and open-mindedness?
-
Did you explain how your adaptability affected the outcome?
-
Did you reflect on lessons learned about handling change?
-
Did you show willingness to learn new approaches?
-
Did you maintain productivity despite changes?
-
Did you effectively reprioritize tasks when needed?
-
Did you clearly communicate changes to the team?
-
Did you help others adapt to changes?
-
Did you lead the team’s response to major, unexpected changes?
-
Did you demonstrate rapid decision-making and effective communication?
-
Did you show how you influenced team adaptation?
-
Did you lead adaptation across multiple teams?
-
Did you anticipate and mitigate potential resistance?
-
Did you offer a clear framework for making a decision and moving forward?
-
Did you demonstrate strategic thinking in managing organizational change?
-
Did you adjust your management style to meet different needs?
-
Did you effectively manage change within your team?
-
Did you support team members through transitions?
-
Did you align with the organization’s goals, even if they weren’t your top priority?
26. Growth Mindset
-
Did you describe a challenge, failure, setback, or critical feedback received?
-
Did you demonstrate willingness to learn from mistakes?
-
Did you show how you actively sought and used feedback?
-
Did you explain specific steps taken to learn new skills?
-
Did you highlight self-reflection and honest assessment?
-
Did you describe how you applied new learning?
-
Did you emphasize commitment to continuous learning?
-
Did you show a positive attitude towards challenges?
-
Did you describe a specific instance of seeking feedback?
-
Did you show how you applied that feedback concretely?
-
Did you proactively seek learning opportunities to address skill gaps?
-
Did you take initiative in your own development?
-
Did you help others learn and grow?
-
Did you describe a significant failure/setback as a catalyst for growth?
-
Did you demonstrate how you applied learning to achieve later success?
-
Did you show leadership in promoting learning culture?
-
Did you identify and address critical organizational skill gaps?
-
Did you champion a culture of learning and improvement?
-
Did you demonstrate strategic thinking about development?
-
Did you foster a growth mindset within your team?
-
Did you demonstrate continuous learning as a manager?
-
Did you effectively develop and mentor team members?
27. Leadership
-
Did you describe a situation where you took initiative and guided others?
-
Did you explain how you influenced and motivated others?
-
Did you highlight your decision-making process?
-
Did you take responsibility for outcomes?
-
Did you demonstrate ability to inspire and support team members?
-
Did you explain how you built consensus?
-
Did you show effective delegation and feedback?
-
Did you reflect on your leadership style and learnings?
-
Did you describe a situation with significant organizational impact?
-
Did you demonstrate influence without direct authority?
-
Did you show how you built and maintained high-performing teams?
-
Did you influence the strategic direction of major initiatives?
-
Did you build and maintain relationships with key stakeholders?
-
Did you demonstrate strategic thinking and negotiation skills?
-
Did you focus on coaching, mentoring, and developing team members?
-
Did you create a positive and productive team environment?
-
Did you demonstrate effective people management skills?
28. Collaboration & Teamwork
-
Did you describe a situation where you worked effectively as part of a team?
-
Did you highlight your contributions while acknowledging others?
-
Did you explain how you communicated and collaborated?
-
Did you show how you handled disagreements constructively?
-
Did you demonstrate ability to share knowledge and support colleagues?
-
Did you explain how you adapted to different work styles?
-
Did you describe the team’s overall success?
-
Did you reflect on what you learned about teamwork?
-
Did you describe your specific contributions to the team?
-
Did you show how you communicated with team members?
-
Did you help resolve team conflicts?
-
Did you contribute to improving team dynamics?
-
Did you foster cross-functional collaboration for strategic goals?
-
Did you break down silos across organizational boundaries?
-
Did you demonstrate ability to influence across functions?
-
Did you facilitate collaboration within and between teams?
-
Did you create structures for effective teamwork?
-
Did you show evidence of uncovering the root cause of collaboration issues?
29. Task Scheduler (Bill Problem)
29.1. Context
- Task: A task is the abstract concept of work to be done.
- Job: A job is an instance of a task.
29.2. Functional Requirements
-
Users should be able to schedule jobs to be executed immediately, at a future date, or on a recurring schedule (ie. “every day at 10:00 AM”).
-
Users should be able monitor the status of their jobs.
29.3. Non-Functional Requirements
- The system should be highly available (availability > consistency).
- The system should execute jobs within 2s of their scheduled time.
- The system should be scalable to support up to 10k jobs per second.
- The system should ensure at-least-once execution of jobs.
29.4. Entities
-
Task: Represents a task to be executed.
-
Job: Represents an instance of a task to be executed at a given time with a given set of parameters.
-
Schedule: Represents a schedule for when a job should be executed, either a CRON expression or a specific DateTime.
-
User: Represents a user who can schedule jobs and view the status of their jobs.

29.5. Data Flow
-
A user schedules a job by providing the task to be executed, the schedule for when the task should be executed, and the parameters needed to execute the task.
-
The job is persisted in the system.
-
The job is picked up by a worker and executed at the scheduled time. If the job fails, it is retried with exponential backoff.
-
Update the job status in the system.
29.6. Users should be able to schedule jobs to be executed immediately, at a future date, or on a recurring schedule
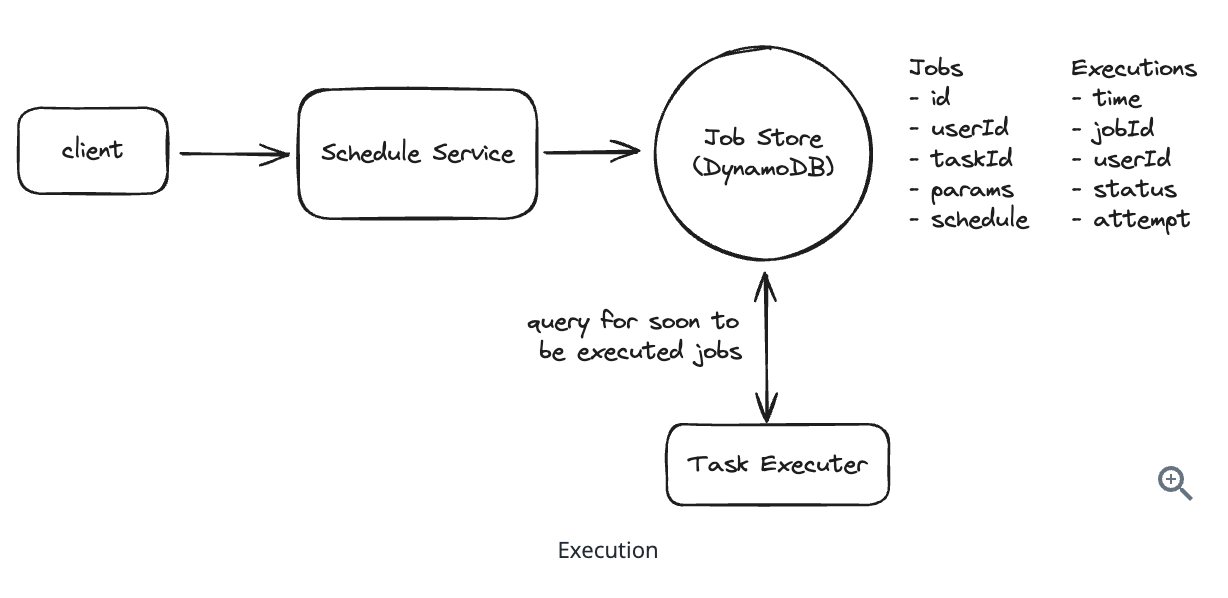
29.7. Users should be able monitor the status of their jobs.
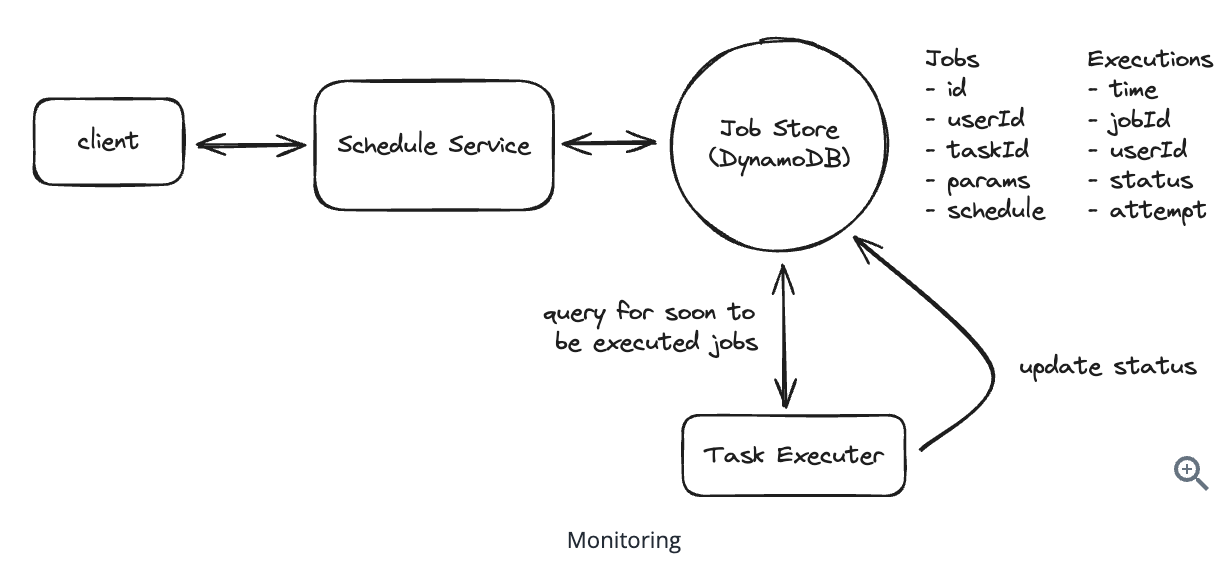
29.8. How can we ensure the system executes jobs within 2s of their scheduled time?
- Delayed message delivery: When on-time, the jobs is executed
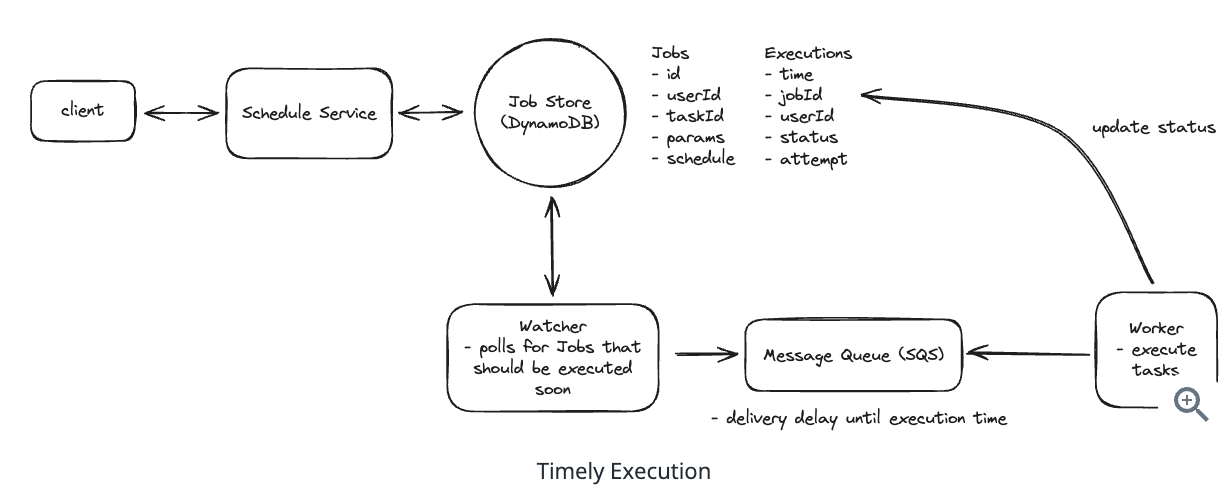
29.9. How can we ensure the system is scalable to support up to 10k jobs per second?
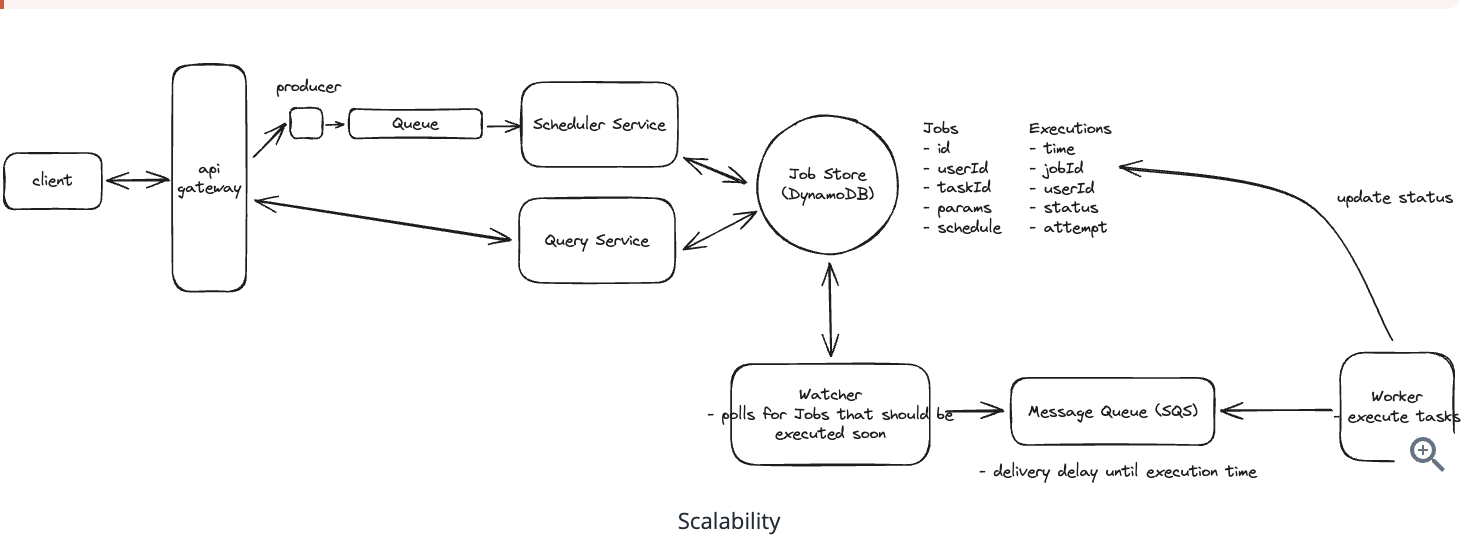
29.10. How can we ensure at-least-once execution of jobs?
-
SQS Visibility Timeout: Else, another consumer will consume this queue.
-
Visibility timeout: visibility timeout is the time period a message becomes invisible to other consumers after being received by one
-
Usage: prevents multiple consumers from processing the same message at the same time.
-
Delay queues: a message is hidden when it is first added to queue, until the time it is visibility.
29.11. Worker failure detection systems must balance detection speed against false positive rates.
-
Fast failure detection => network delays.
-
Slow detection => delays recovery.
29.12. What is the primary purpose of visibility timeouts in message queues?
- Visibility timeouts make messages invisible to other workers when consumed => then automatically make them visible again if not deleted within the timeout period.
=> This mechanism detects worker failures without requiring explicit health checks or coordination.
29.13. Which property makes message queues suitable for handling traffic spikes in distributed systems?
- Buffering and decoupling producers from consumers
=> Allowing producers to continue sending messages even when consumers are temporarily overwhelmed.
29.14. Separating job definitions from execution instances enables efficient recurring task management.
- For recurring tasks, the template stays constant while new execution records are created for each occurrence, avoiding data duplication and enabling efficient querying.
29.15. Which architecture BEST achieves sub-second job execution precision at scale?
Two-phase: periodic querying plus priority queue
-
Periodic database queries (every few minutes) load upcoming jobs into a priority queue
-
Execute jobs with sub-second precision without overwhelming the database.
29.16. Time-based database partitioning optimizes queries for recently scheduled jobs.
-
Yes. Time-based partitioning places jobs scheduled around the same time in the same partition.
-
Since job schedulers primarily query for upcoming jobs, this strategy ensures most queries hit only 1-2 partitions.
29.17. When a worker processing a 5-minute job crashes after 30 seconds, what determines retry timing?
-
The message queue’s visibility timeout
-
If set to 60 seconds, other workers can pick up the job within 60 seconds of the original worker’s failure and try again.
29.18 (Hay). In an at-least-once execution model, job operations should be idempotent to avoid duplicate side-effects.
-
At-least-once delivery means jobs may execute more than once due to retries or failures
-
This prevents issues like double-billing or inconsistent state when jobs are retried.
29.19. What does exponential backoff prevent in job retry systems?
- Exponential backoff increases delay between retries (1s, 2s, 4s, 8s…), preventing failing jobs from overwhelming system resources
29.20. What happens when a worker fails to renew its job lease before expiration?
-
Lease-based coordination prevents multiple workers from processing the same job simultaneously.
-
Other workers can claim the job
29.21. Job scheduling systems requiring 2-second execution precision should not rely solely on database polling mechanisms.
- Database polling every 2 seconds at scale would be inefficient and imprecise due to query latency, processing time, and network delays.
=> Using period polling + priority queue.
29.22. What is the primary advantage of separating recurring job definitions from their execution instances?
- Enables efficient querying of upcoming jobs
=> Querying execution instances rather than processing all job definitions.
29.23. Which approach BEST handles scaling job processing to 10,000 jobs per second?
- Container-based async worker pool with auto-scaling groups
29.24. Two-phase scheduling architectures trade database query frequency for execution timing precision.
-
Pooling
-
Priority queue
=> Limit the total jobs.
29.25. When background job sync operations consume excessive database resources, which optimization works best?
- Read replicas allow sync operations to query separate database instances without impacting primary database performance.
30. Design Yelp
30.1. Requirements
-
Users should be able to search for businesses by name, location (lat/long), and category
-
Users should be able to view businesses (and their reviews)
-
Users should be able to leave reviews on businesses (mandatory 1-5 star rating and optional text)
30.2. Non-functional requirements
30.3. Entities

30.4. API Design

30.5. How will users be able to search for businesses?
30.6. How will users be able to view a businesses details and reviews?
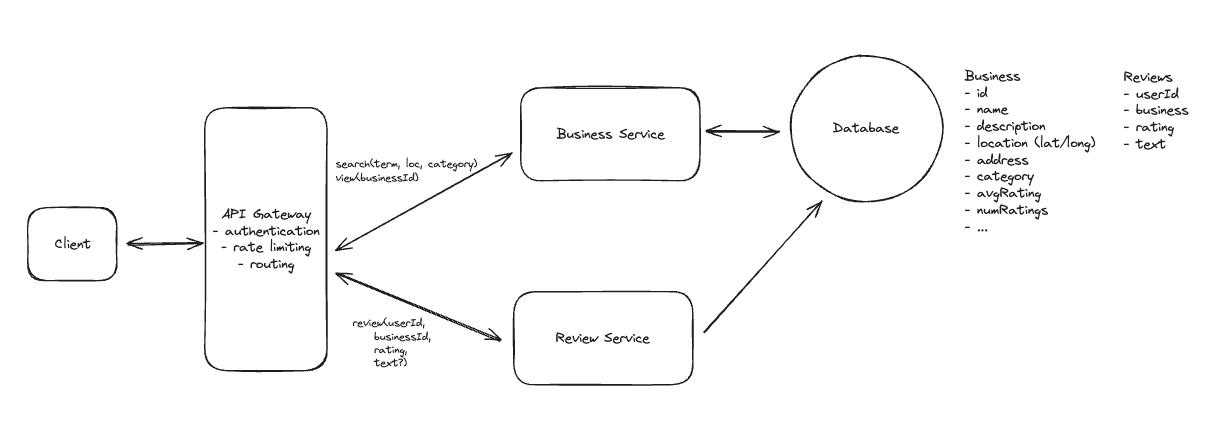
30.7. How will users be able to leave reviews on businesses?
30.8. How would you efficiently calculate and update the average rating for businesses to ensure it’s readily available in search results and still accurate up to the minute?
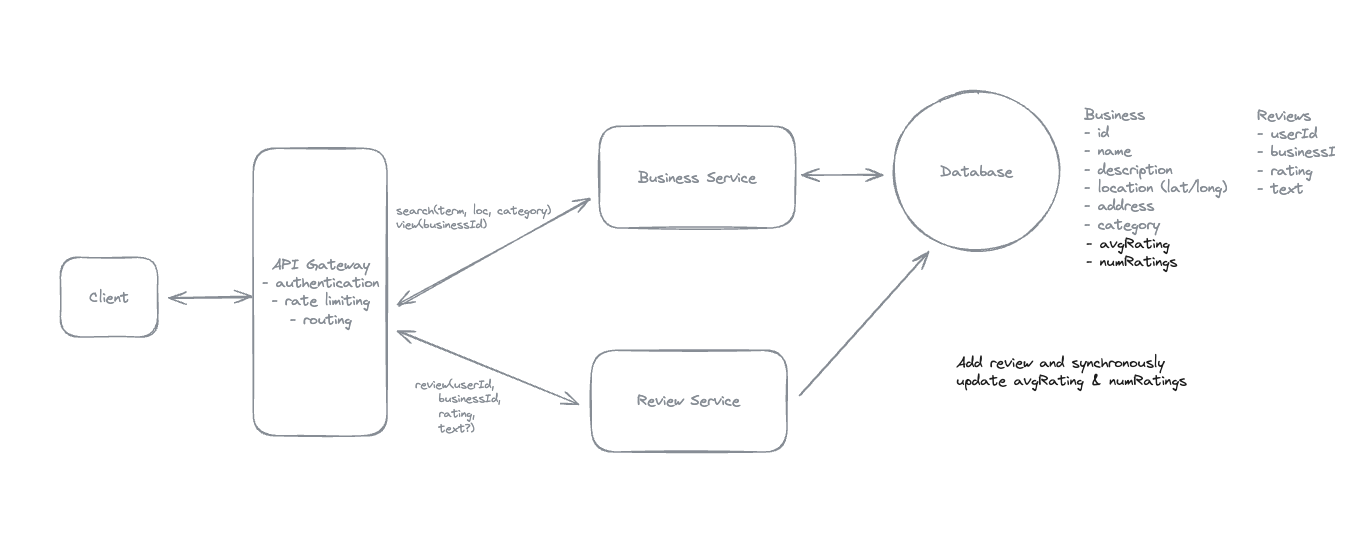
30.9. How would you modify your system to ensure that a user can only leave one review per business?
- Using composite key: businessId and userId
30.10. How can you improve search to handle complex queries more efficiently?
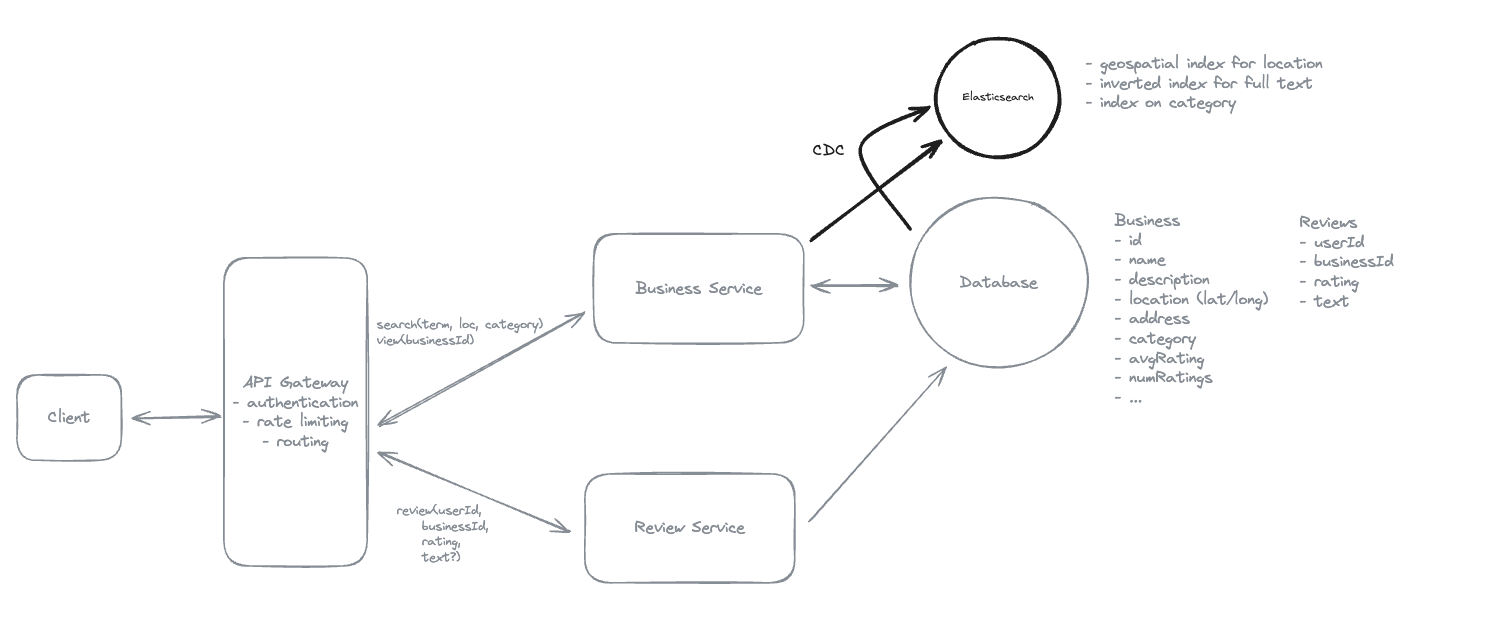
30.11. How would you modify your system to allow searching by predefined location names such as cities (e.g., ‘San Francisco’) or neighborhoods (e.g., ‘Mission District’)? Assume you have a finite list of supported location names.
-
We’ll use a pre-computed location matching system. These polygons accurately represent the geographical areas of each location
-
When a user searches for a location, we simply match against these pre-computed location strings.
30.12. What occurs when optimistic locking detects concurrent modifications?
- Transaction rolls back
30.13. When implementing a constraint that users can only leave one review per business, which approach provides the strongest data integrity guarantee?
- Use a unique database constraint on (user_id, business_id)
30.14. B-tree indexes efficiently handle two-dimensional geographic range queries.
- False, use R-trees or quadtrees
30.15. When designing a system that needs to handle location-based searches, text searches, and category filtering simultaneously, what is the primary limitation of using traditional B-tree indexes?
- B-tree indexes are optimized for single-dimension queries but struggle with multi-dimensional spatial data
30.16. Using a cron job to periodically update business average ratings provides real-time accuracy for users viewing search results.
-
When a user leaves a new review, the average rating won’t be updated until the next scheduled cron job runs
-
For real-time accuracy, synchronous updates or near-real-time processing would be required.
30.17. A system processes 1000 reads per write. Which architecture pattern fits best?
- Read replicas with caching
30.18. Using a message queue to handle review submissions is necessary when the system processes 100,000 review writes per day.
- 100,000 writes per day equals approximately 1 write per second => Do not need to use message queue to low bandwidth.
30.19. All these techniques prevent inconsistent aggregate calculations
-
Database transactions
-
Optimistic locking
-
Atomic operations
-
Periodic batch updates: can lead to stale data.
30.20. When queries filter by text, location, and category simultaneously, what works best?
-
Inverted indexes: text.
-
Spatial indexes: location (R-Tree, QuadTree).
-
B-trees indexes: categories.
30.21. PostGIS extension allows PostgreSQL to efficiently handle geospatial queries without requiring a separate search service like Elasticsearch.
- Yes.
31. Design Strava
31.1. Context:
- Fitness Tracking App
31.2. Functional Requirements

