
System Design - Components
Here is some notes for components of System Design.
1. C.O.R.E.M Principle
-
C: Constrain
-
O: Outline the high-level blueprint.
-
R: Refine for reality.
-
E: Eveluate the trade-offs about 6 pillars.
-
M: Measure
1.1. C - Contrain
-
Scope, Scale, Security.
-
Functional, Non-functional
-
Empathy-driven design.
1.2. O - Outline high-level blueprint
-
Data
-
APIs
-
Services: service boundary
1.3. R - Refine for Reality:
1.3.1. Scaling
-
Load Balancing: Your First Step to Scaling
-
Caching: The Art of Reducing Latency
-
Content Delivery Networks (CDNs): Bringing Data Closer to the User
-
Database Scaling Part 1: Replication and Read Replicas
-
Database Scaling Part 2: Sharding and Federation
1.3.2. Handling Exception
-
Message Queues: Decoupling Your Services for High Availability
-
Redundancy and Failover: Eliminating Single Points of Failure
-
The Circuit Breaker Pattern: Preventing Cascading Failures
1.3.3. Security
-
Authentication vs. Authorization: Who Are You and What Can You Do?
-
A Practical Look at OAuth 2.0
-
The API Gateway: Your System’s Fortified Front Door
1.4. E - Evaluate the Trade-offs
-
There are always have trade-offs.
-
Using a Trade-off Matrix to Justify Your Decisions
-
The CAP theory
1.5. M - Measure
-
Logging
-
Metrics
-
Tracing.
-
Dashboards and Alerting
1.6. Detail Interview Questions
1.6.1. Gather information
- To do
1.6.2. API Design
- To do
1.6.3. High-level design
- To do
1.6.4. Data Schema
- To do
1.6.5. Deep dive (Refine)
- To do
1.6.6. Communication Tips
- To do
2. System Design Principles
2.1. Consistency Patterns
- Weak consistency:
-
After write, reads may or may not see it, no guarantee when to see it, only when the system try to make new requests => maybe the system serves stale data indefinately.
-
Example: Memcached, it work in real-time use cases: VoIP, video chat, real-time multilayer games.
- Eventual consistency:
-
After write, reads will eventually see it (typically within miliseconds). Data is replicas asynchronusly.
-
Example: Read replicas, DNS.
- Strong consistency:
-
After write, reads will see it. Data is replicated synchronuosly.
-
Example: RDBMS
2.2. Availability Patterns
2.2.1. Fail-over:
- Active-passive:
- Depend on hot or cold standby.
- It also be called master-slave failover.
- Example: MySQL DBMS, based on master-slave.
- Active-active:
- Both servers are managing traffic, spreading the load between them.
- It also be called master-master failover.
- Example: NoSQL DBMS, Cassandra, DynamoDB, based on master-master.
2.2.2. Replication:
- Master-slave replication:
- Master: client write to master => sync data asychronously to slaves.
- Slaves: serve only read for client.
- If the master goes down, the system allow read-only mode in slaves => Until a slave is promoted to a new master.
- Master-master replication:
- Master: client write to master => sync data asychronously to other master.
- If a master goes down, the system can operate both read and write operations.
- Cons: Violate ACID pricinple, conflict resolution.
- Disadvantages bor both:
-
Loss data: can happened when master write data.
-
Write multiple data => stuck the read replicas.
-
More read replicas, the more you have to replicate => replica lag.
-
Costly and Complexity.
2.2.3. Availability in numbers
- 99.9% availability - three 9s
- Downtime per year: 8h 45min 57s
- Downtime per month: 43m 49.7s
- Downtime per week: 10m 4.8s
- Downtime per day: 1m 26.4s
- 99.99% availability - four 9s
- Downtime per year: 52min 35.7s
- Downtime per month: 4m 23s
- Downtime per week: 1m 5s
- Downtime per day: 8.6s
- Calculate availability
- In sequence:
Availability (Total) = Availability (Foo) * Availability (Bar)
- In parallel:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
2.3. Consistency and Availability
- CAP Theory:
-
Consistency: read receive most recent write or error.