31.3. Non-functional Requirements

31.4. Entities

31.5. API Design

31.6. How will users be able to start, pause, stop, and save their runs and rides?
31.7. How can users view live statistics from their current activity while running/cycling?
- The client app leverages the device’s GPS to record the user’s location at intervals (e.g., every 5 seconds) and send these updates to the server which adds new rows to our Route table for each new coordinate.
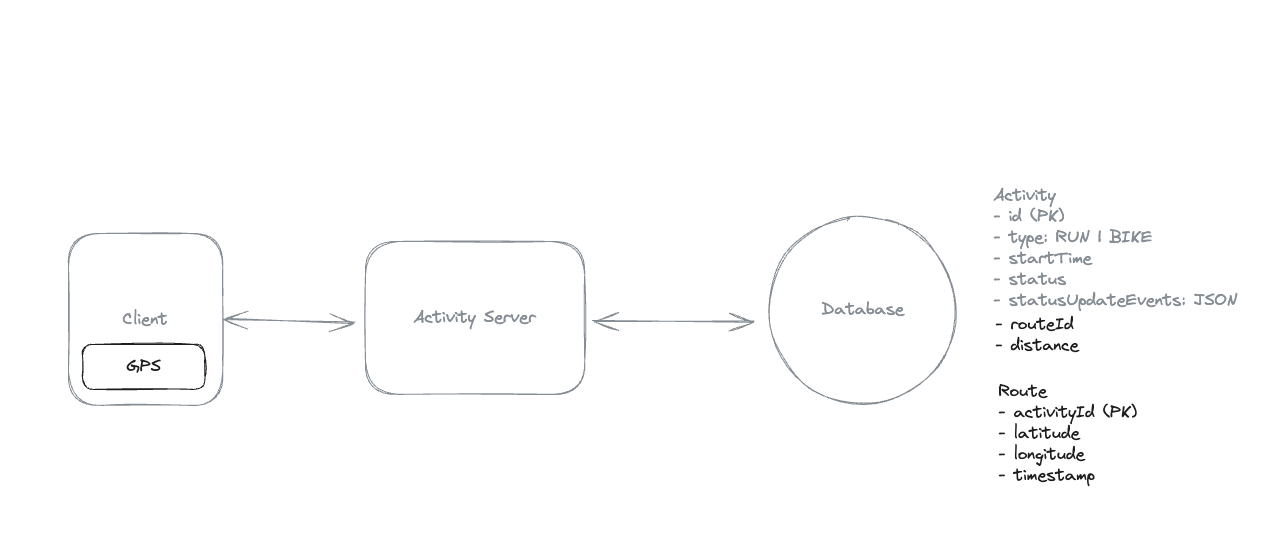
31.8. For a long bike ride in particular, recalculating the total distance based on the route can get expensive. How can you make this more efficient?
-
To efficiently update the total distance, we’ll use an incremental approach.
-
Calculate multiple distance each time users send location updated => can calculate in the client-side.
=> Only calculate increment distance
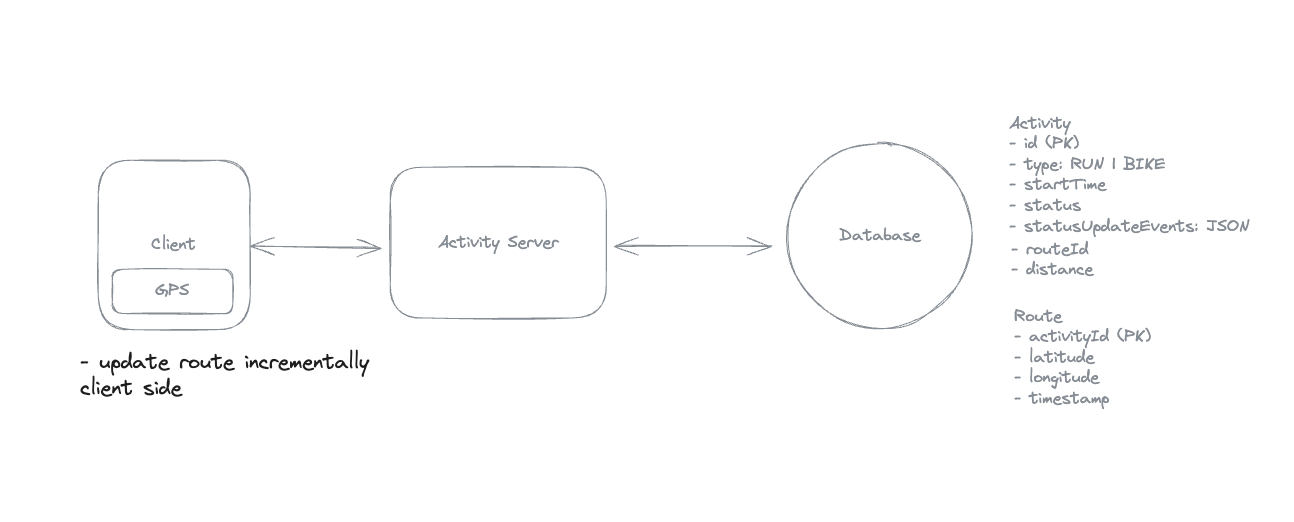
31.9. How will users be able to view details about their own completed activities as well as the activities of their friends?
- The Activity Service queries the database for activities with state ‘COMPLETE’, filtering by the user’s ID or their friends’.
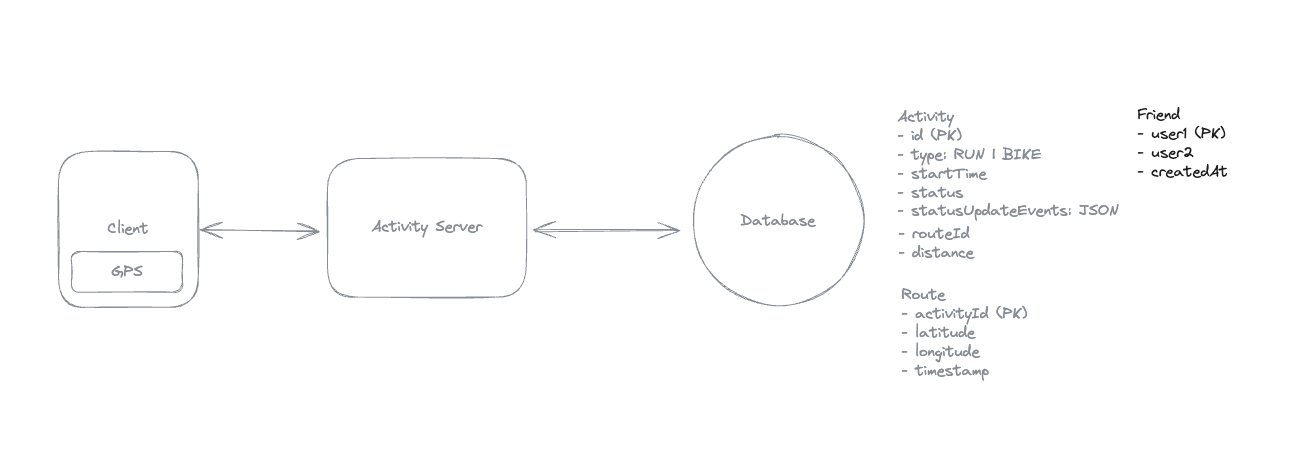
31.10. How will your system support tracking activities while the users device is offline?
-
To prevent data loss, it periodically persists this data to the device’s local storage (e.g., every 10 seconds).
-
This way, if the device turns off for any reason we can recover from device storage.
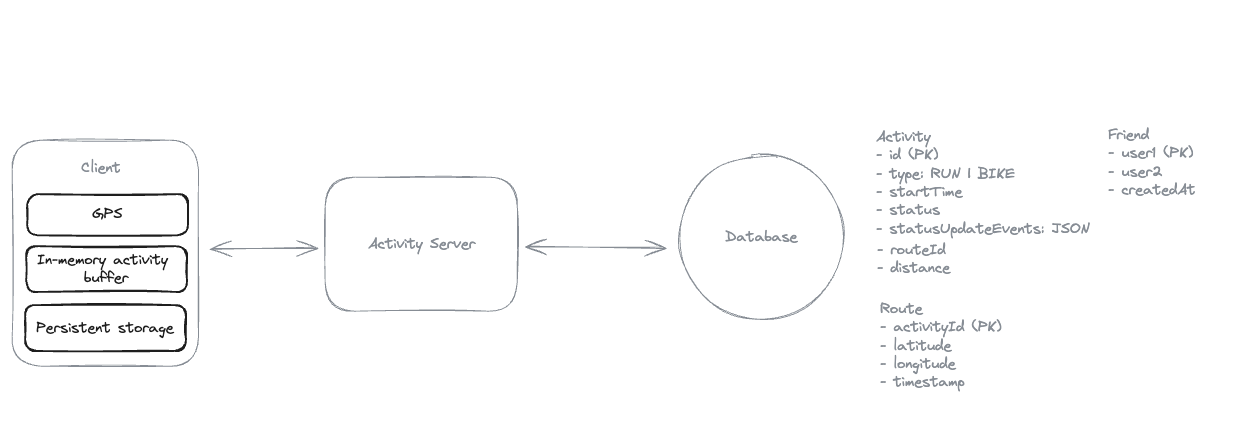
31.11. How can we support up-to-date sharing of activities with friends while the activity is in progress, not just after completion?
- Friends’ apps can implement a polling mechanism, requesting updates at the same interval, perhaps with a slight intentional delay to buffer the data.
=> Do not need to use server-side event.
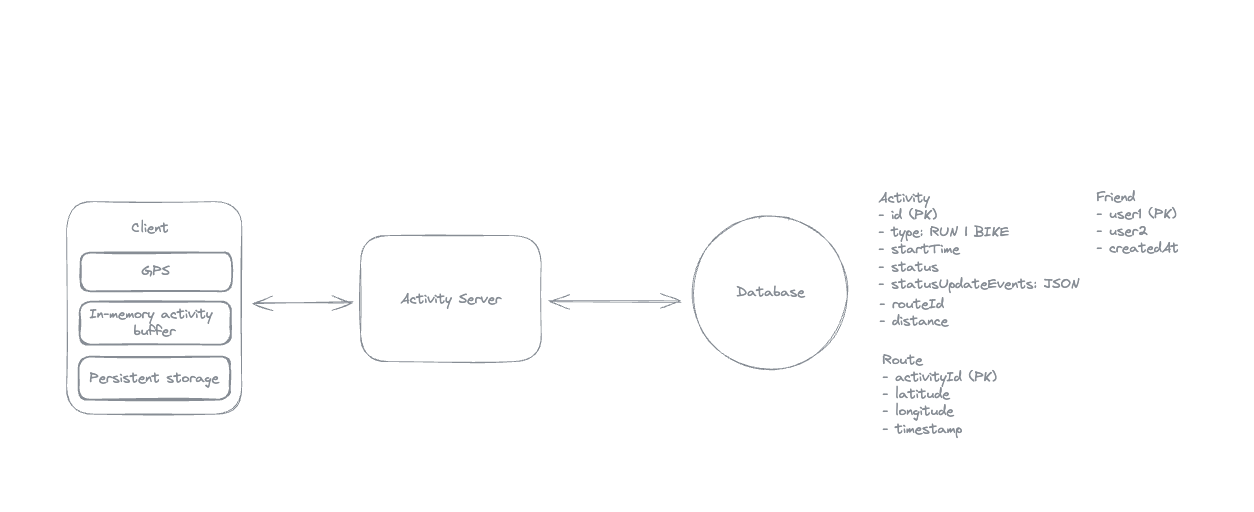
31.12. How can we expose an up-to-date leaderboard of top athletes globally based on the total distance covered?
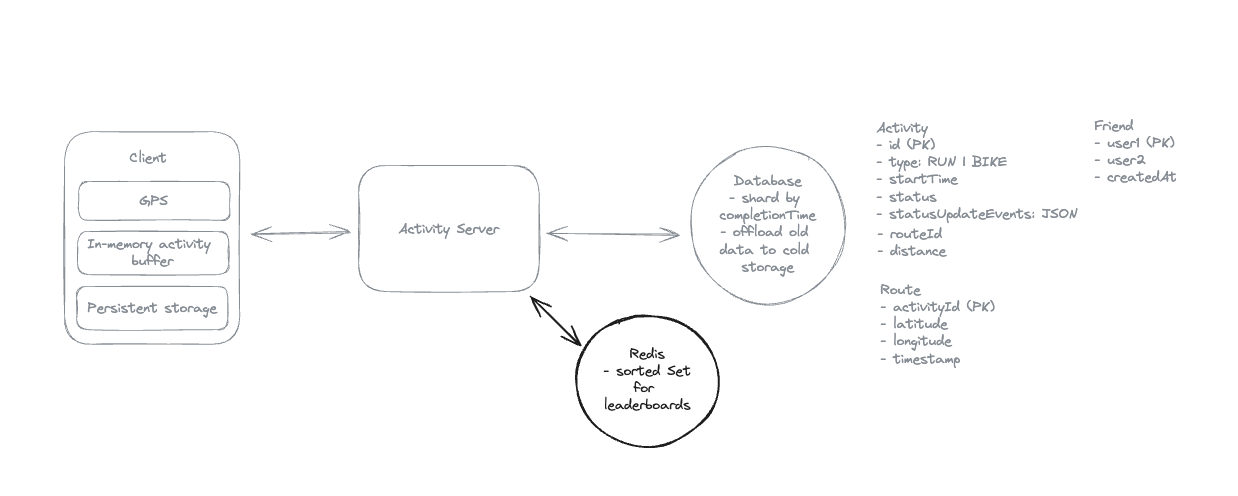
31.13. Local device buffering reduces network bandwidth consumption compared to real-time server updates.
- Local device buffering => save bandwidth.
31.14. All of the following improve offline functionality
-
Background sync mechanisms
-
Periodic data persistence
-
Local data caching
31.15. Local buffering reduces the number of network requests to servers.
- Yes
31.16. Which approach BEST handles millions of high-frequency write operations per second?
- In-memory buffering with batch writes
31.17. Storing calculated results like user totals or rankings requires additional storage but eliminates expensive real-time aggregation queries
- Yes
31.18. When updates occur predictably every few seconds, which communication pattern works best?
- Polling at update intervals
31.19. Time-based database sharding optimizes queries for recent data access patterns.
- This matches user behavior where current activities are accessed more frequently than historical data from years ago.
31.20. Which storage approach optimizes cost while maintaining performance for aging data? (Based on access and storage)
- Data tiering with hot/warm/cold levels
31.21. Database read replicas primarily improve which aspect of system performance?
- Read throughput
31.22. Activity tracking applications can function completely offline by storing GPS coordinates locally until network connectivity returns.
-
Applications can record location data, calculate distances using algorithms like Haversine formula.
-
Sync accumulated data when connectivity is restored, enabling full offline functionality.
31.23. For athlete leaderboards updated frequently, which approach balances real-time updates with system efficiency?
- Redis sorted sets with incremental updates.
31.24. Which pattern BEST enables friends to track live workout progress with minimal system complexity?
- Polling updates at predictable intervals
31.25. Batch processing reduces system resource consumption compared to processing individual operations immediately.
- Yes
31.26. Redis sorted sets enable efficient leaderboard operations because they provide which time complexity for rank retrieval?
- O(logN): for ranking.
32. Design Ad Click Aggregator (Ads Tracking)
32.1. Business Objective
-
A system that counts how many times ads placed on a website are clicked by users
-
This provides advertisers with aggregated click metrics over time to see how effective their ads are.
32.2. Functional Requirements
-
Users can click on an ad and be redirected to the advertiser’s website.
-
Advertisers can query ad click metrics over time with a minimum granularity of 1 minute.
32.3. Non-functional requirements

32.4. Entities

32.5. Input/Output:
-
Input: Ad click data from users.
-
Output: Ad click metrics for advertisers.
32.6. Data flow

32.7. Design a full, but simple, high-level design of the system that can capture and store ad click data and allow advertisers to query ad click metrics.
32.8. How would you scale the system to handle 100k clicks per second without dropping any?
32.9. How would you implement idempotent click tracking to prevent duplicate counts? You can assume all users are logged in.
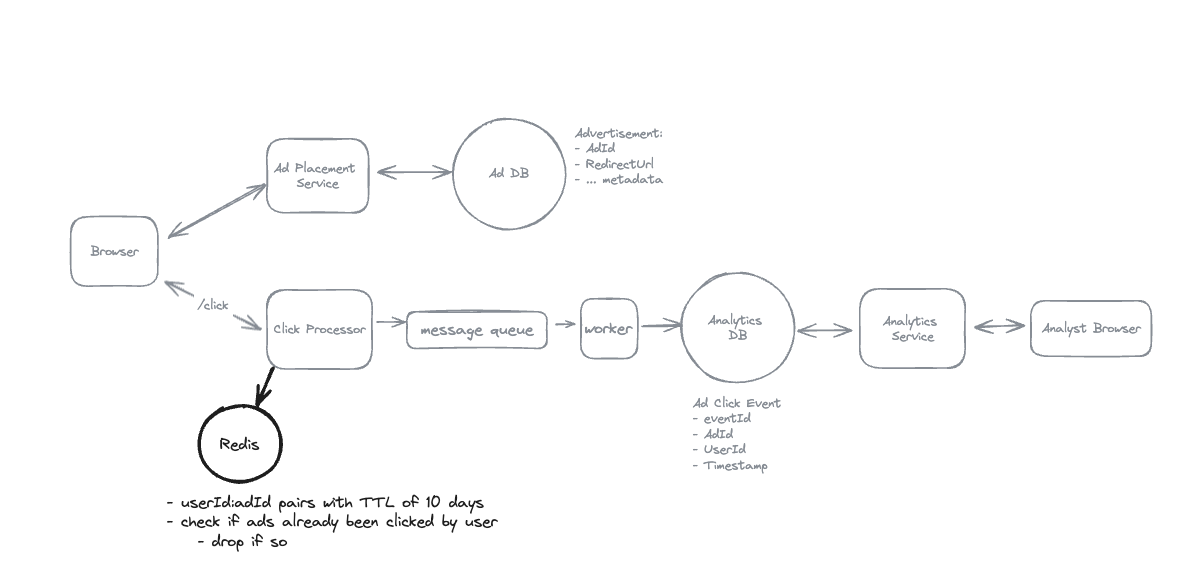
32.10. How can you ensure low latency responses for advertiser queries, especially for aggregations over large time ranges?
- Using pre-computed aggregation DB.
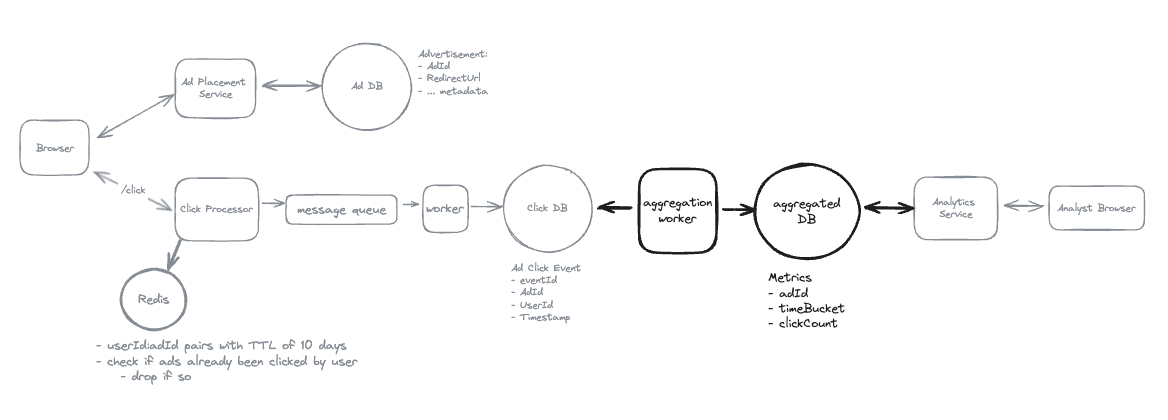
32.11. How would you handle ‘hot partitions’ for writes, where popular ads from big campaigns get clicked on a lot, potentially overwhelming parts of the system?
-
Hotpot problems.
-
Split multiple partition in Kafka: ads_123:1, ads_123:2,…ads_123:10.
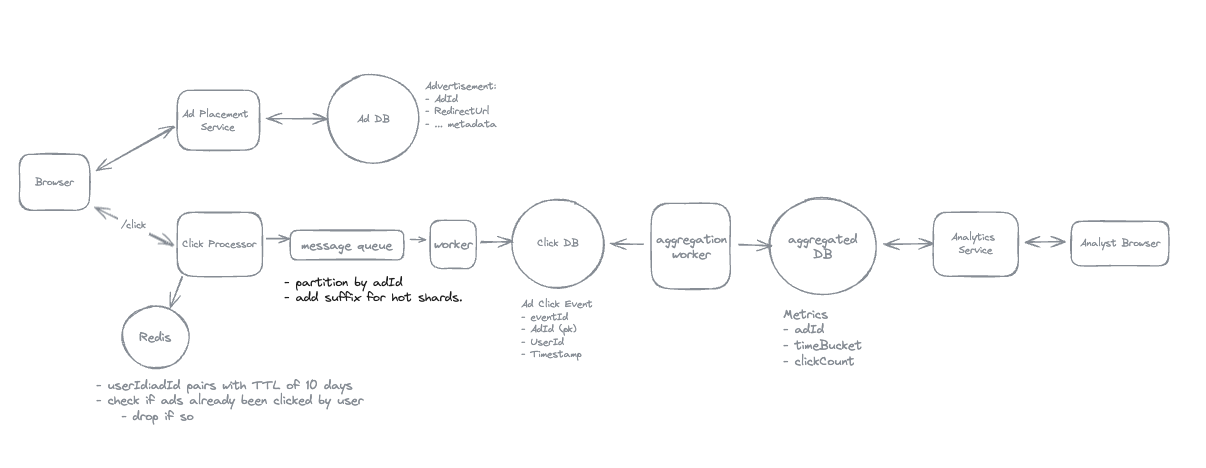
32.12. How would you evolve your system to allow advertisers to query for click data in near real-time (<5s)?
- Integrate with Kinesis and Flink for process faster, due to paralel computing.
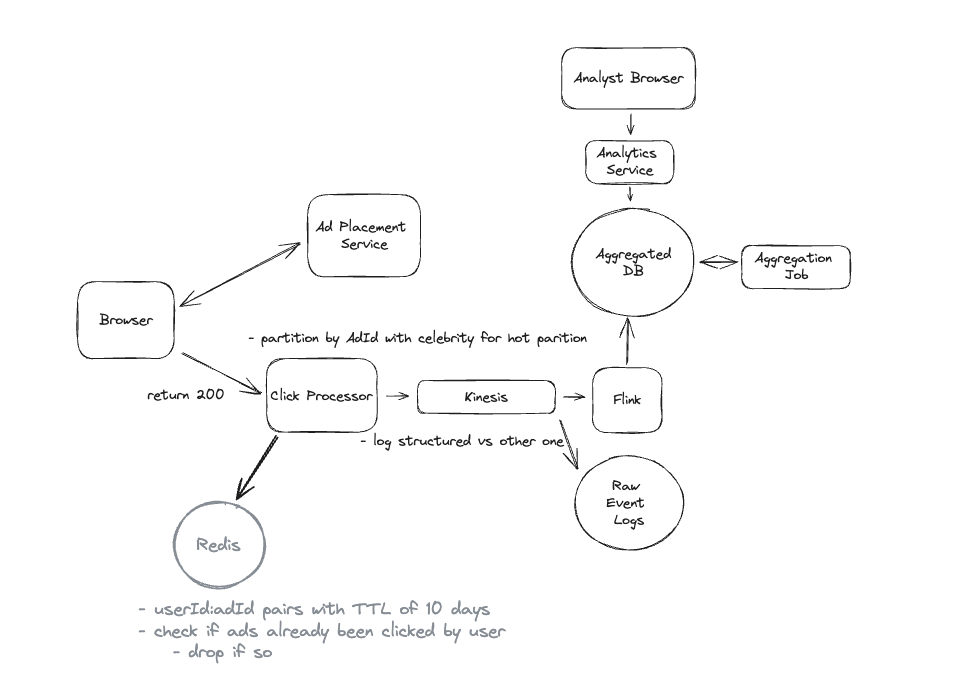
32.13. LSM-based storage systems optimize for write performance over read performance.
- LSM (Log-Structured Merge): writing data sequentially to logs before merging => Because linear read required O(N^2).
32.14. Which processing model provides the lowest latency for real-time analytics?
- Stream processing
32.15. Checkpointing becomes less valuable when stream processing uses very small aggregation windows.
- With small aggregation windows (like 1 minute), the overhead of checkpointing state may exceed the cost of re-processing lost data from the stream.
32.16. Which best describes Apache Flink?
- A real-time stream processing engine
32.17. Idempotent operations can be executed multiple times without changing the result.
- True
32.18. A system needs sub-second analytics on streaming data. Which approach is most suitable?
- Real-time stream processing: processing data as it arrives.
32.19. What causes hot partitions in distributed systems?
- Uneven data distribution: Hot partitions occur when data is unevenly distributed across nodes, causing some partitions to handle disproportionately more load than others.
32.20. Time-based windowing in stream processing groups events by temporal boundaries.
- Time-based windowing groups streaming events into fixed time intervals (like 1-minute windows), enabling temporal aggregations and analytics.
32.21. What happens when map-reduce jobs process data in parallel across multiple nodes?
- Processing time decreases
32.22. Which is NOT a characteristic of eventual consistency models?
- Can not immediate consistency
32.23. Distributed systems achieve fault tolerance by replicating data across multiple nodes.
- Yes.
32.24. Which strategy BEST prevents hot spots when partitioning high-frequency data?
- Adding random suffixes to hot keys => multiple partitions.
32.25. When real-time and batch processing produce different results, which approach ensures correctness?
-
Reconciliation with authoritative batch results
-
Batch processing typically has more complete data and fewer real-time constraints > might be more accuracy.
32.26. Kafka can function as both a message queue and a streaming platform.
-
Message Queue: Producer, Consumer.
-
Streaming Platform: Kafka Streams, like Flink
33. Machine Learning System Design
33.1. Types of design
- ML Infra Design
- Create a feature store for a large-scale ML platform.
- Design a model serving system that can handle millions of requests per second.
- Applied ML System Design
-
Design a recommendation system for an e-commerce platform
-
Build a fraud detection system for a financial service
- AI/ML Research Engineering
- Implementing and optimizing research papers
- AI/ML Research
- Deep learning architectures and their mathematical foundations
33.2. Interview Assessment
Step 1: Navigation Problem, find the right metrics.
Step 2: Input Data, Features, and Labels => improve by feedback loop, have stronger hypotheses about what data is important
Step 3: Model Design
Step 4: Integration and Evaluation
34. ML Framework
34.1. Clarify the Problem
For example, if you’re asked to design a recommendation system for an e-commerce platform
=> You might ask about the size of the product catalog, the number of daily active users, where the recommendations will be shown, what the latency requirements are, and whether there exists a current system in place.
34.2. Establish a Business Objective
-
The key is to be specific about what success looks like from a business perspective.
-
In most ML teams, and especially in big companies, teams will spend years working on optimizing a fairly narrow business objective.
34.3. Decide on an ML Objective
- For our e-commerce recommendation system, the ML objective might be to build a ranking model that predicts the probability of a user purchasing a product given their browsing history and other contextual information
34.4. High-level Design
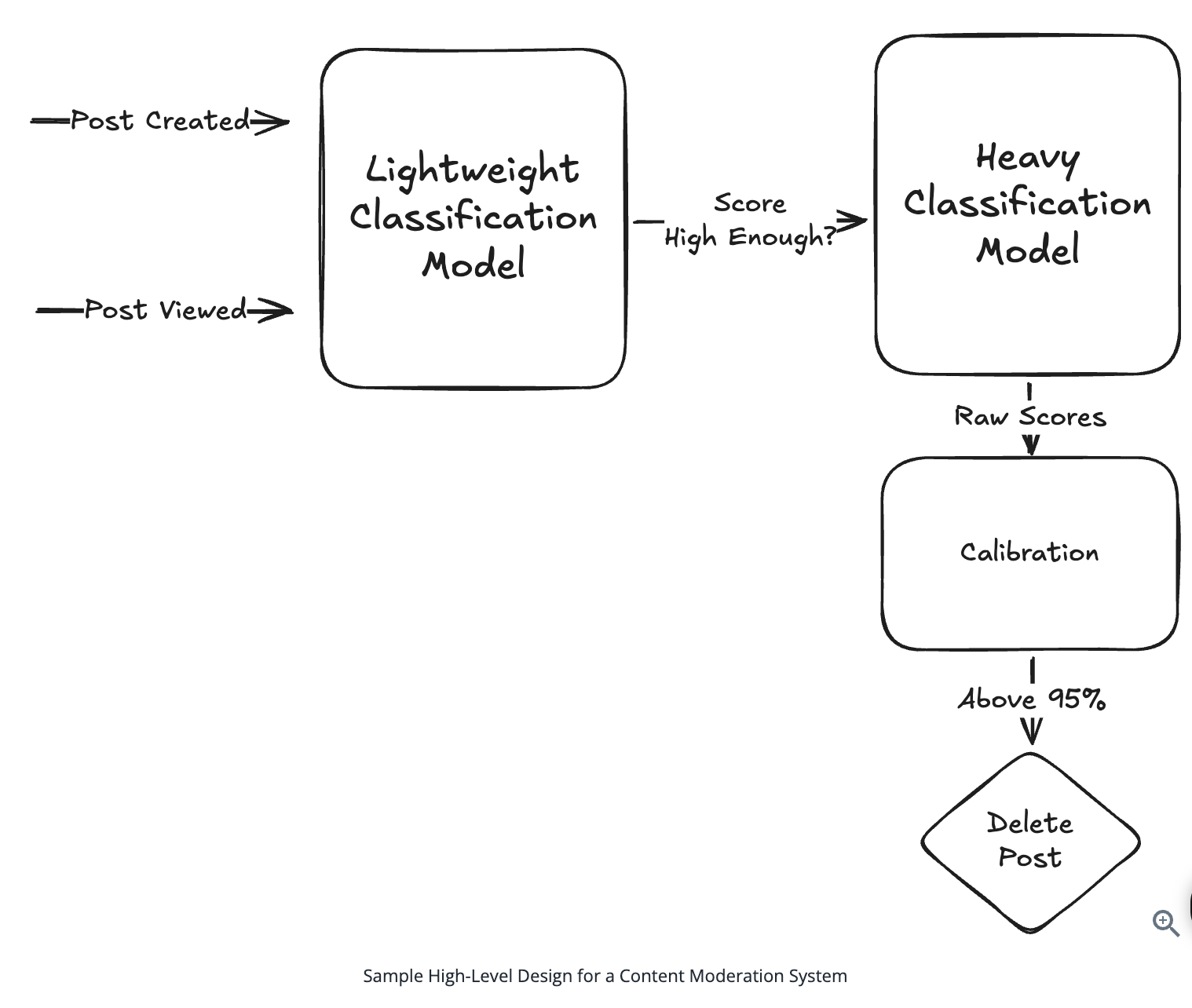
34.5. Data and Features
-
Training Data: Consider what existing data you have access to and whether you need to collect new data.
-
Features: Next, identify the features that will be most predictive for your model
Notes: Features have value, data is only raw.
- Encoding and Representations
-
For categorical features, you might use one-hot encoding or embeddings.
-
For text data, you could use bag-of-words, word embeddings, or transformer models.
34.6. Modeling
-
Benchmark Models
-
Model Selection
-
Model Architecture
34.7. Benchmark
34.7.1. Monitoring and Maintenance
34.7.2. Inference Considerations
34.8. Deep dives
34.8.1. Handling Edge Cases
34.8.2. Scaling Considerations
34.8.3. Monitoring and Maintenance
35. Benchmark ML Models
35.1. Business Objective
-
What does the business gain ?
-
How does that action impact the business?
35.2. Product Metrics
-
User retention rate
-
Time to label
-
User satisfaction scores
35.3. ML Metrics
-
Precision: When the model says something is harmful content, how often is it right?
-
Recall: What percentage of all harmful content does the model catch?
-
PR-AUC: How well does the model balance precision and recall across different thresholds?
-
F1 Score: A single number balancing how many positives we catch vs. how accurate our positive predictions are ?
-
ROC-AUC: “How well does the model distinguish between classes across different thresholds?
-
Ranking Metrics
-
NDCG (Normalized Discounted Cumulative Gain)
-
MAP (Mean Average Precision)
-
MRR (Mean Reciprocal Rank)
-
-
Image Generation Metrics
-
FID (Fréchet Inception Distance)
-
CLIP Score
-
-
Text Generation Metrics
-
Perplexity
-
BLEU/ROUGE/BERTScore
-
35.4. Evaluation Methodology
-
Offline: Build a held-out set of (query, doc, graded-relevance) triples. Compute NDCG@k, MRR, latency, and cost.
-
Online: Deploy in shadow (rank but don’t serve) to check latency & safety.
35.5. Address Challenges
35.5.1. Query Ambiguity
35.5.2. Long-Tail & Sparse Judgments
35.5.3. Freshness & Recency
35.5.4. Feedback Loops
36. Design Harmful Content
37. Design Bot Detection
38. Design Video Recommendations
39. Design Online Aunction Platform (eBay)
39.1. Functional Requirements
-
Users should be able to post an item for auction with a starting price and end date.
-
Users should be able to bid on an item, where bids are accepted if they are higher than the current highest bid.
-
Users should be able to view an auction, including the current highest bid.
39.2. Non-functional requirements

39.3. Entities

39.4. API Design

39.5. How will users be able to post an item for auction?
39.6. How will users be able to place bids on items?
39.7. How will users be able to view an auction, including the current highest bid?
- Polling the endpoint, or using Websocket, SSE.
39.8. How can we ensure strong consistency for bids?
- Using Optimistic lock.
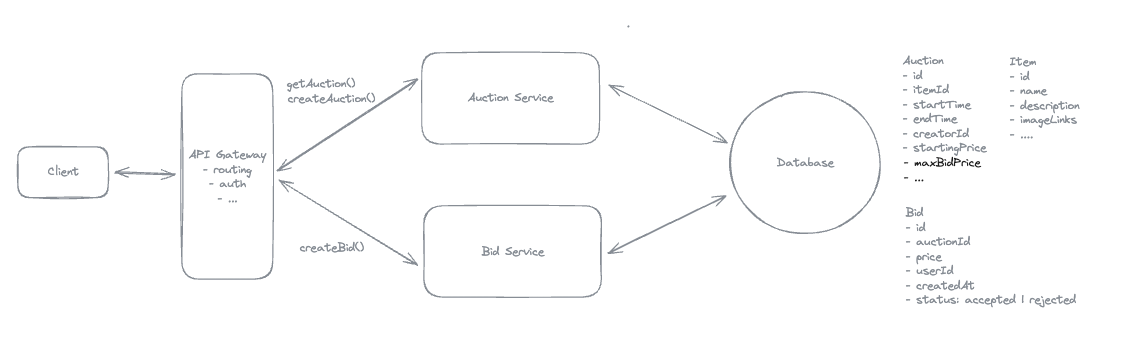
39.9. How can we ensure that the system is fault tolerant and durable, so that no bids are lost even in case of failures?
- To track the message is not lost => using message queue.
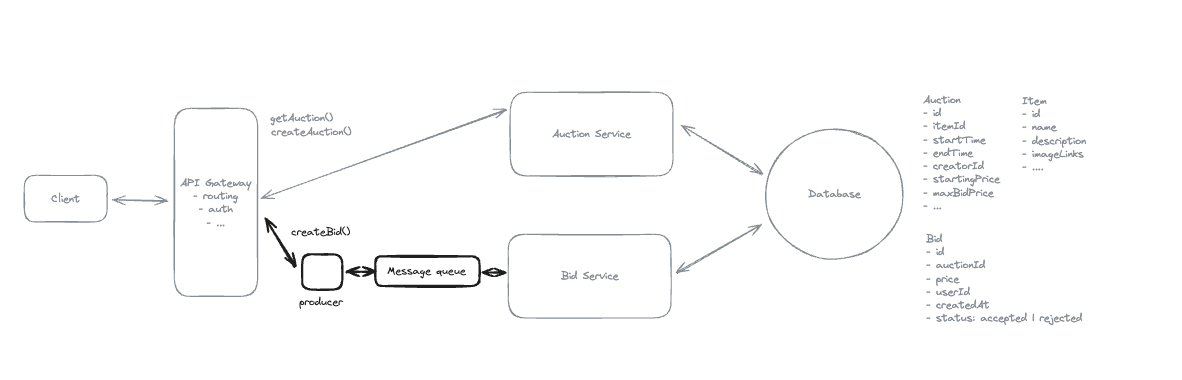
39.10. How can we ensure that the system displays the current highest bid in real-time to all 100M+ users that may be viewing auctions?
- Solution: SSE + Pub/sub.
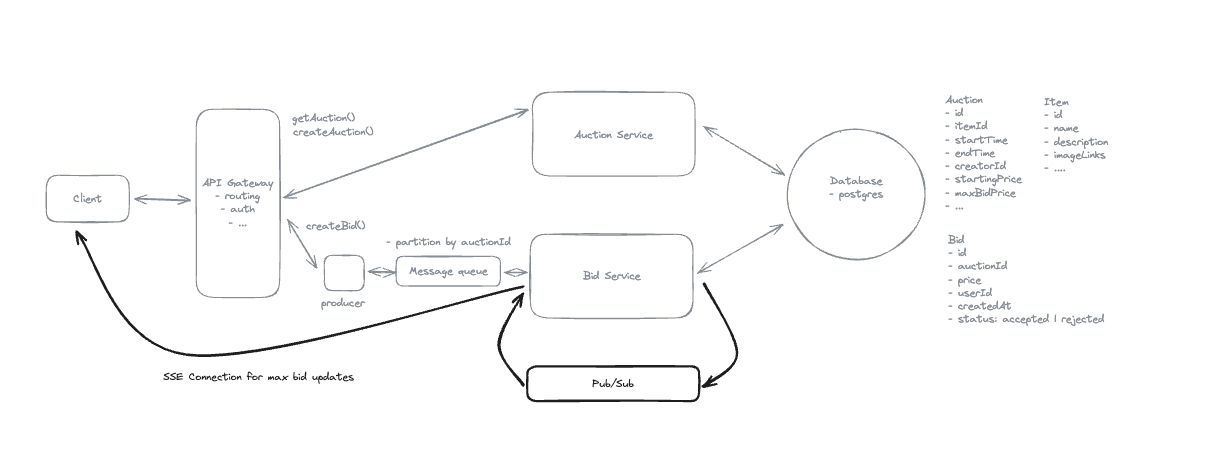
39.11. How can we scale the database to handle 50K concurrent writes and 50TB of data a year while maintaining the consistency of bids?
-
To handle 50K concurrent writes and 50TB annual data growth, we’ll shard the database across multiple instances using auction ID as the shard key.
-
We don’t need to worry about “hot auctions” because bids cost money.
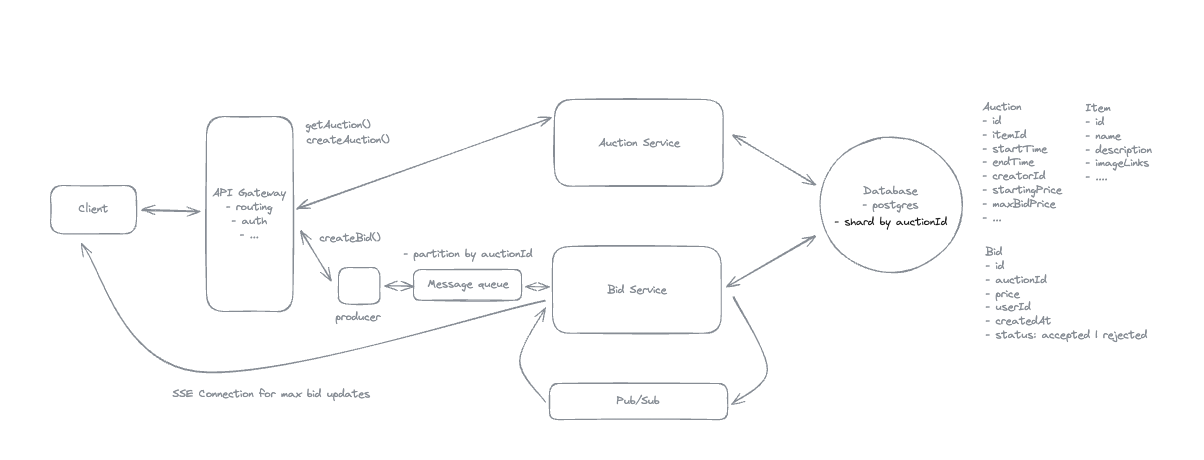
39.12. Message queues ensure durability by persisting messages to disk storage.
- Yes
39.13. Which concurrency control method avoids holding database locks?
- Optimistic concurrency control => Retry after failed with next version (application logic).
39.14. Overwriting records destroys audit trails and historical information.
-
Preserving historical data by appending rather than updating enables debugging, auditing, and dispute resolution.
-
Always consider immutable append-only designs for critical data.
39.15. Atomic compare-and-swap operations prevent lost updates in concurrent systems.
- Compare-and-swap atomically checks a value hasn’t changed before updating it.
39.16. What occurs when optimistic concurrency control detects conflicting updates?
- When conflicts are detected, requiring the application to retry with current data.
39.17. Storing the maximum bid amount directly in the auction table eliminates the need for distributed transactions when updating bid data.
- Yes
39.18 (Hay). When designing a bidding system that needs to handle concurrent bid submissions, which approach provides the BEST balance of consistency and performance?
- Store the maximum bid directly in the auction table with optimistic concurrency control
39.19. In an auction system using Server-Sent Events (SSE) to broadcast real-time bid updates, what happens when a new bid is processed by Server A but users watching the same auction are connected to Server B?
-
Subscriber receive broadcast message in only channel that they subcribed.
-
Users connected to Server B will not receive the update unless additional coordination infrastructure is implemented
39.20. Using an external cache like Redis to store maximum bid amounts requires distributed transactions to maintain consistency between the cache and database.
- Yes => Need to maintain consistency from cache and database.
40. Design Price Tracking Service (CamelCamelCamel)
40.1. Functional Requirements
-
Users should be able to view price history for Amazon products (via website or Chrome extension)
-
Users should be able to subscribe to price drop notifications with thresholds (via website or Chrome extension)
40.2. Non-functional requirements