-
Availability: request must receive response.
-
Partition Tolerance: the system continue to operate despite a partitioning failed by network error.
- CP - consistency and partition tolerance:
-
Waiting a response from parititoned node => timeout error.
-
Use cases: MySQL DBMS.
-
Notes: Have timeout error => Must be C.
- AP - availability and partition tolerance
-
Response can return from any node => data might not be the latest.
-
Use cases: Eventually consistency system.
- CA - consistency and availability:
-
Due to the network is unreliable, so we can not make sure partition tolerant work on-time.
-
CA only happens in single-node.
2.4. Performance vs scalability
-
If you have a performance problem, your system is slow for a single user.
-
If you have a scalability problem, your system is fast for a single user but slow under heavy load.
=> Performace is latency for a user, scalability is latency for heavy-load.
2.5. Latency vs throughput
-
Latency is the time to perform some action or to produce some result.
-
Throughput is the number of such actions or results per unit of time.
=> Maximize throughput with acceptable latency.
2.6. Scalability
- Vertical scaling:
-
Pros: simple to implement
-
Cons: Single points of failure.
- Horizontal scaling:
-
Pros: Better fault tolerance
-
Cons: Data inconsistency
2.7. Storage
2.7.1. Disk (RAID)
RAID (Redundant Array of Independent Disks) is a way storing same data in HDDs (hard-disks) and SSDs to protect data in drive failure.
=> Backup replica data.
Categorize by RAID types:
- RAID 0: Data is split into blocks and written across both drives.
Example: If you save a file:
-
Block A → Drive 1
-
Block B → Drive 2
-
Block C → Drive 1
-
Block D → Drive 2
=> Fault tolerance: ❌ If one drive dies → all data lost.
- RAID 1: Every file is copied to both drives.
Example: If you save a file:
-
File A → Drive 1
-
File A (copy) → Drive 2
=> Fault tolerance: ✅ If Drive 1 dies, Drive 2 still has everything.
- RAID 5: Data is striped across drives, but one drive stores parity (XOR math). Parity rotates between drives.
Example:
-
Drive 1: Data A Parity C -
Drive 2: Data B Data C -
Drive 3: Parity AB Data D
=> Fault tolerance: ✅ If any 1 drive fails, parity can rebuild the missing data.
- RAID 6: Like RAID 5, but two drives worth of parity are spread across all disks.
Example:
-
Drive 1: Data A Parity 1 -
Drive 2: Data B Parity 2 -
Drive 3: Data C Parity 1 -
Drive 4: Data D Parity 2
=> Fault tolerance: ✅✅ Can survive 2 drive failures.
- RAID 10: First, data is mirrored in pairs.
File A → Drive 1 + Drive 2
File B → Drive 3 + Drive 4
Then striped across pairs.
Example:
-
If Drive 1 fails, Drive 2 has the copy.
-
If Drive 3 fails, Drive 4 has the copy.
Usage:
✅ In practice:
-
Home PCs / Gaming: RAID 0 or no RAID
-
Small businesses: RAID 1 or RAID 5
-
Enterprise storage: RAID 5, 6, or 10 (depending on performance vs. safety needs)
2.7.2. Volumes
Volume is a fixed amount of storage on a disk or tape.
- File storage:
- File storage is a solution to store data as files and present it to its final users as a hierarchical directories structure.
- Block storage:
-
Block storage divides data into blocks (chunks) and stores them as separate pieces.
-
When a user or application requests data from a block storage system, the underlying storage system reassembles the data blocks and presents the data to the user or application
=> Block storage must be store in the single node.
- Object Storage:
- Object storage, which is also known as object-based storage, breaks data files up into pieces called objects => can store in multiple network system.
=> Object storage can be store in multiple nodes.
2.8. Network
2.8.1. NAS
- NAS (Network Attached Storage): A centralized storage system connected to a network that provides file-level access to multiple clients.
=> Like a big external hard drive connected to your office network
2.8.2. HDFS
- HDFS (Hadoop Distributed File System): a distributed file system designed for storing and processing huge datasets (TB–PB scale) across clusters of commodity hardware => manage files.