40.3. Entities

40.4. API Design
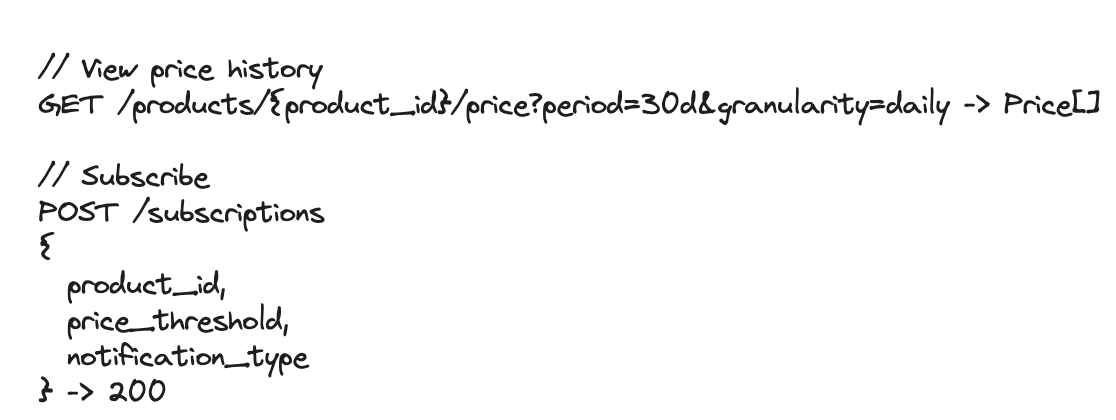
40.5. How will the system update the prices of products? Assume Amazon has no API available.
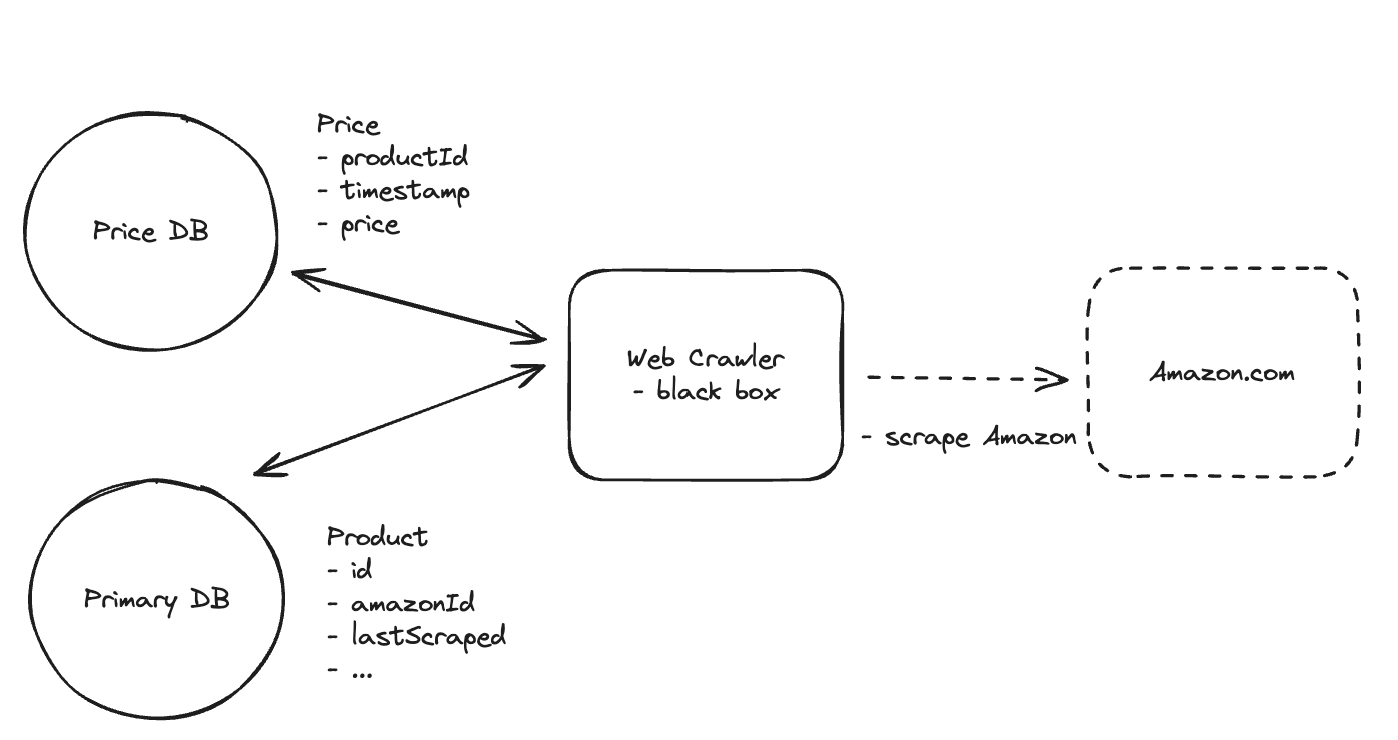
40.6. How will users be able to view the price history of a given product?
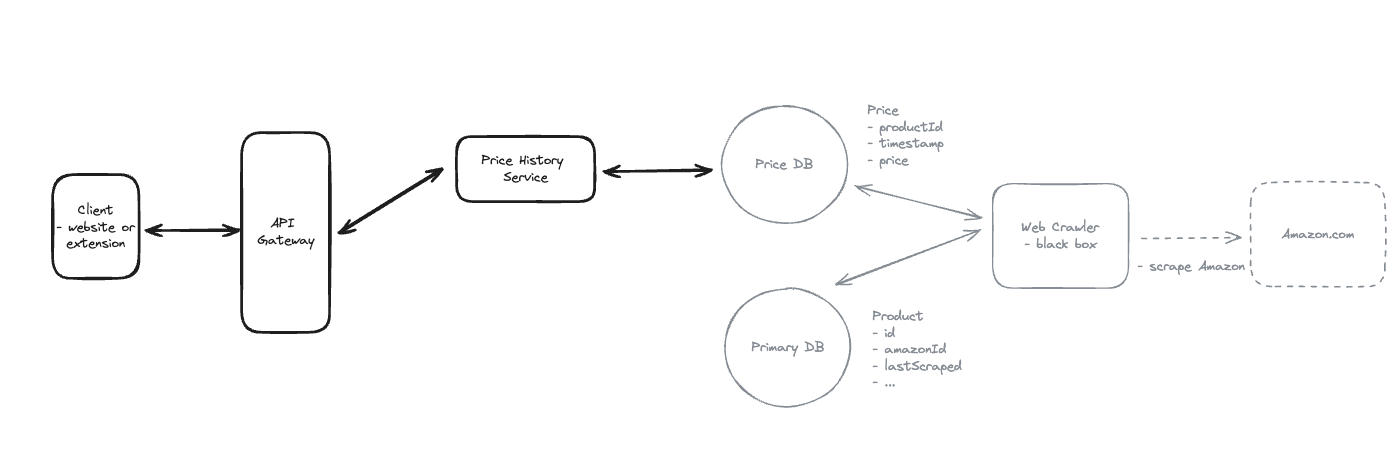
40.7 (Hay). How will users be able to subscribe to price drop notifications and get notified when a product’s price drops below a certain threshold?
- Solution: Using notification cron + SSE
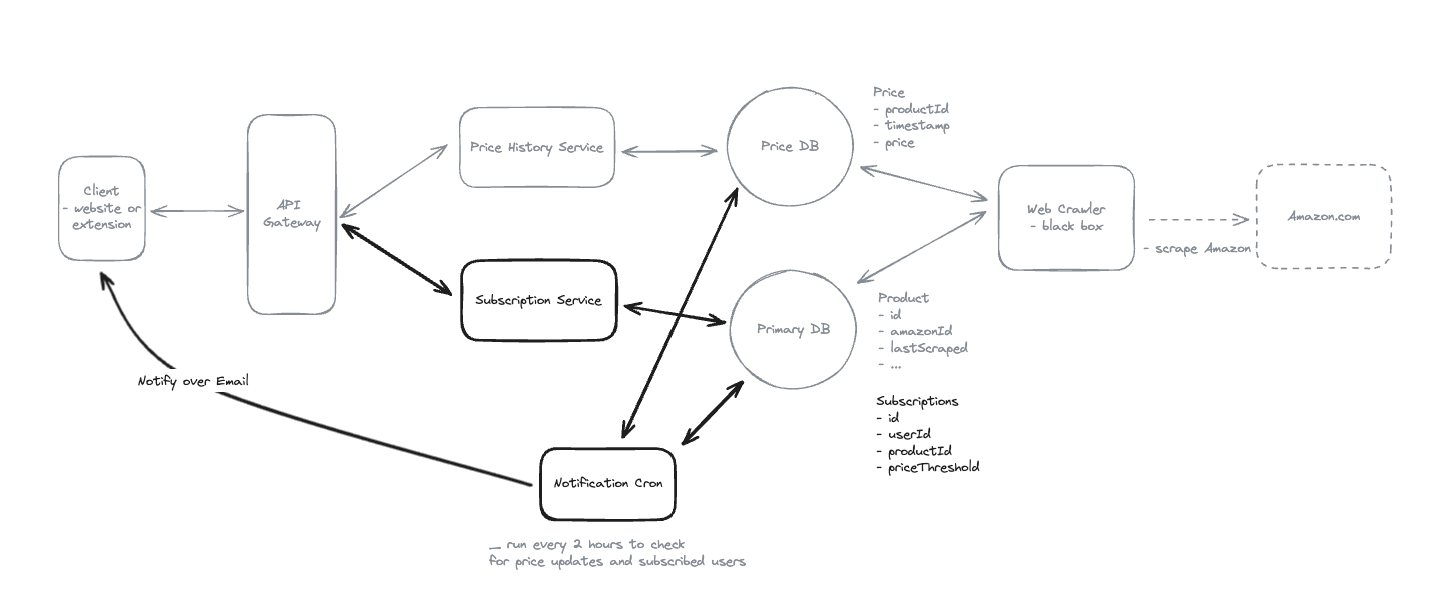
40.8 (Hay). How can we promptly know if any of the 500 million products on Amazon had a price change? Can the chrome extension help
-
The most effective approach leverages our Chrome extension for crowd-sourced price change detection
-
People/Staff use extensions and browse the website, it will send data to price updated service.
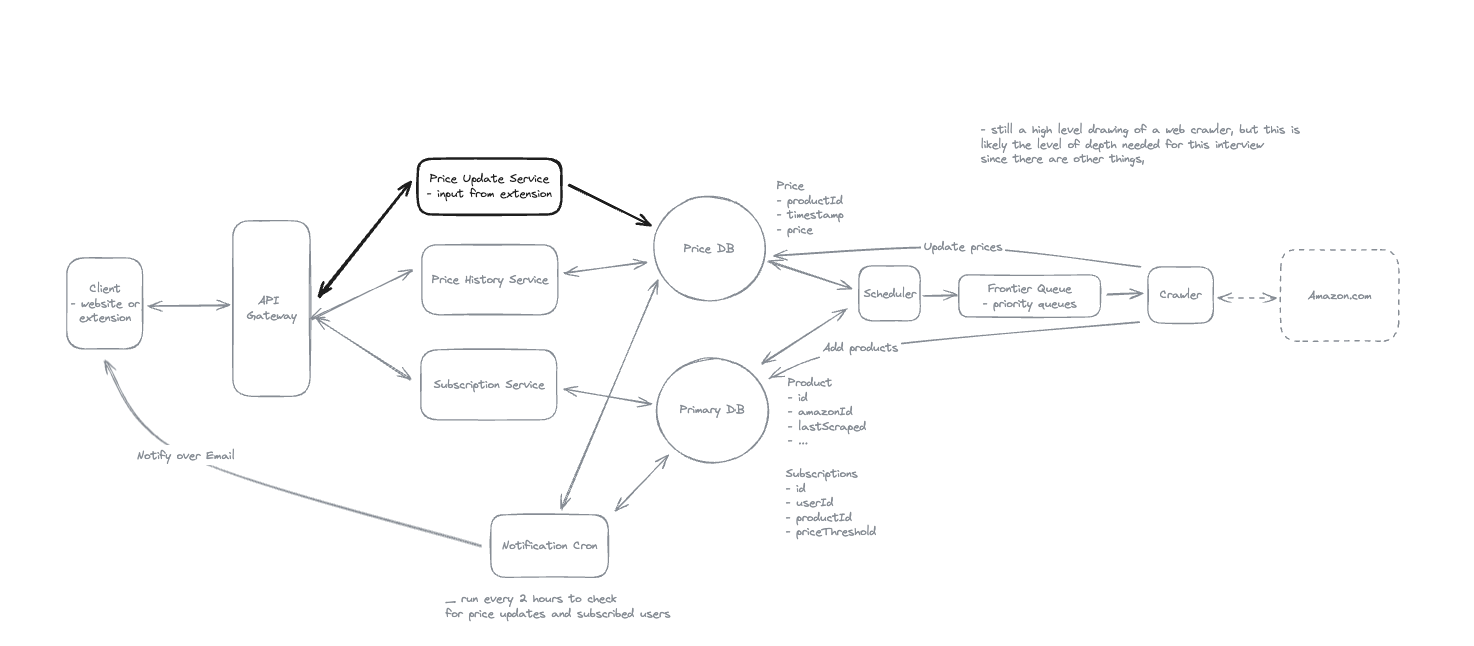
40.9 (Hay). Amazon adds thousands of new products daily. How can we ensure we’re tracking their prices?
-
Just like with price updates, we’ll use our Chrome extension for real-time product discovery.
-
When user browse the Amazon, it send data to price update service.
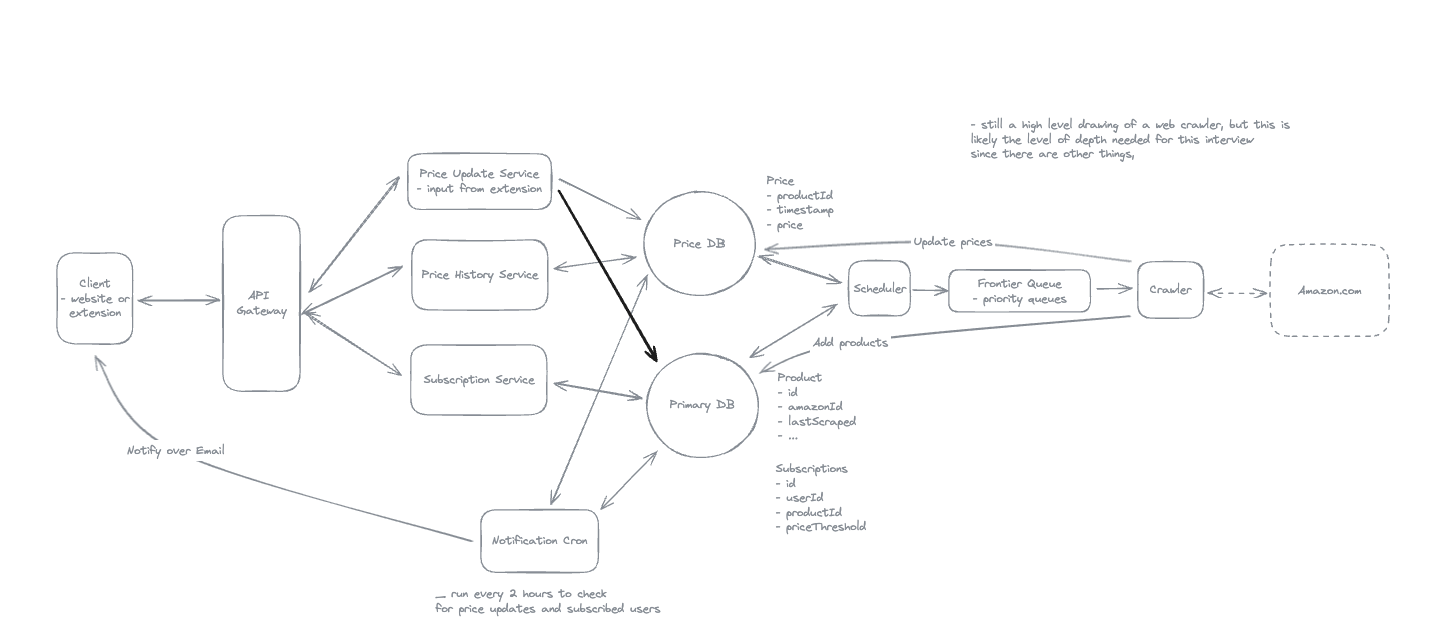
40.10 (Hay). How do we notify users as soon as we know a price has changed?
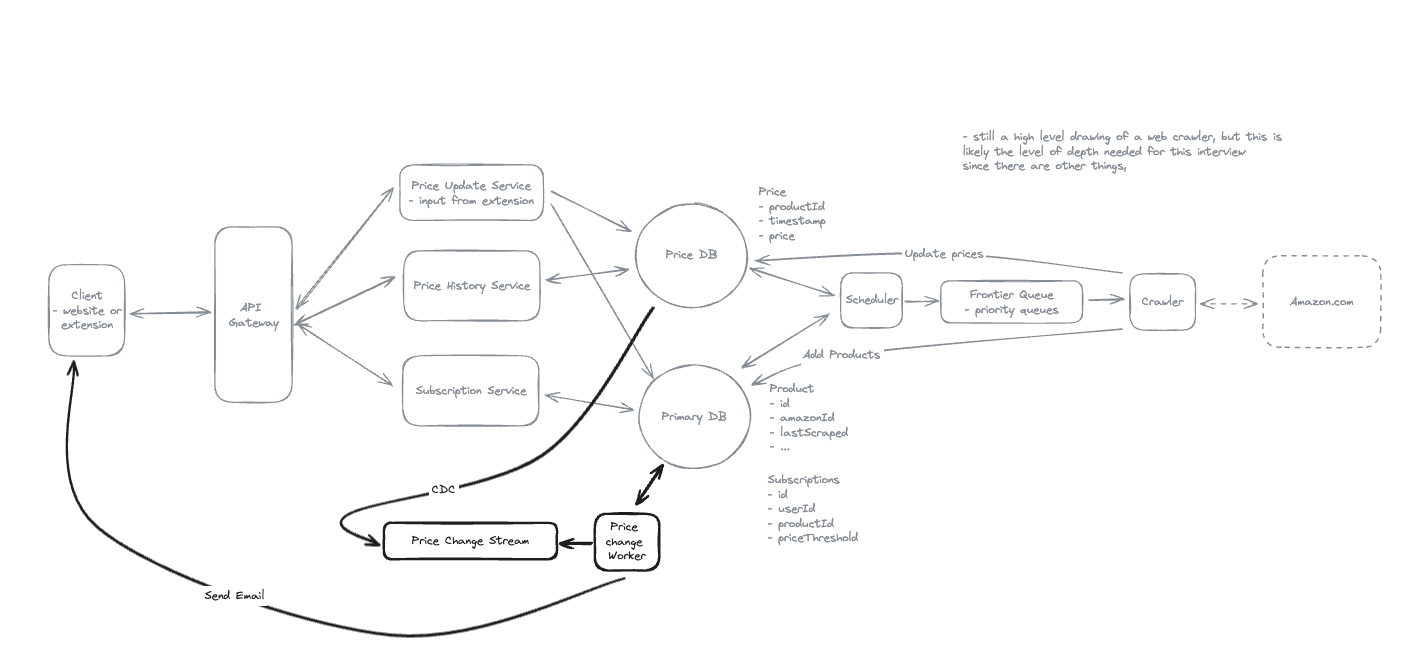
40.11. How can we ensure price history graphs load quickly, even when aggregating data over the past year?
Solution: Time-scale DB.
- We can us TimescaleDB for optimized time-series queries that can aggregate price data in real-time with sub-second performance.
=> Using time_bucket precomputed aggregations and partition by time.
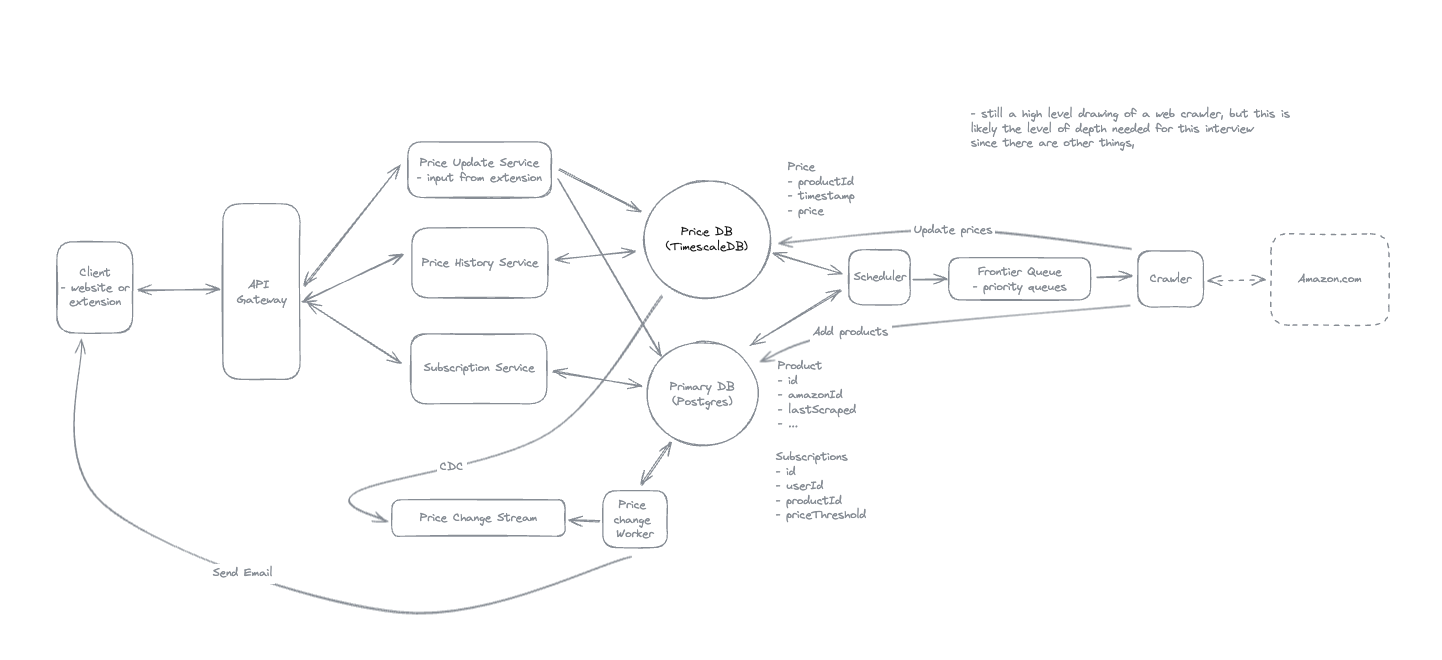
40.12. Which database type optimizes time-based data aggregations?
-
Time-series database
-
Using CDC: Binlog (MySQL), Write-Ahead Log(PostgreSQL).
40.13 (Hay). Consensus-based validation requires multiple independent sources to confirm data accuracy.
- Consensus validation works by requiring multiple independent parties to agree on data before accepting it as valid
40.14. When crawling resources are limited, which strategy maximizes user value?
- Prioritize by user interest signals
40.15 (Hay). When external APIs impose strict rate limits, which strategy helps systems scale effectively?
- When external APIs have rate limits (like 1 request per second), adding more servers doesn’t help since each server faces the same constraint.
=> Implement intelligent request prioritization.
40.16. Crowdsourced data collection scales naturally with user adoption.
- Yes
40.17. Which approach balances fast notifications with data accuracy?
- Trust-but-verify with quick validation
40.18. Which is a reason to separate time-series data from operational data?
-
Different scaling requirements
-
Distinct access patterns
-
Specialized optimization needs
40.19. Event-driven notification systems eliminate expensive database scans for change detection.
- Yes
40.20. When browser extensions report conflicting prices, which validation approach works best?
- This trust-but-verify approach handles conflicting user data by quickly checking another authoritative source
40.21 (Hay). TimescaleDB is a time-series extension for PostgreSQL
-
TimescaleDB can provide specialized time-series performance while maintaining PostgreSQL compatibility.
-
PostgreSQL » MySQL: If your application is complex, use PostgreSQL (geography index, timescale db, vector db)
-
Use MySQL for simple application: CMS, blogs.
40.22 (Hay). For serving historical price charts with sub-500ms latency, which approach performs best?
- Real-time aggregation queries
41. Design FB Live Comments
41.1. Functional Requirements
-
Viewers can post comments on a Live video feed
-
Viewers can see comments made before they joined the live feed
-
Viewers can see new comments being posted while they are watching the live video
41.2. Non-functional requirements

41.3. Entities

41.4. API Design

- SSE Endpoint: sse://receiveComment(message, user)
41.5. How will viewers be able to post comments on a Live video feed?
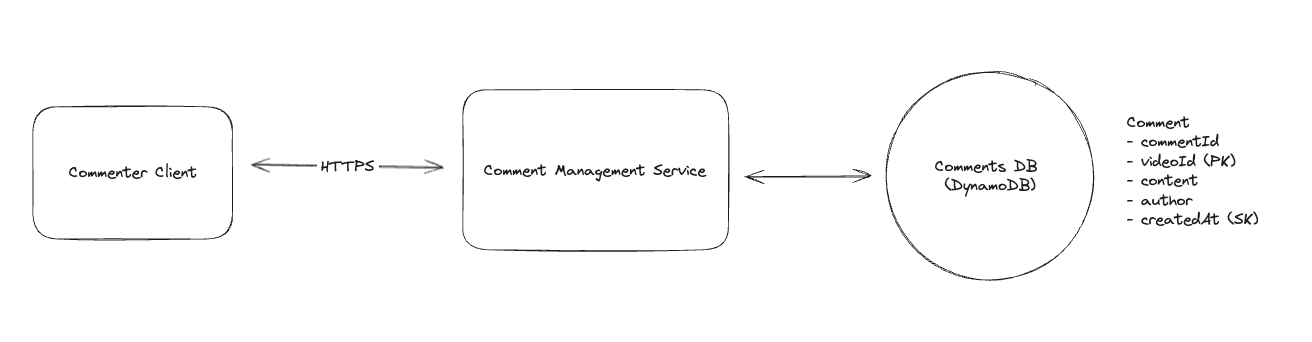
41.6. How will viewers see comments made before they joined the live feed, even if there were tens of thousands of them?
- Fetch last comment by cursor-based pagination.
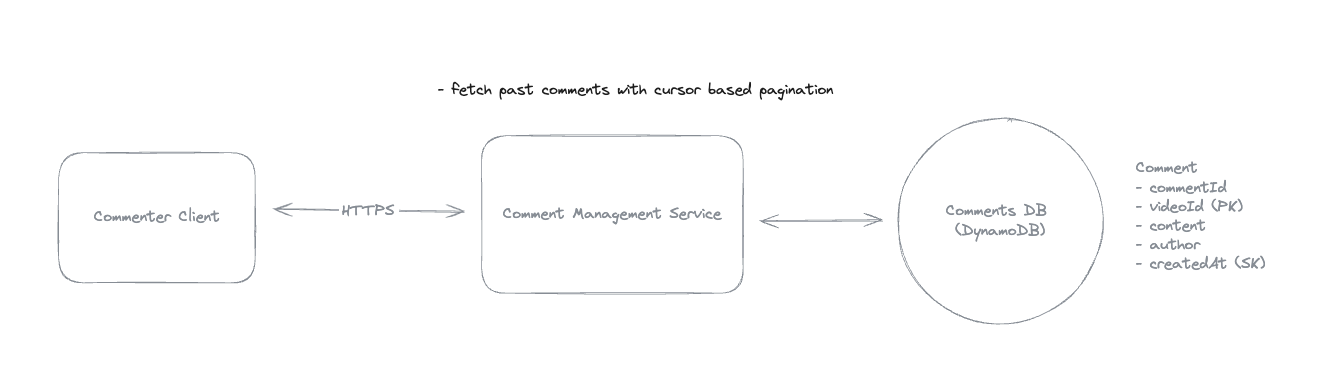
41.7. How will viewers see new comments being posted while they are watching the live video?
-
Every 3 seconds, the client checks for new comments that arrived after their last seen timestamp.
-
We can improve this later with WebSockets or Server-Sent Events for better real-time performance and scalability.
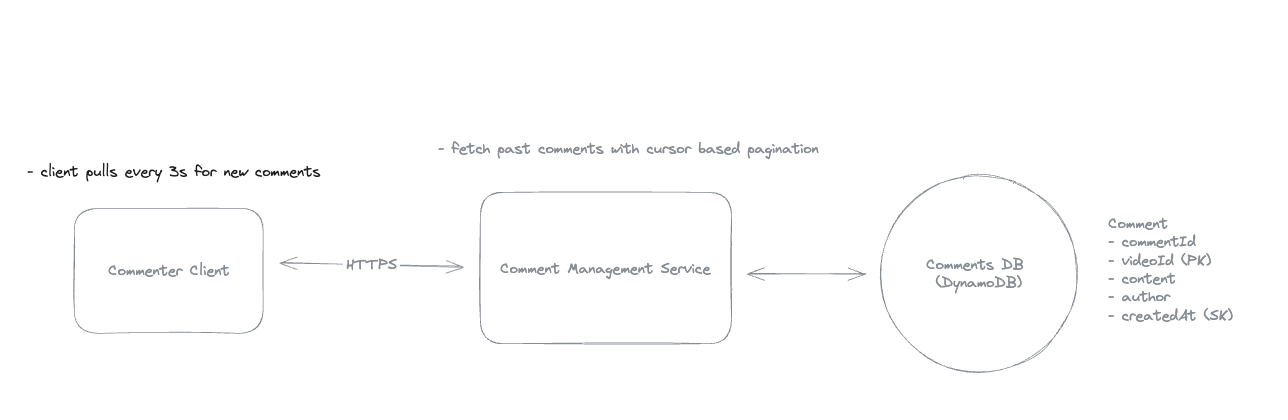
41.8. How can we ensure comments are broadcasted to viewers in real-time? Don’t worry about scale yet. Consider just one live video.
To achieve true real-time comment delivery, we should replace our polling mechanism with Server-Sent Events (SSE).
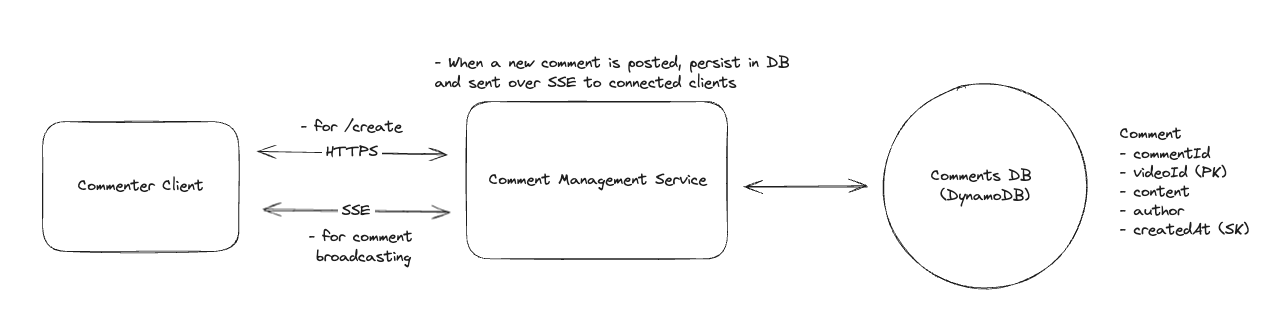
41.9. How will the system scale to support millions of concurrent viewers per live video?
-
To handle real-time comment distribution at scale, we’ve introduced a Realtime Messaging Service that works alongside Redis pub/sub.
-
Applying broadcast pattern: Redis Pub/Sub + SSE.
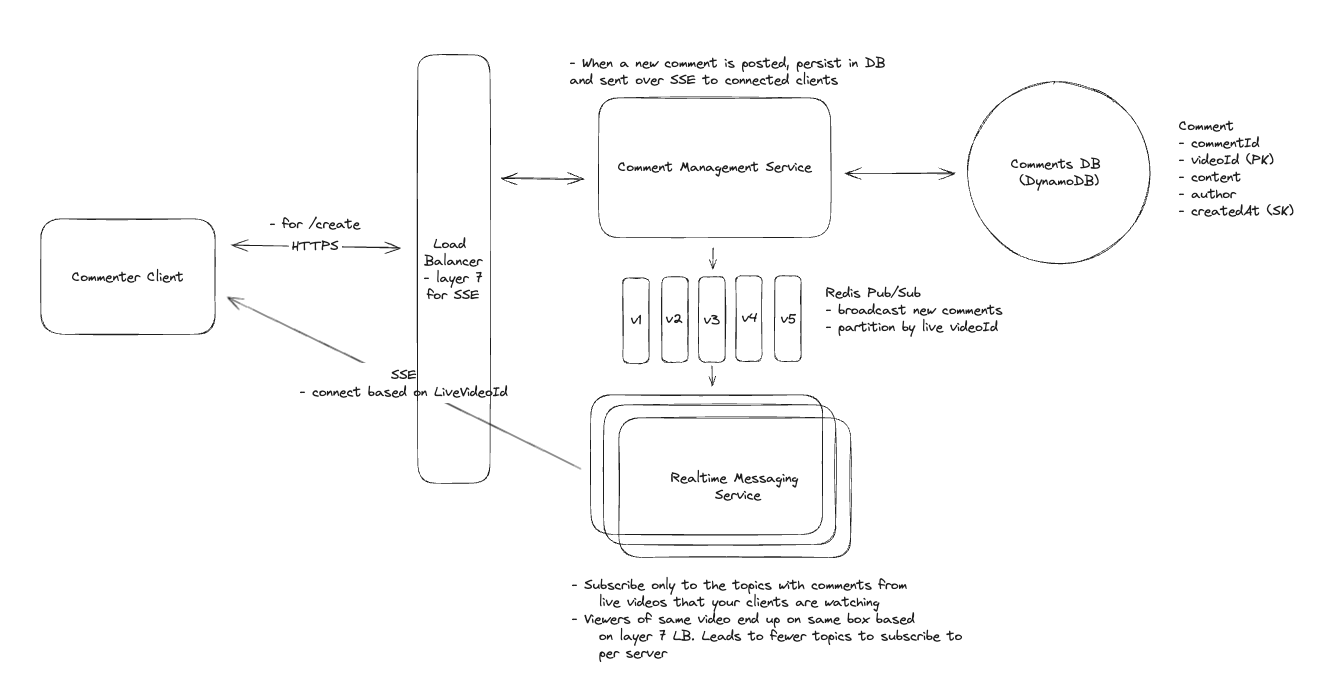
42. Design FP Post Search
42.1. Functional Requirements
-
Users should be able to create and like posts
-
Users should be able to search posts by keyword
-
Users should be able to get search results sorted by recency or like count
42.2. Non-functional requirements

42.3. Entities

42.4. API Design

42.5. How will users create posts and like them?
42.6. How to search posts by keywords ?
42.7. How to sort posts by recently and like count ?
42.8. How can we scale the keyword search to support trillions of posts?
-
We’ll create a separate “Ingestion” service which will be triggered when a post is created or a like happens
-
Split to keywords and add to ElasticSearch.
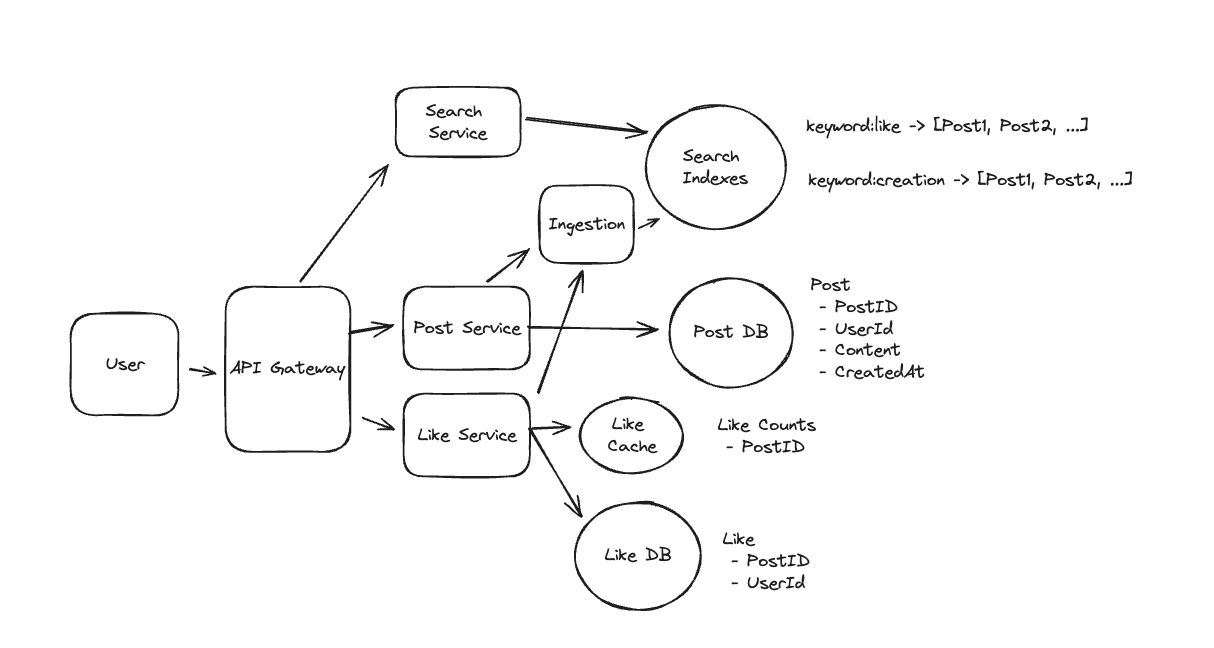
42.9 (Hay). How will the system handle queries with multiple keywords (e.g. “taylor AND swift”)?
-
Instead of indexing only singular words, we’ll also index the bigrams.
-
Search by bigrams first, each word later.
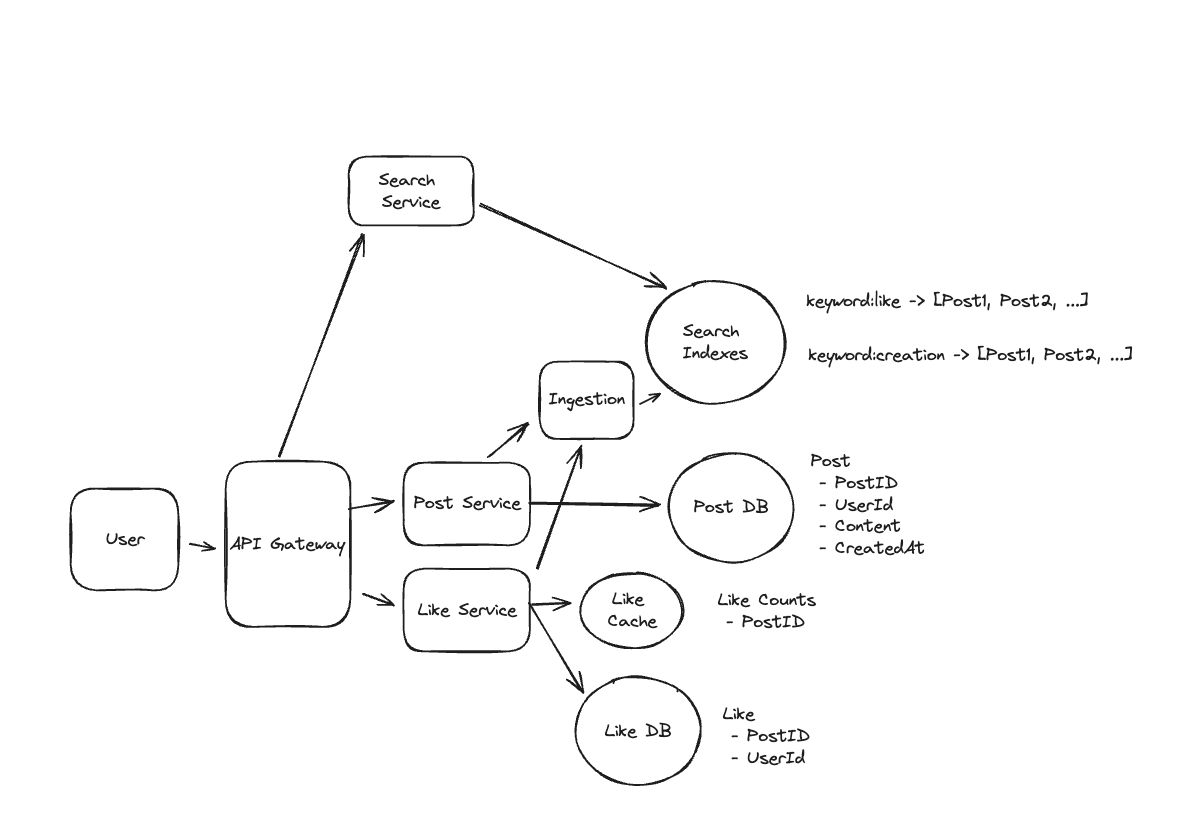
42.10 (Hay, Cache common search in CDN). How can we ensure searches queries are still fast in the case of many results (like “taylor swift”)?
-
Solution: Cache some common search query in CDN by region.
-
We can use an LRU eviction strategy to ensure our CDN contains only the most popular search queries.
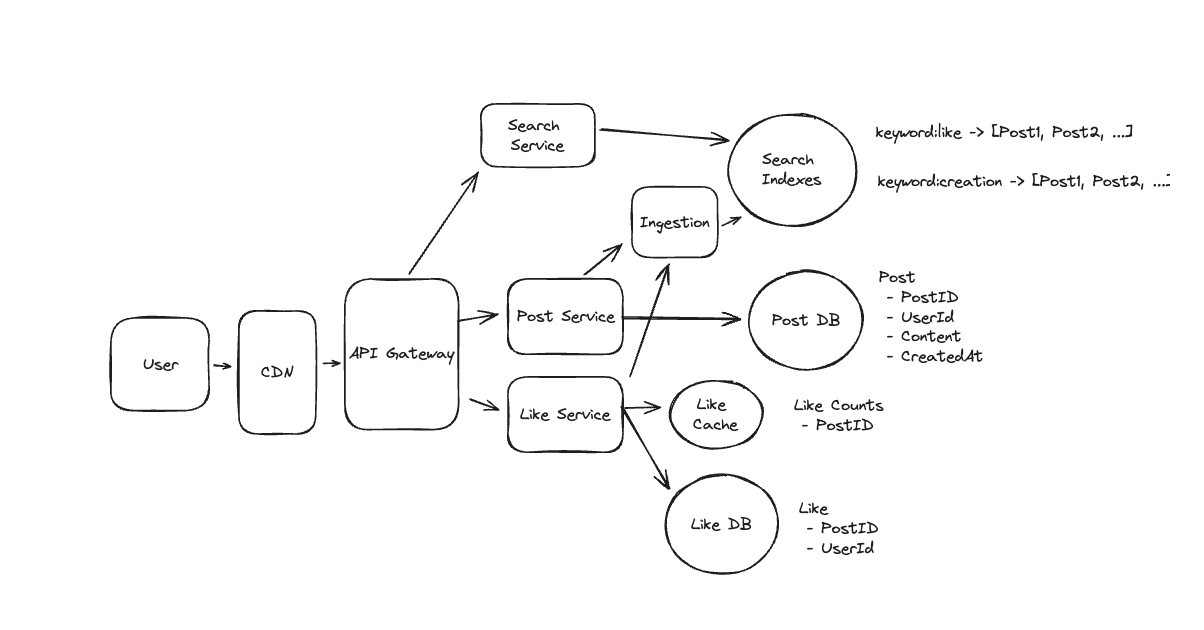
42.11 (Hay). How can we make ingestion scalable and fast with millions of posts and billions of likes?
- Search first => Query like in list return, allow approximately correct.
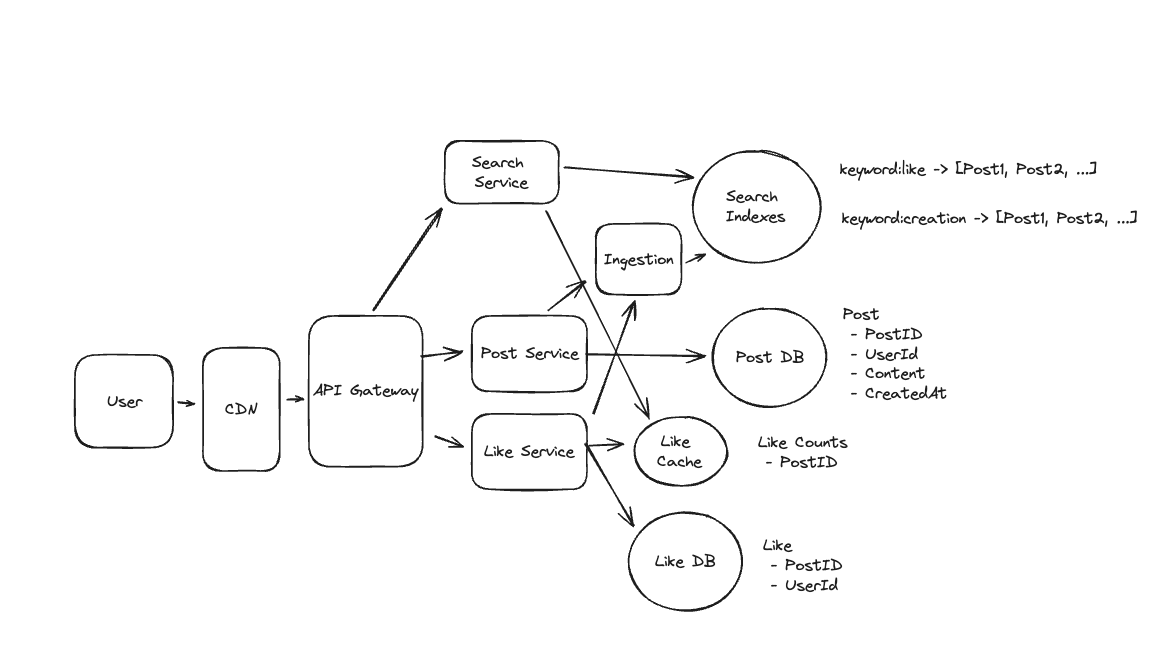
42.12 (Hay). How can we optimize the storage requirements of the system?
- Apply cold/warm/hot search index in S3 for storage.
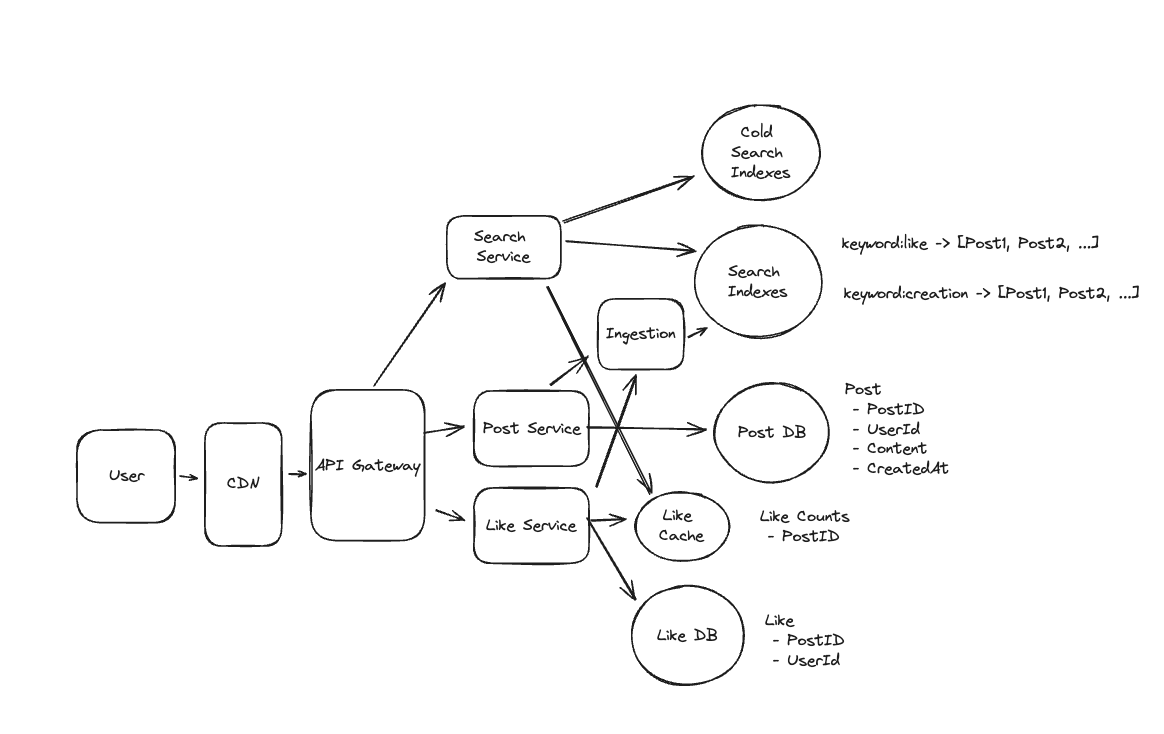
42.13. Inverted indexes enable efficient keyword searches by mapping terms to document lists.
- Yes
42.14. When processing millions of like updates per second, which approach reduces write load?
- Batching updates over time windows
42.15. Caching identical search queries reduces load on the primary search system.
- Yes
42.16. Which approach works BEST for systems with frequent read operations?
- Read-through caching
42.17. Set intersection helps find documents matching multiple search criteria.
- True
42.18. A system processes one million updates per second. Which storage approach handles this load most efficiently?
- In-memory with periodic snapshots
42.19. Redis sorted sets maintain elements in order while allowing efficient score updates.
- Yes
42.20. What happens when a cache’s TTL expires during high traffic?
- Backend experiences request spike
42.21. N-gram indexing increases storage requirements but improves phrase search performance.
- Yes
42.22. Two-stage architectures trade initial accuracy for improved overall system performance.
- Query data by search in the first-step, allow query approximately in client-side in the second step.
42.23. When an inverted search index grows beyond the memory capacity of a node, which approach maintains query performance?
- Hot-cold data separation
42.24 (Hay). What causes write amplification when indexing text documents?
- Each word creates separate index entries
=> A 100-word post might trigger 100+ separate index writes.
43. Design Youtube Top K
43.1. Functional requirements
-
Clients should be able to query the top K videos (max 1000) for a given time period.
-
Time periods should be limited to 1 {hour, day, month} and all-time.
43.2. Non-functional requirements

43.3. Entities
-
Video
-
View
-
Time Window
43.4. API Design
GET /views/top?window={WINDOW}&k={K}
Response:
{
"videos": [
{
"videoId": // ...
"views": // ...
}
]
}
43.5. How to get top K video
- Solution: Using Heap and Counter
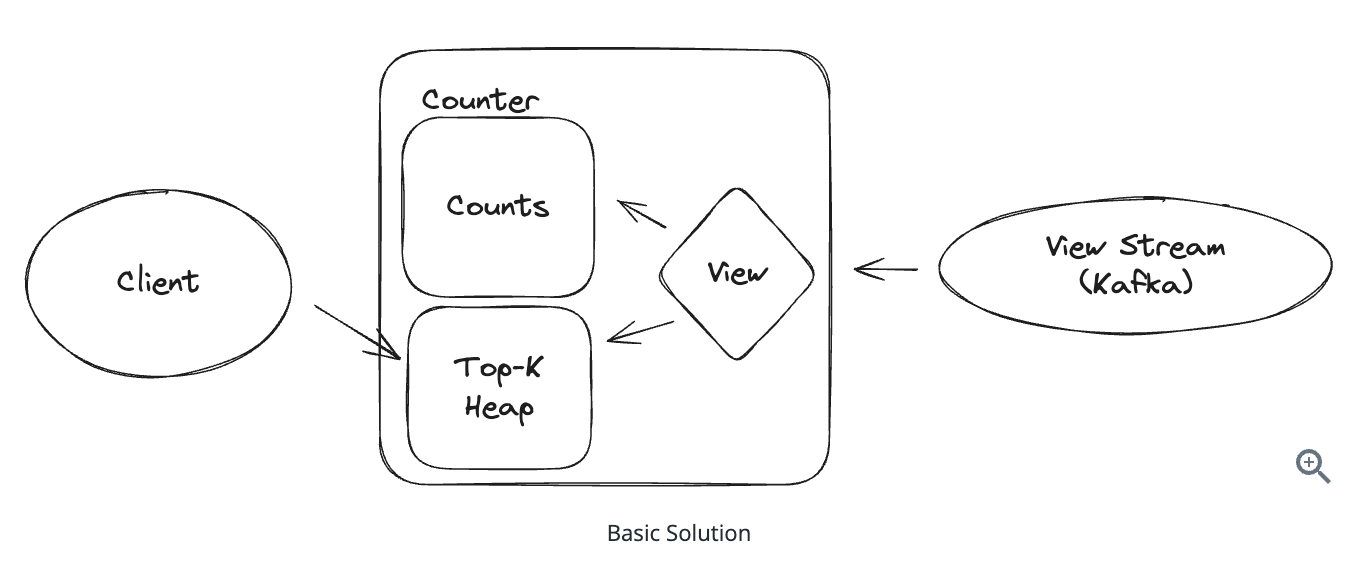
43.6. Enhance Reliability Lists
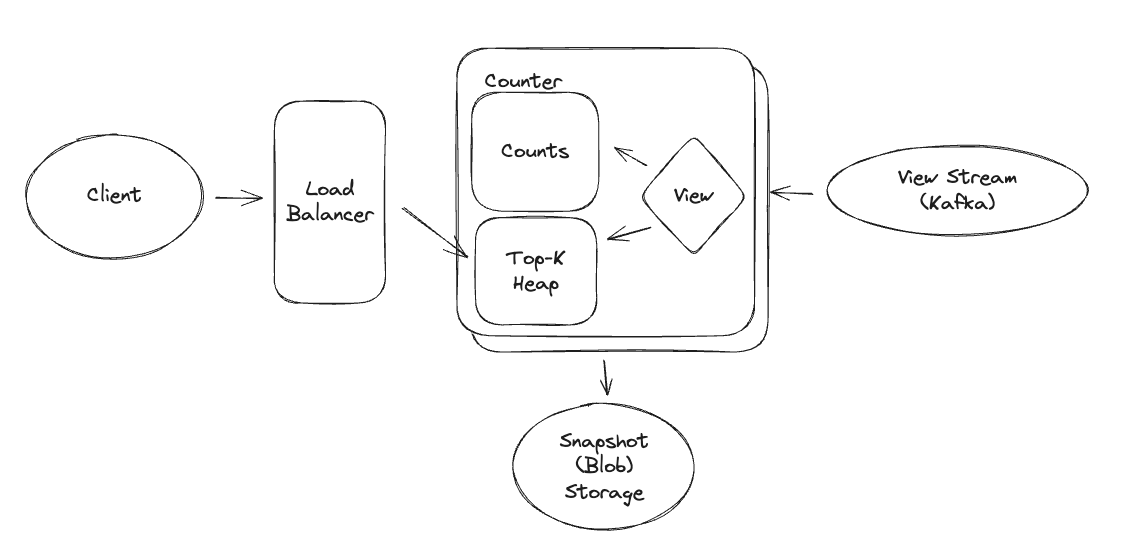
43.7. Scaling writes
- Idea: Each traffic go to 1 node, applying ring architecture because if a node failed, the requests go to the nearest replacement node.
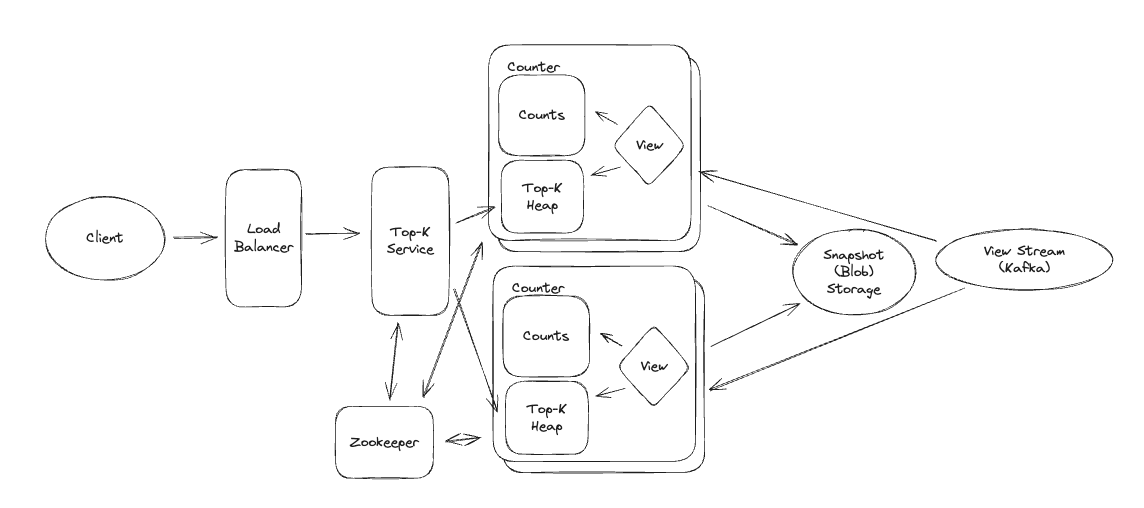
43.8. Handling Time Windows
Solution: Applying sliding window for timeframe in counting
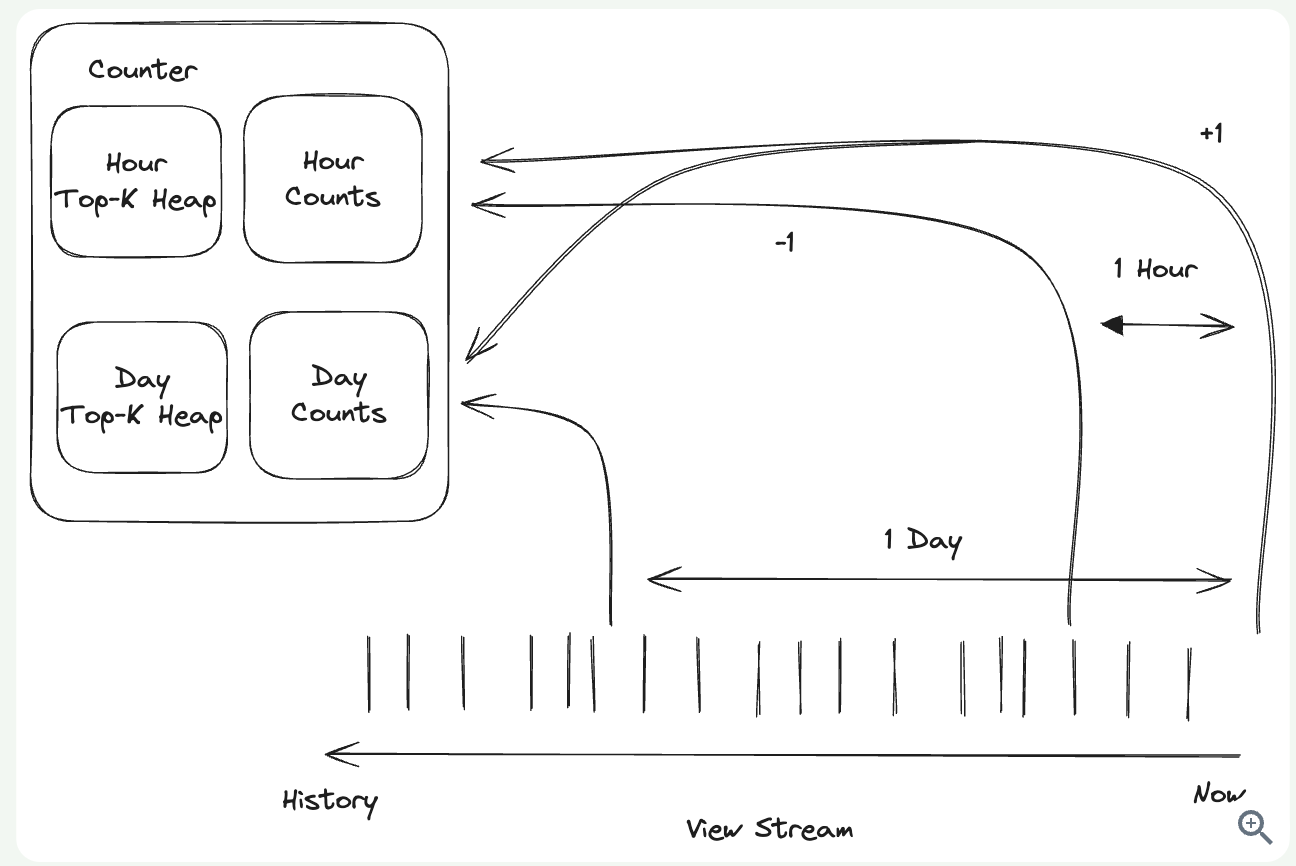
43.9. Large number of incoming requests
- Solution: Divide to count in multiple instances + Merge the result => Divide and Conquer technique.
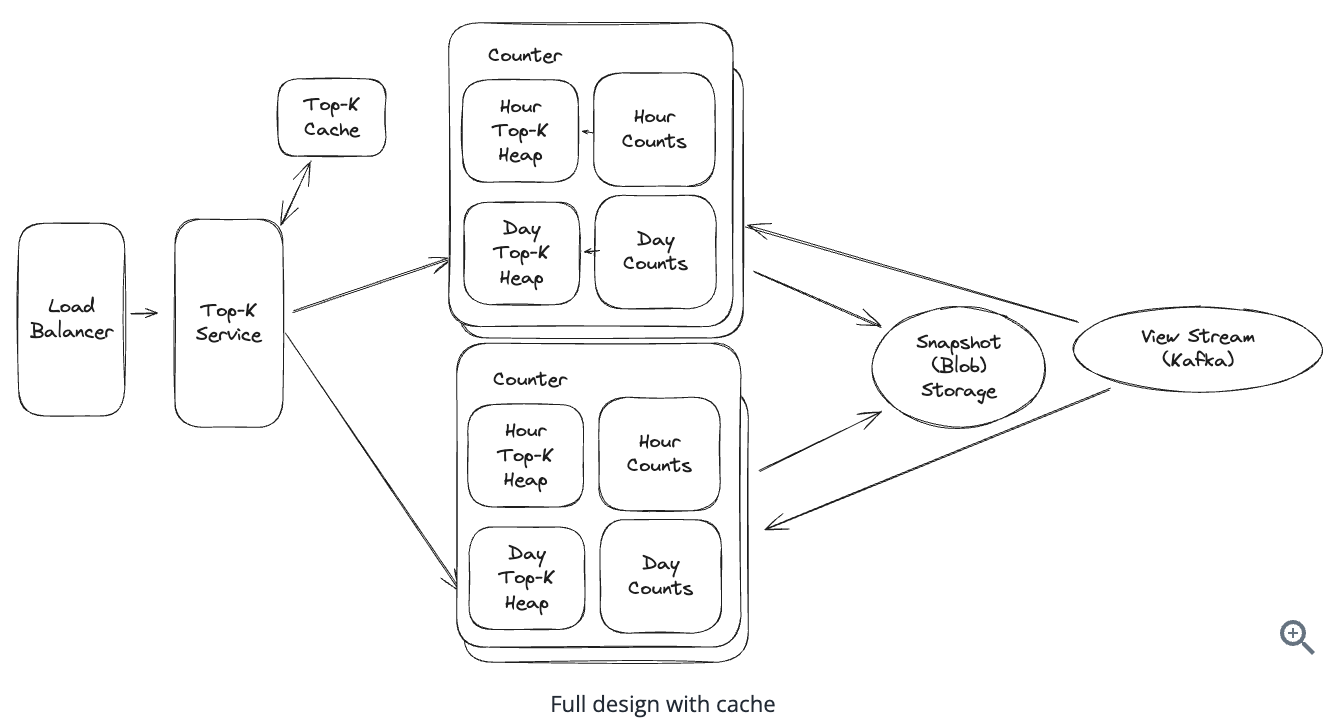
43.10. Skip List
Level 2: 2 ───────────────→ 10
Level 1: 2 ─────→ 6 ─────→ 10
Level 0: 2 → 4 → 6 → 8 → 10
Example: Search for 8
-
At Level 2: 2 → 10 → STOP (10 > 8), go down one level
-
At Level 1: 2 → 6 → 10 → STOP (6 < 8 < 10), go down one level
-
At Level 0: 6 → 8 → FOUND
43.11. Heap data structures maintain elements in sorted order efficiently.
- Yes
43.12. Streaming algorithms can maintain exact top-K results using only O(K) memory regardless of total stream size.
- Yes. Redis sorted set pre-computed value to O(K) queue.
43.13. Which technique distributes load across multiple servers?
- Sharding.
43.14. Database connection pooling reduces latency by maintaining persistent connections to the database.
- Yes
43.15. What is the most memory-efficient approach for maintaining top-K elements in a streaming data system?
-
Use a min-heap of size K and replace the minimum when a larger element arrives.
-
When a new element arrives that’s larger than the heap’s minimum, we replace the minimum with the new element.
43.16. What is the primary trade-off of data replication?
-
Network overhead
-
Consistency complexity
-
Increased storage cost
43.17. Sharding eliminates single points of failure in distributed systems.
- Load balancing, coordinators are still single point of failure.
43.18. When a node fails, which approach enables fastest recovery?
- Snapshot restoration
43.19. Limit of vertical scaling
-
CPU Bottleneck: The process can’t fully use all 16 cores (e.g., due to lock contention, or language limitations like Node.js’s single-threaded nature) => Scale max but the CPU only have 16 threads and single-threaded processing.
-
Network bandwith
-
Amdahl’s Law: Upgrading from 16 to 32 cores gives only 10–20% improvement => Scale too much and it peak to the limit of hardware => declare max speed-up, because the heat of the CPU, trade-off the engineering and physical hardware.
43.20. When implementing a two-pointer technique for sliding time windows, what is the optimal data structure for maintaining window boundaries?
- Deque (double-ended queue) for O(1) front/back operations
43.21. When designing a real-time analytics system that processes streaming data with strict latency requirements, which approach provides the BEST balance between consistency and availability?
- Asynchronous replication with eventual consistency and local reads.
43.22. Precomputation always reduces query latency at the cost of storage.
- Precomputed results may become stale, require complex invalidation.
43.23 (Hay). What is the primary challenge when horizontally scaling stateful stream processors that maintain running aggregations?
- When scaling stateful stream processors horizontally, the main challenge is redistributing accumulated state (like counters, heaps, or time windows) across new nodes.
=> Have counter, heap, time windows, it is stateful.
44. Design Google Docs
44.1. Functional Requirements
-
Users should be able to create new documents.
-
Multiple users (limit 100) should be able to edit the same document concurrently.
-
Users should be able to view each other’s changes in real-time.
-
Users should be able to see the cursor position and presence of other users.
44.2. Non-functional Requirements

44.3. Entities

44.4. API Design

- Use Web Socket: ws/docs/{docID}
44.5. How will users be able to create new documents?
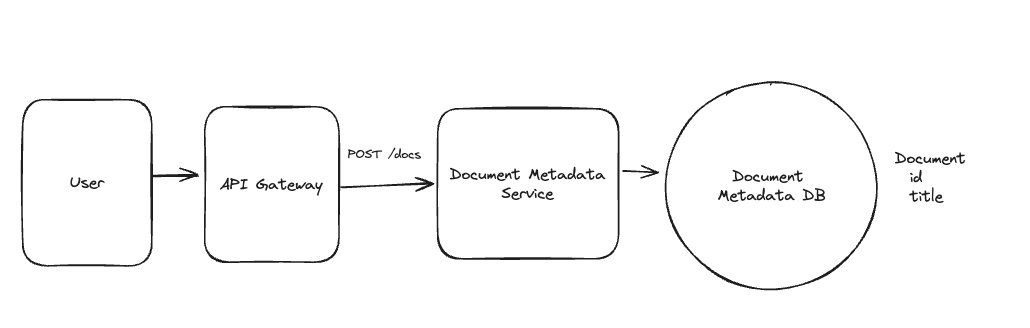
44.6. How can we extend the design so that multiple users can edit the same document concurrently (especially when they are making changes simultaneously)?
- Using websocket and versioning.
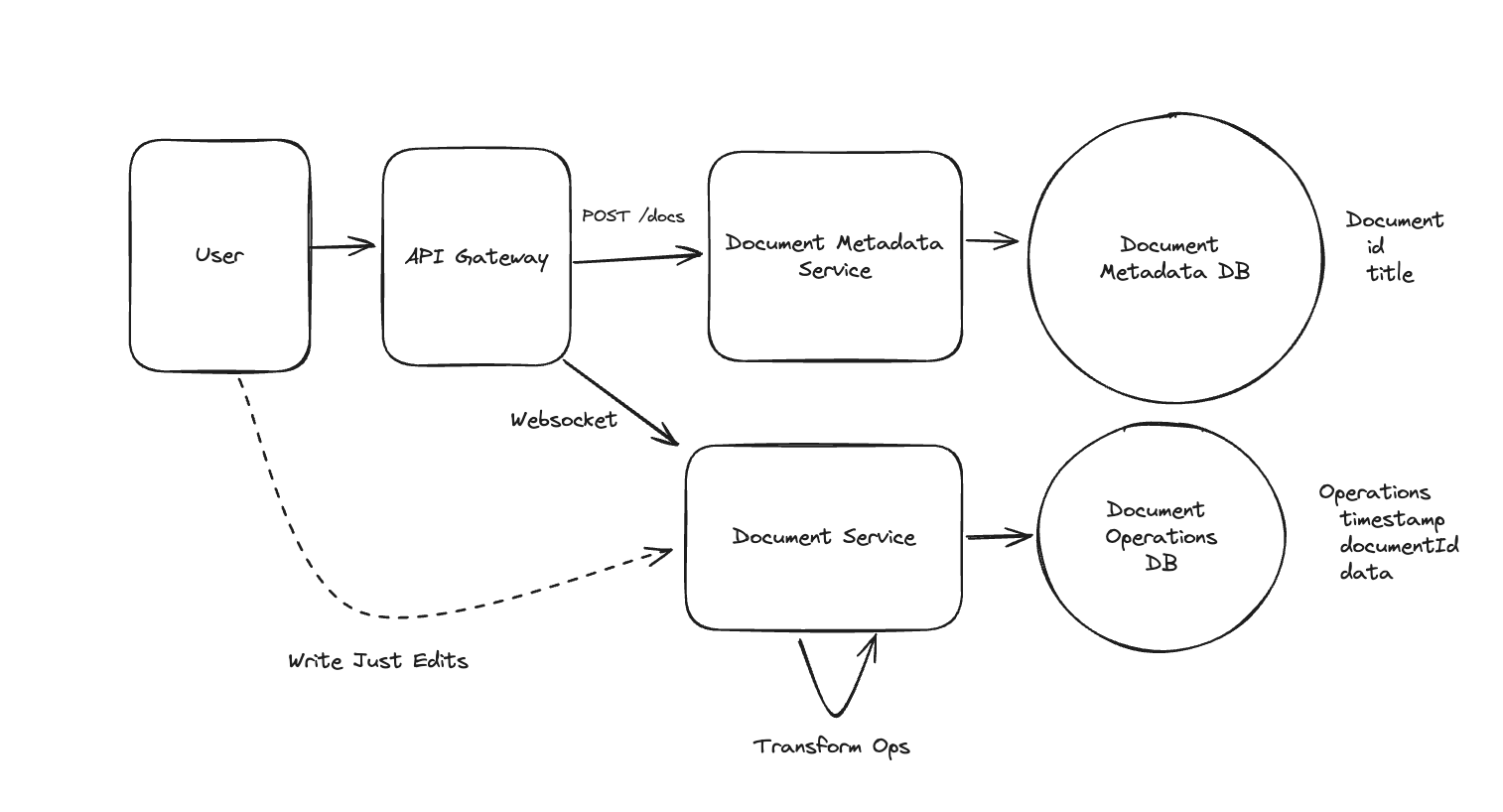
44.7. How will users be able to view each other’s changes in real-time?
- For users to view each others’ changes, we’ll need to have a way to broadcast each (transformed) edit to all connected users.
=> Apply broadcasting patterns.
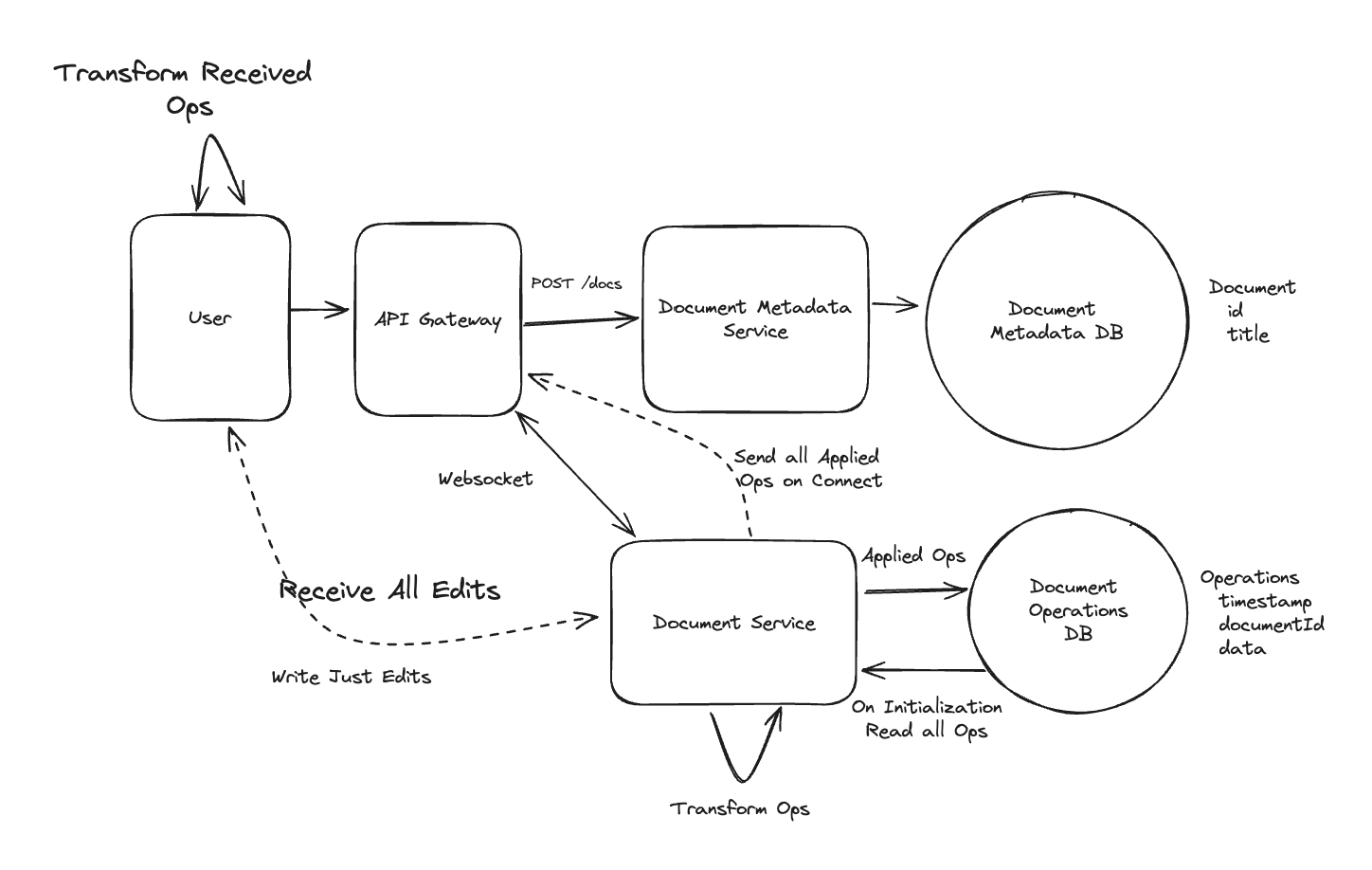
44.8. How can we enable users to see the cursor position and presence (whether they’re connected or not) of other users?
- Users will frequently send updates to their cursor position (no need to send if it doesn’t change!) to the Document Service which will update the struct for that user and broadcast to all connected users => Else offline.
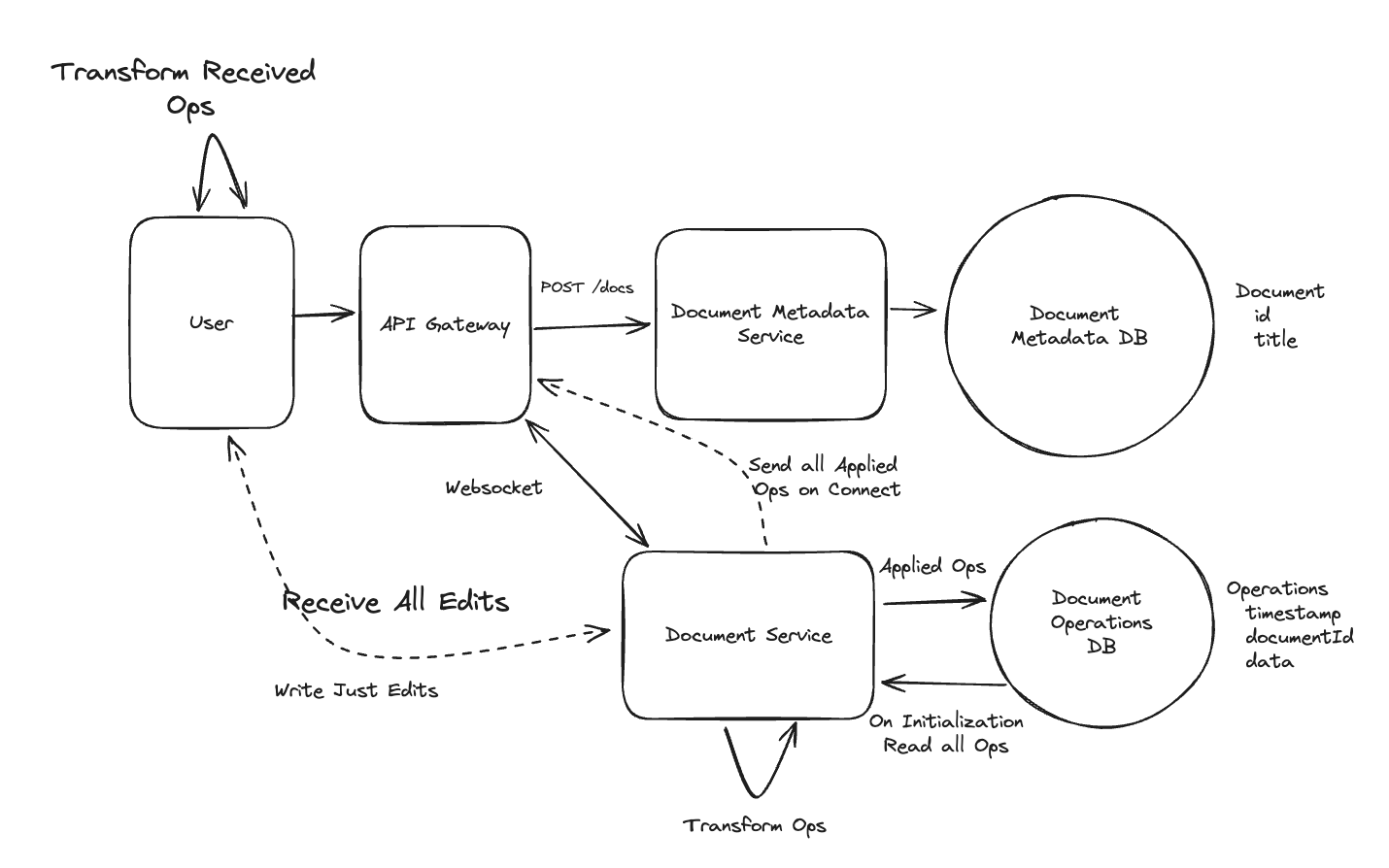
44.9. How do we scale to millions of connections from our users?
- Using Zookeeper to manage all the connections.
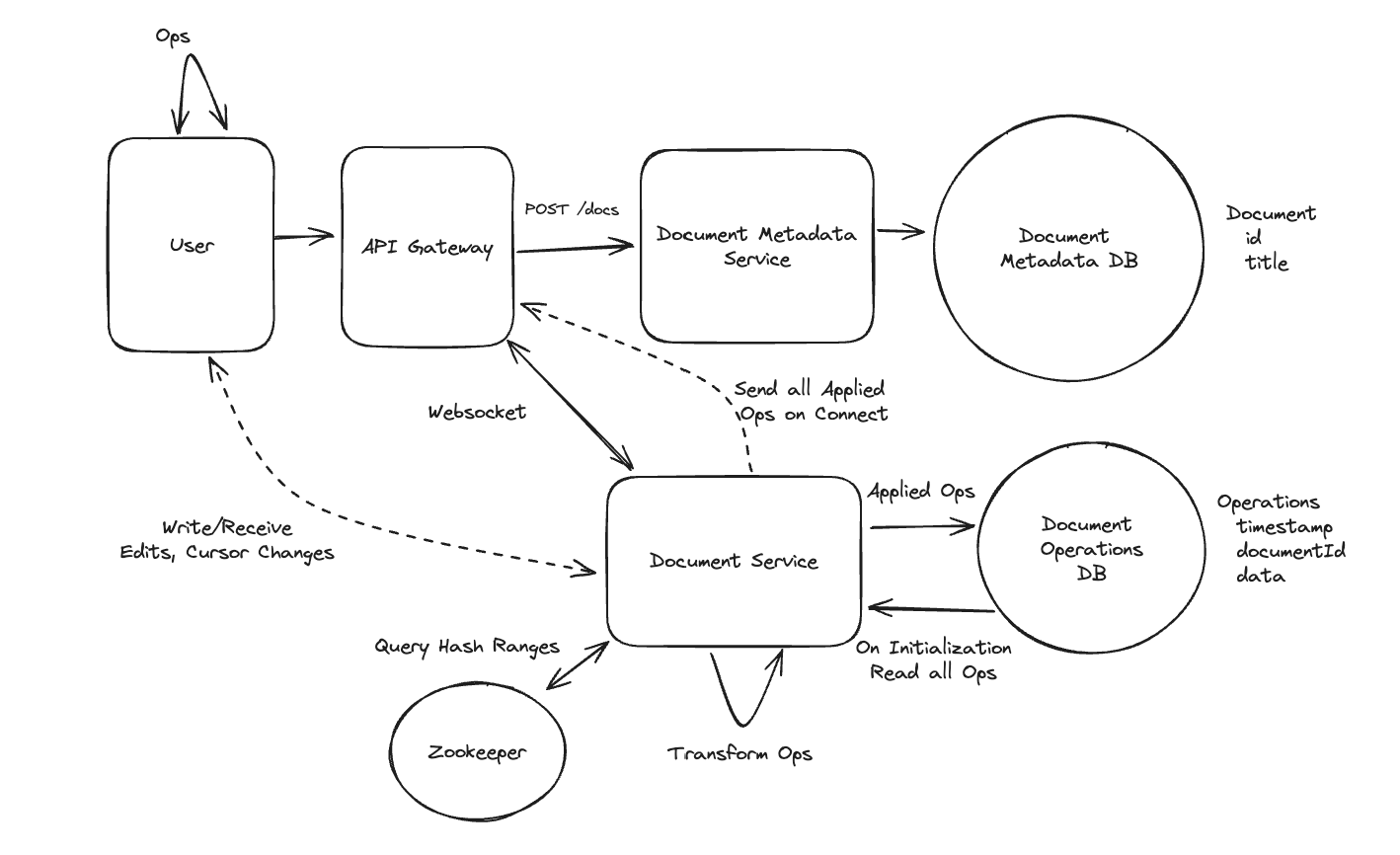
44.10. How can we optimize document storage?
-
Apply cold-hot patterns.
-
Cold documents come to S3, hot documents load versioning to database.
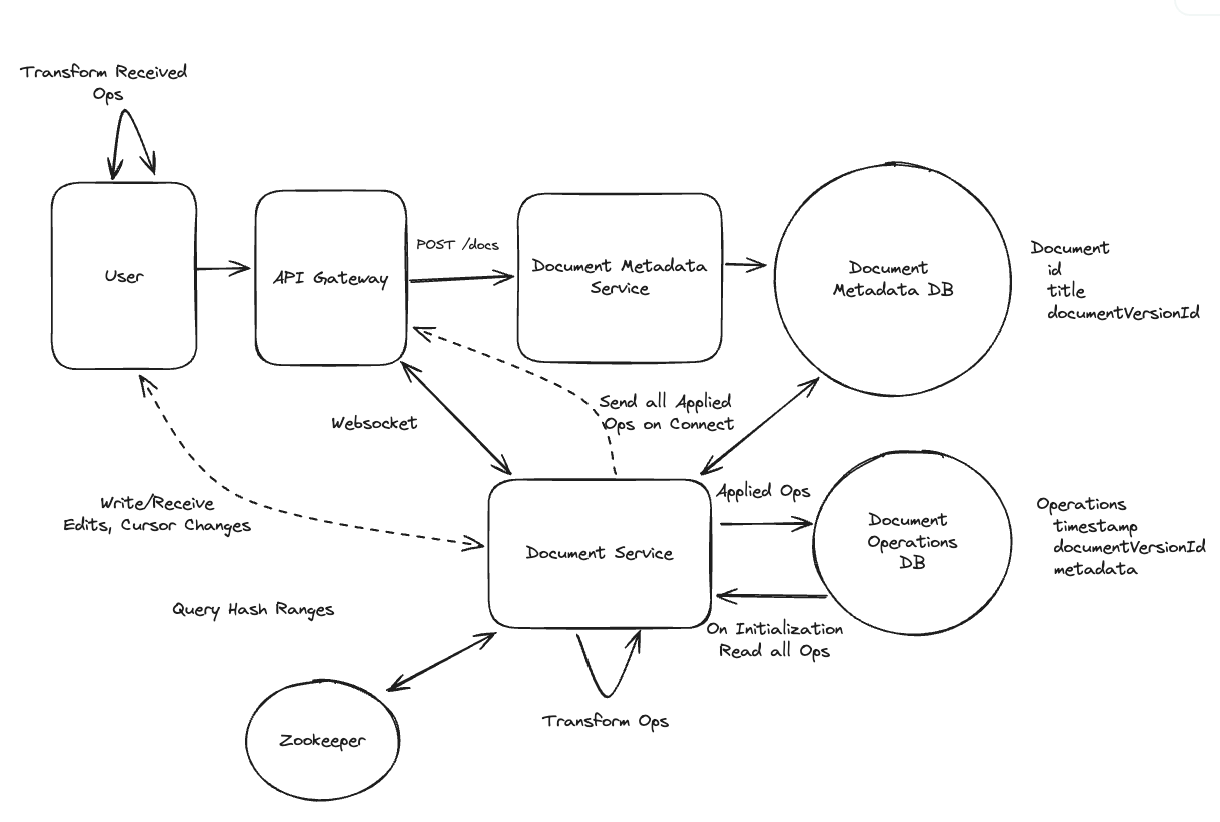
45. Design Youtube
45.1. Functional Requirements
-
Users can upload videos.
-
Users can watch (stream) videos.
45.2. Non-functional requirements

45.3. Entities

45.4. API Design

45.5. How will users be able to upload videos?
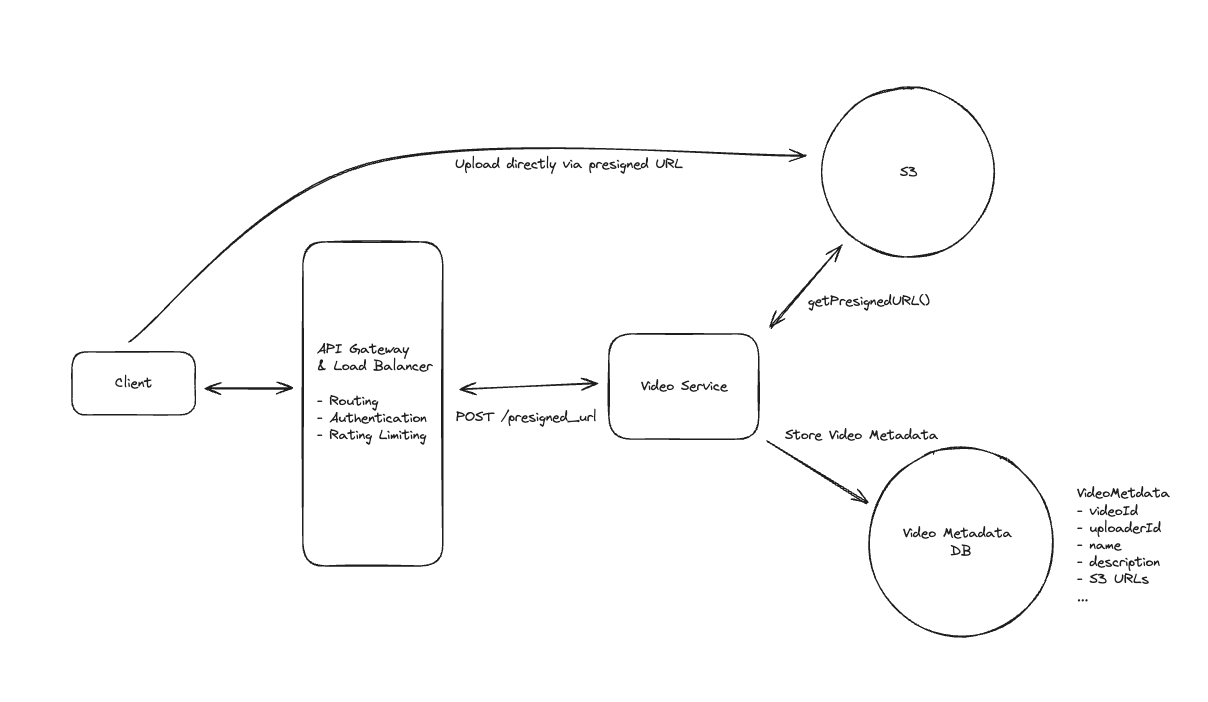
45.6. How will users be able to watch (stream) videos?
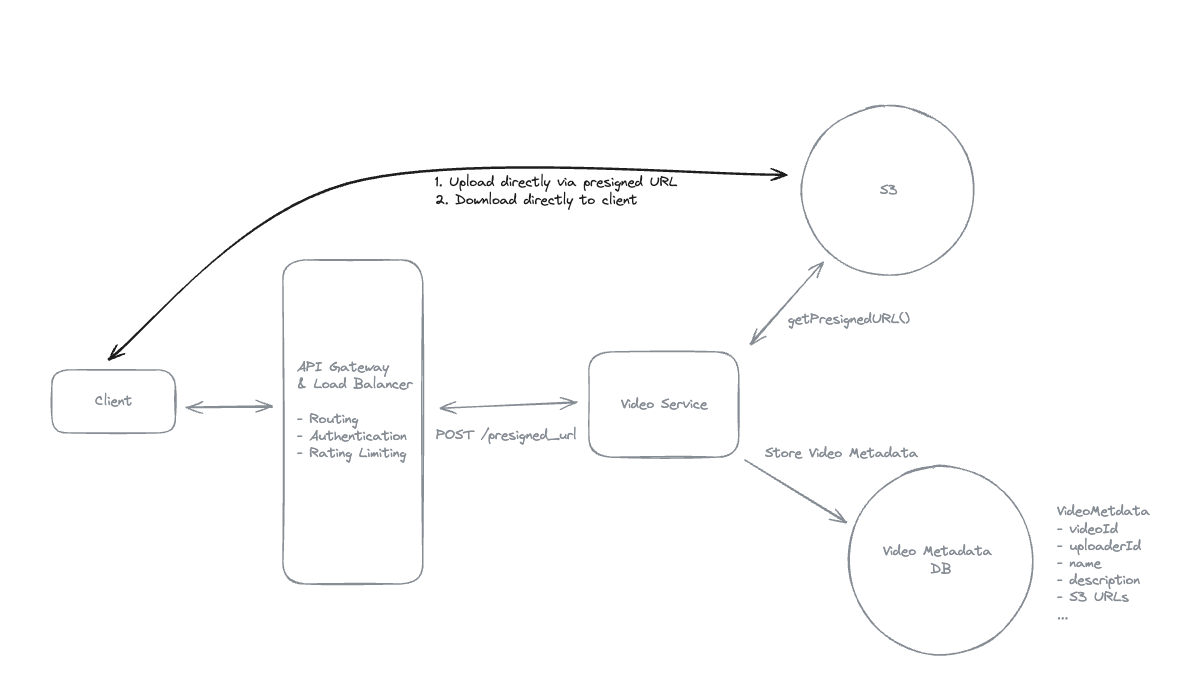
45.7. Users may have poor or fluctuating network connections. How would you design your system to ensure that video streaming continues smoothly under these conditions?
- Video Processing Service: 240p, 360p, 480p, 720p, and 1080p => multiple chunk to download by bandwidth.
![]()
45.8. Uploading large video files can be challenging due to network interruptions. Explain how your design allows users to resume an interrupted upload without starting over from scratch.
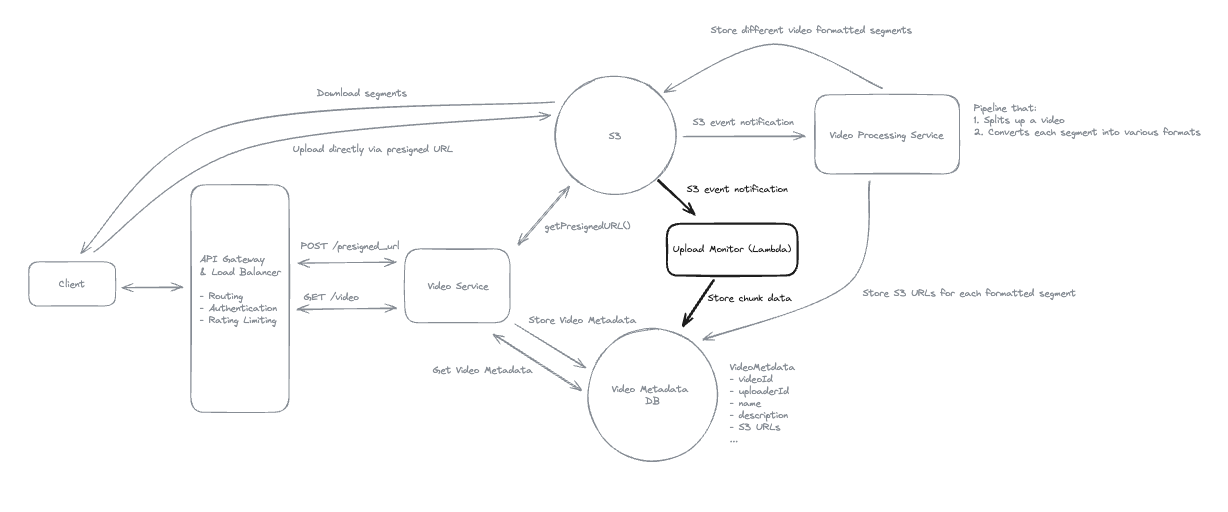
45.9. How would you design your system to allow users to resume watching a video from where they left off, even if they switch devices?
- To allow users to resume playback on different devices, the client application periodically sends the current playback position to the Video Service via the API Gateway.
=> Continue to playback position in metadata.
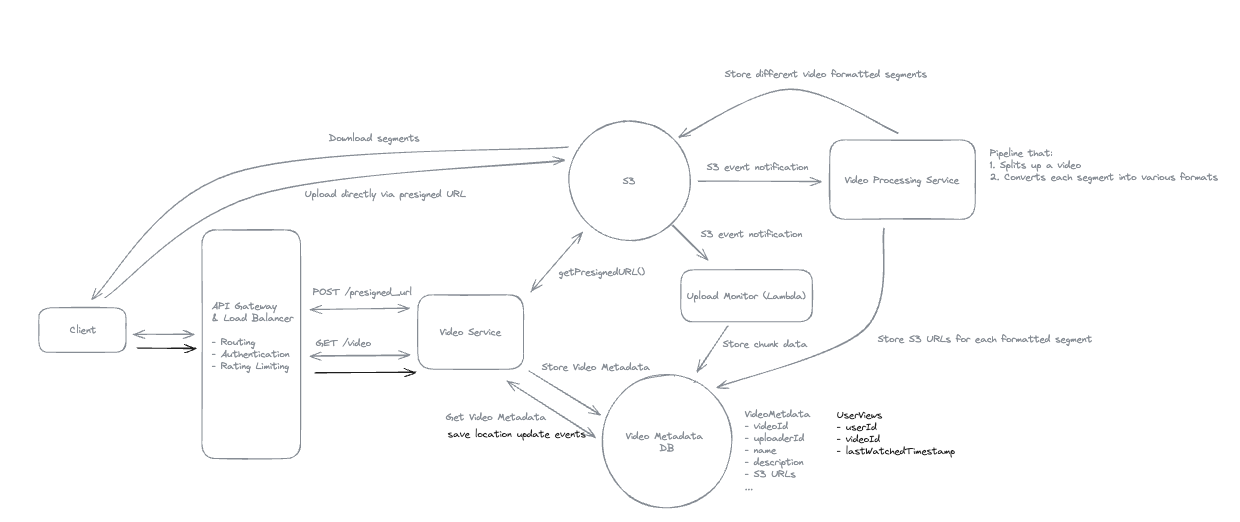
46. Design Instagram
46.1. Functional requirements
-
Users should be able to create posts featuring photos, videos, and a simple caption
-
Users should be able to follow other users
-
Users should be able to see a chronological feed of posts from the users they follow
46.2. Non-functional requirements

46.3. Entities

46.4. API Design

46.5. How will users create posts with photos or videos?
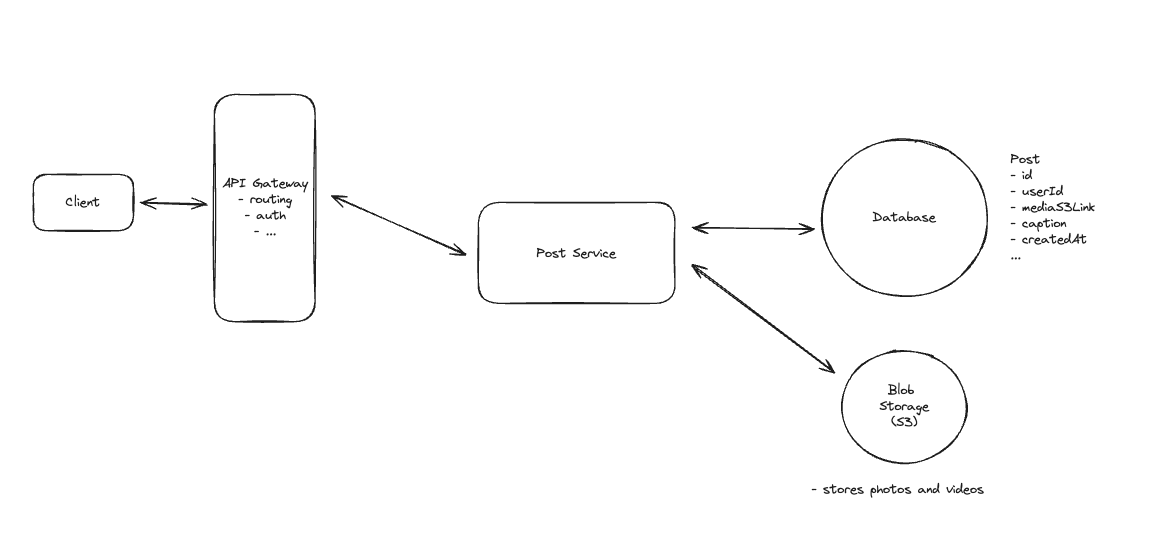
46.6. How will users follow other users?
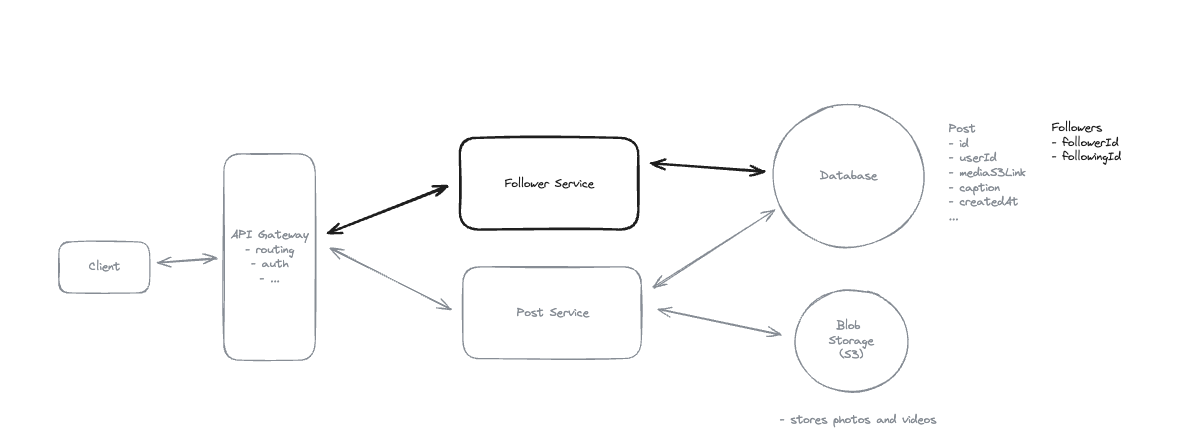
46.7. How will users see a chronological feed of posts from users they follow?
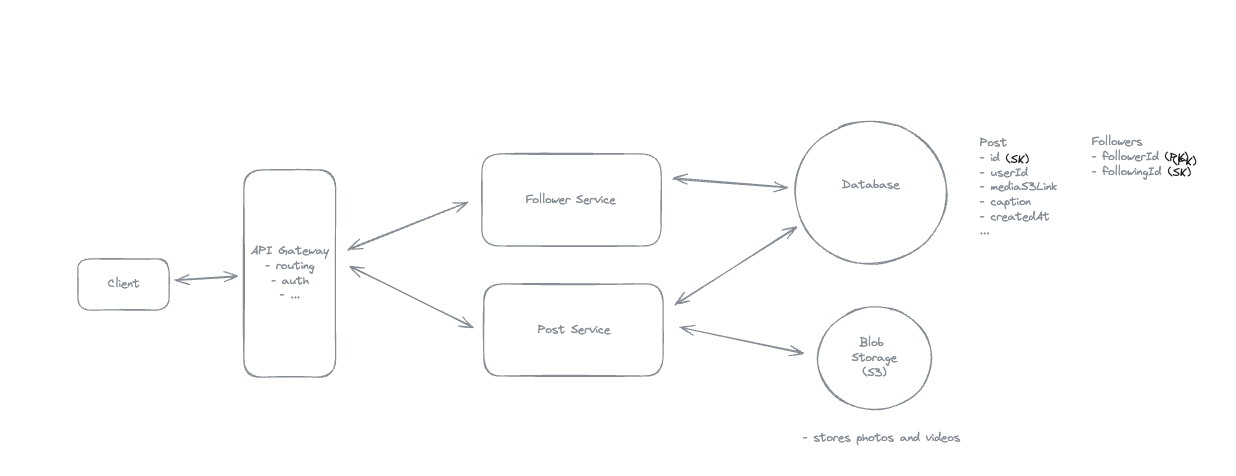
46.8. How would you scale the feed generation to support users who follow thousands of accounts while maintaining low latency?
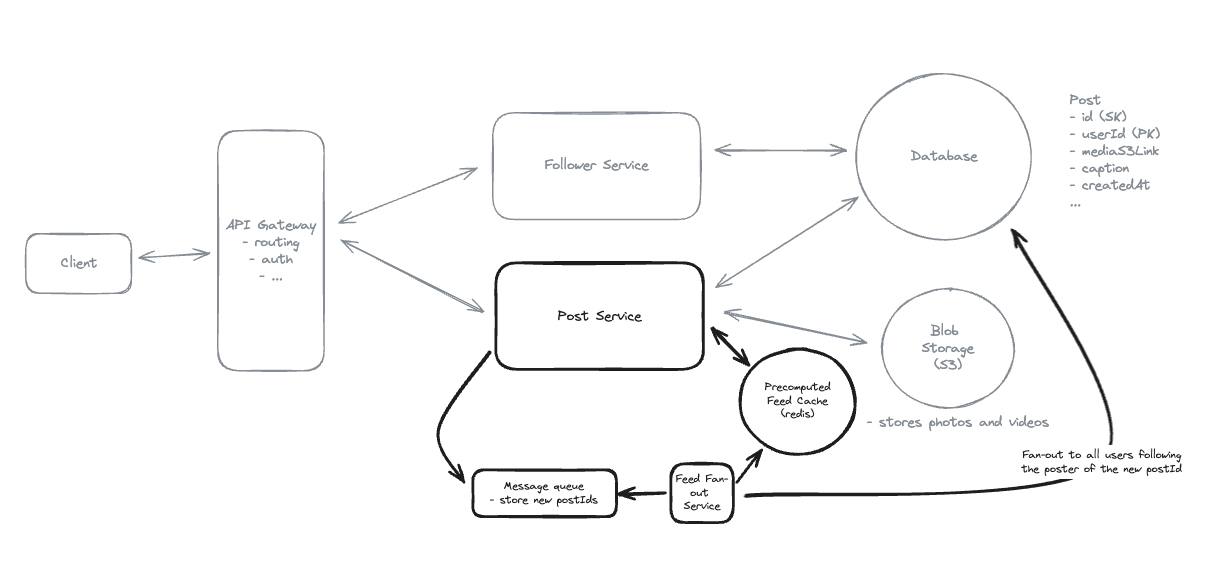
46.9. How would you handle the upload of large media files efficiently, particularly videos that could be up to 4GB in size?
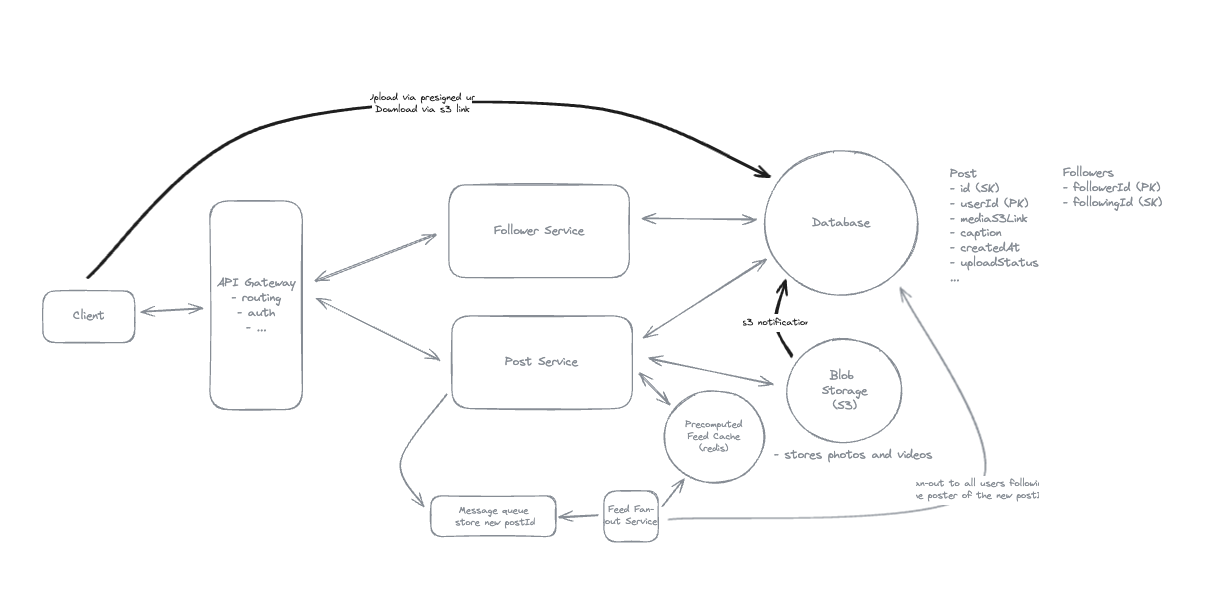
46.10. How would you ensure fast media delivery to users globally, with photos and videos rendering quickly regardless of a user’s location?
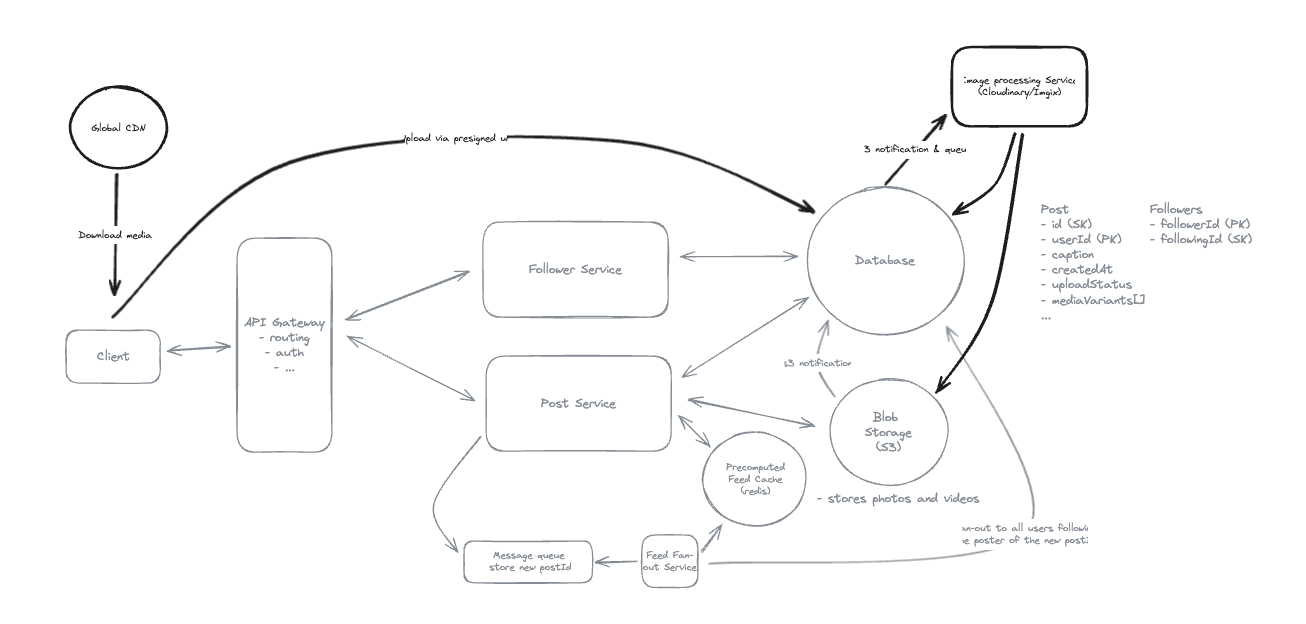
46.11. Which is NOT a characteristic of in-memory data stores?
-
AOF: Append-only file, each change snapshot 1 time.
-
Snapshot: save in dumb.rdb, 1 hour or 100 keys changed.
46.12. Fan-out on write pushes updates to all relevant destinations when data is created or modified.
- Yes
46.13. When generating a social media feed from followed accounts, which approach minimizes read latency for most users?
- Precompute feeds when content is posted.
46.14. When generating a social media feed from followed accounts, which approach minimizes read latency for most users?
- Precomputing feeds (fan-out on write) during content creation eliminates the need to aggregate data from multiple sources at read time.
46.15. When designing Instagram’s media upload system for files up to 4GB, what is the primary architectural decision that enables both upload reliability and direct client-to-storage efficiency?
- Using pre-signed URLs with multipart uploads to allow direct client-to-S3 transfers
47. Design WhatsApp
47.1. Functional Requirements
-
Users should be able to start group chats with multiple participants (limit 100).
-
Users should be able to send/receive messages.
-
Users should be able to receive messages sent while they are not online (up to 30 days).
-
Users should be able to send/receive media in their messages.

47.2. Entities

47.3. API Design
- Use Websocket for clients to connect to server. We need to specify both the commands that are sent to the server and those received by the client.

47.4. Create chats and add participants
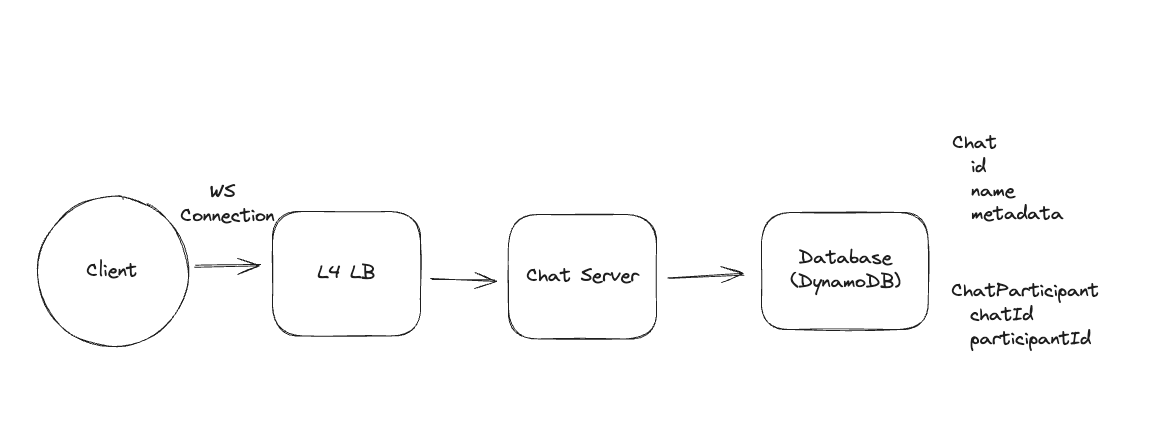
- We’ll include a GSI so that we can look up participants by chatId or chatIds by participant.
47.5. Update the design to allow users to send and receive messages.
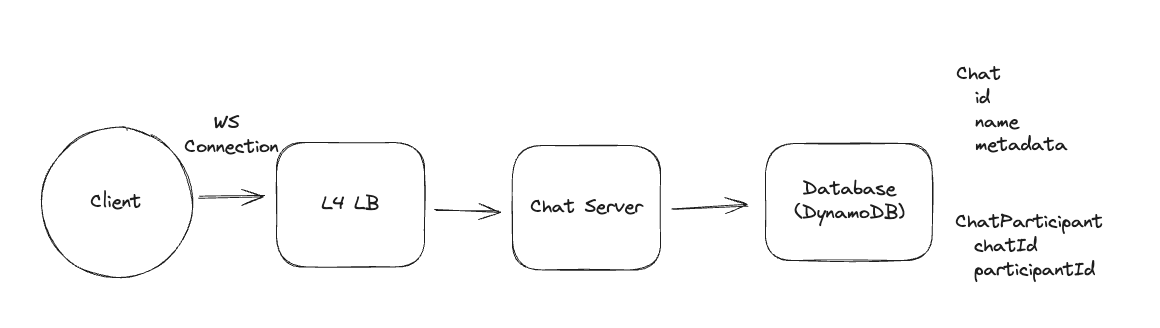
47.6. Extend the design to allow users to receive messages later if their client is offline
-
When user online => first time, broadcast the messate to the client or fetch API.
-
While chat, using websocket to handle send/receive message.
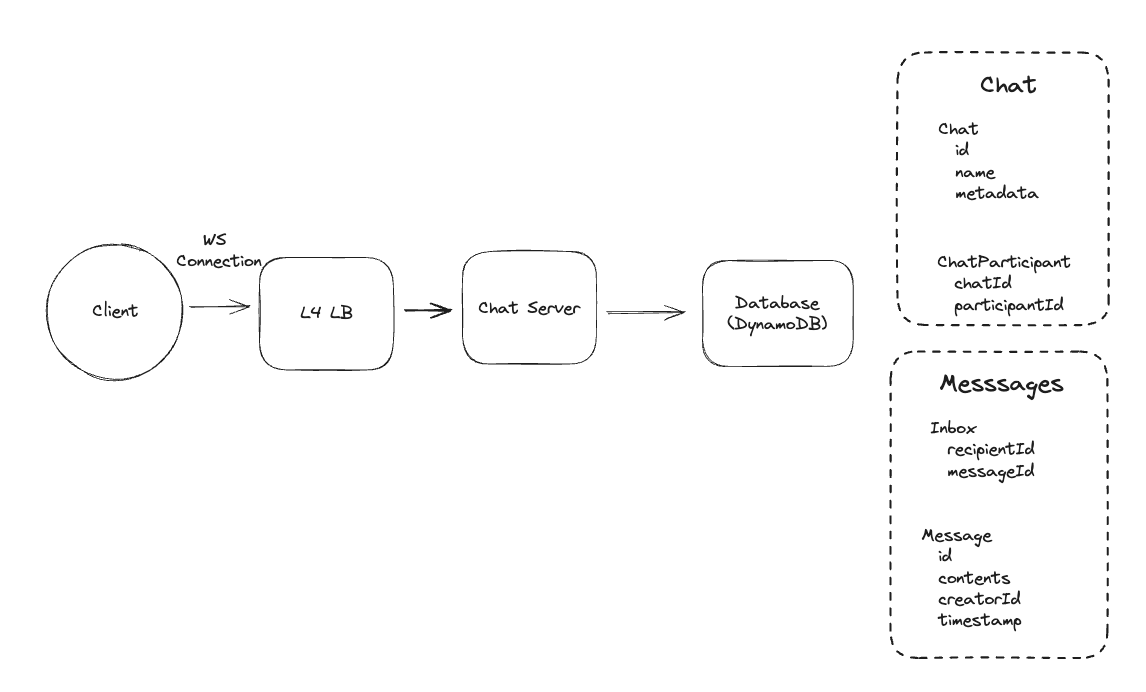
47.7. How can we send/receive media attachments in messages?
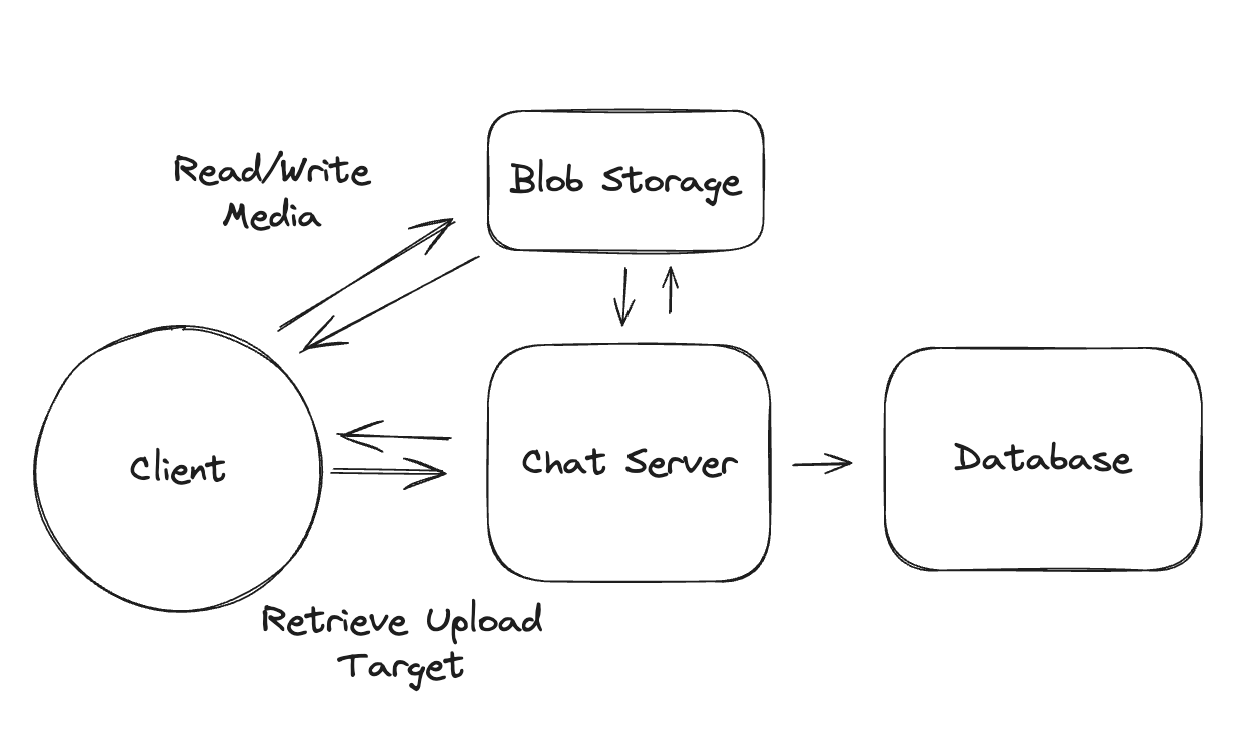
47.8. How can we enable billions of simultaneous users?
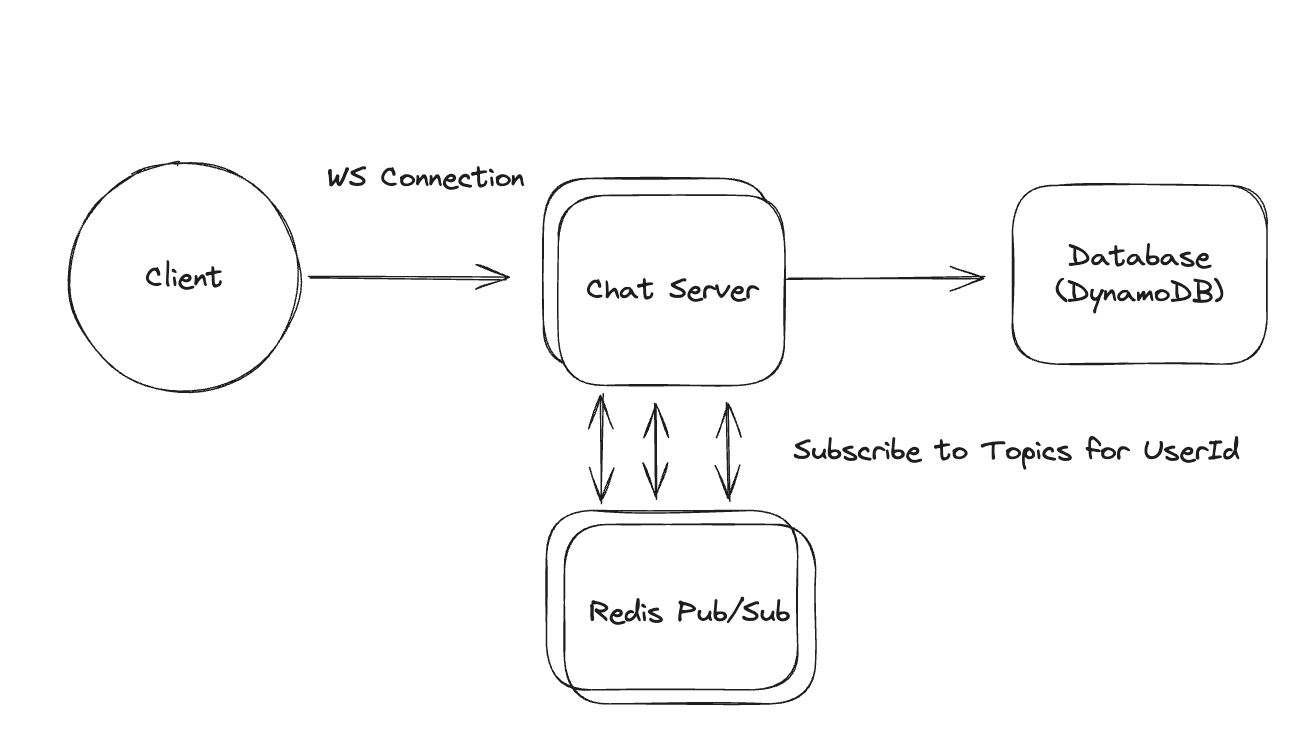
47.9. What do we do to handle multiple clients for a given user?
- We’ll need to create a new Clients table to keep track of clients by user id by devices.
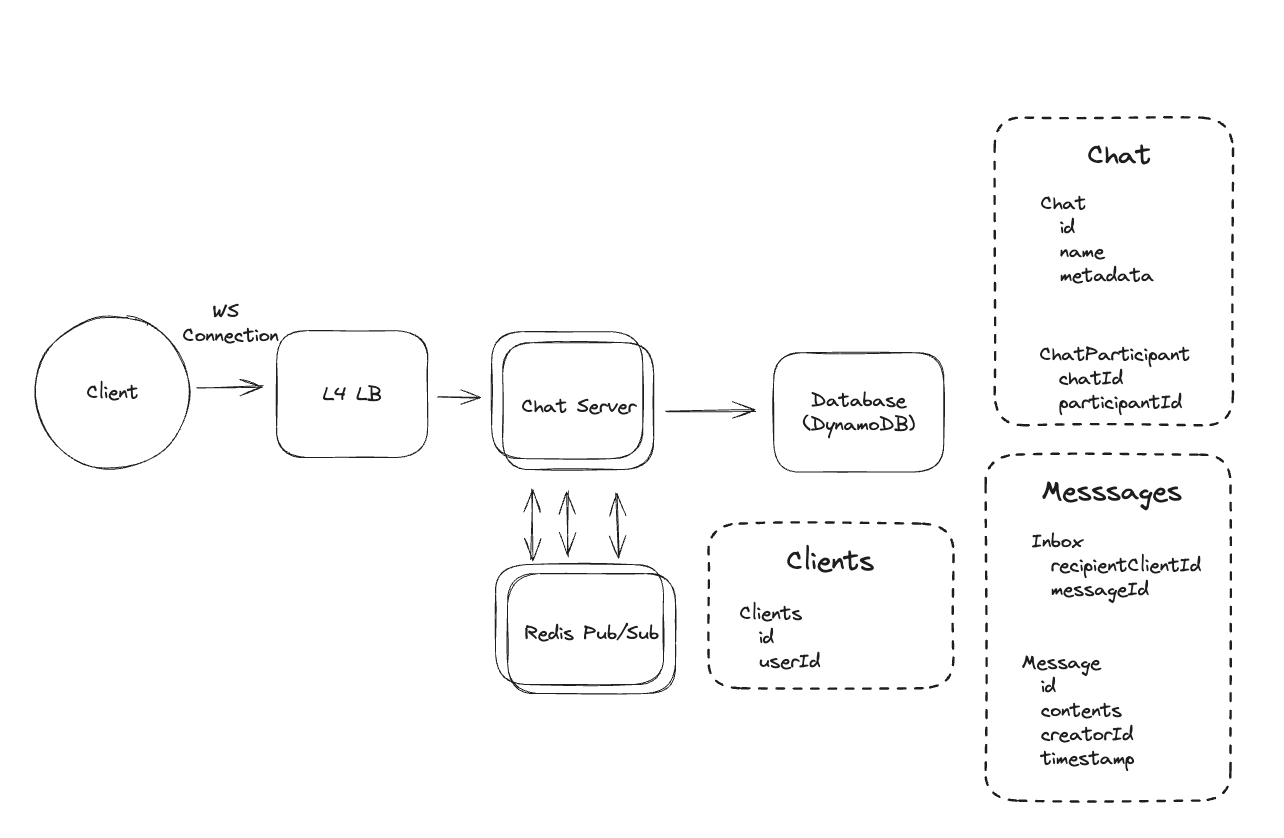
47.10. WebSockets maintain persistent bi-directional connections between clients and servers.
- Yes
47.11. Acknowledgment patterns in message systems benefits.
-
Enables retry logic
-
Prevents message loss
-
Confirms message delivery
47.12. Eventual consistency guarantees convergence of replicas when updates stop.
-
In eventually consistent systems, if no new writes arrive, all replicas will eventually reach the same state.
-
Although reads may see stale data in the meantime.
47.13. Which technique helps distribute load evenly when servers are added or removed?
-
Consistent Hashing
-
Add/Delete any nodes => we distributed traffic to another nearest node.
47.14. What is the MOST challenging aspect of scaling stateful WebSocket connections?
- Connection routing
47.15. A messaging system must guarantee delivery to offline users. Which pattern works best?
- The Inbox pattern stores undelivered messages in persistent storage until recipients come online and acknowledge receipt.
47.16. Database to store structured query, blob store in blob storage e.g. S3
- Yes
47.17. What happens when WebSocket users connect to different servers but need to communicate?
-
Solution: Messages need routing between servers.
-
When users are on different servers, the system needs routing mechanisms like pub/sub or direct server-to-server communication to deliver messages across server boundaries.
47.18. Which approach BEST ensures message delivery in systems with intermittent connectivity?
- Persistent storage combined with acknowledgment patterns ensures messages survive server restarts and network issues.
47.19. Persistent connections patterns
-
Pub/Sub routing
-
Consistent hashing
-
Connection pooling
47.20. A system processes millions of location updates per second. Which storage approach works best?
- In-memory with batch writes to disk.
47.21. Pub/Sub systems guarantee message delivery even when no subscribers are listening.
Solution: Most pub/sub systems provide ‘at most once’ delivery, meaning messages are lost if no subscribers are listening.
- False