=> Like a huge warehouse where files are cut into chunks and spread across many storage units, with backups.
3. System Design Components
3.1. DNS
- Hierachical and decentralized naming system.
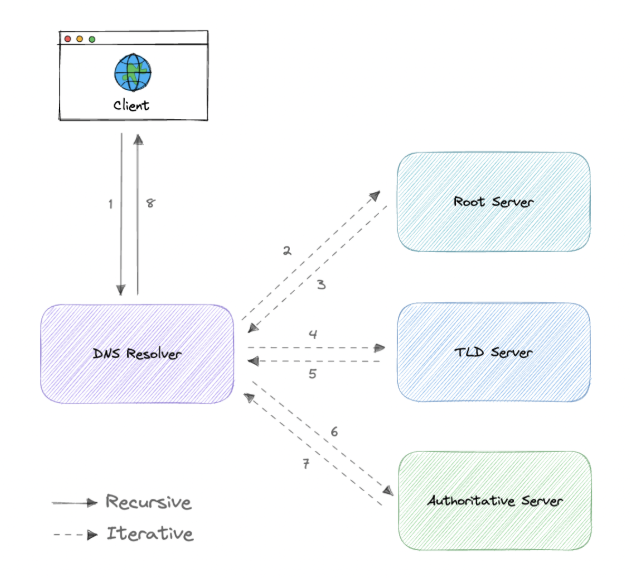
3.1.1. Resolver Process
-
Step 1: Query to Root server first => (.com, .net, .org,…) => Send it to TLD nameserver.
-
Step 2: TLD nameserver resolve by .com, .net => generate top-level domains (.com, .org, .edu) and country code top-level domains (.us, .uk,…) => Send it to Authoritative DNS server.
-
Step 3: Authoritative DNS server resolve in nearest geography resolve it in DNS A record, CNAME record => return IP address, else fallback to NXDOMAIN message.
3.1.2. Query Type
- Recursive:
- If it has the result cached → returns it.
- If not → it contacts other DNS servers on your behalf (root → TLD → authoritative).
- It only returns the final answer (or an error) to you.
- Pros: Simple for the client (only one request).
- Cons: More load on the recursive resolver.
- Iterative:
- It asks a root server → gets referral to TLD server.
- It asks the TLD server → gets referral to authoritative server.
- It asks the authoritative server → finally gets the IP.
- Pros: Client has more control.
- Cons: More requests to multiple DNS server.
- Non-recursive
-
Query from local cache.
-
Static IP: config static.
-
Dynamic IP: using DHCP.
-
Every DNS response includes a TTL (set by the domain owner in their authoritative DNS), your resolver caches it for at most 300 seconds (5 min).
-
Worst case: connections fail until TTL expires.
3.1.3. Record Types
-
A (Address record): hold IPv4 of a domain.
-
AAAA (IP Version 6 Address record): hold IPv6 of a domain.
-
CNAME (Canonical Name): This domain name is just another name for that domain.
www.example.com CNAME example.com.
-
MX (Mail exchanger record): which mail server(s) are responsible for receiving email for a domain.
-
TXT (Text Record): this is a DNS record used to store arbitrary text information about a domain.
-
NS (Name Server records): Specifies the authoritative name servers for a domain.
example.com. IN NS ns1.exampledns.com.
example.com. IN NS ns2.exampledns.com.
- SOA (Start of Authority): Defines important administrative information for a DNS zone.
example.com. IN SOA ns1.exampledns.com. admin.example.com. (
2025090501 ; serial
7200 ; refresh
3600 ; retry
1209600 ; expire
86400 ) ; minimum TTL
-
SRV (Service Location record): Specifies the location (hostname + port) of specific services (e.g., SIP, XMPP, LDAP).
-
PTR (Reverse-lookup Pointer record): Maps an IP address → domain name (reverse DNS lookup).
10.2.0.192.in-addr.arpa. IN PTR mail.example.com.
- CERT (Certificate record): Stores cryptographic certificates (PKIX, PGP, SPKI) in DNS.
3.1.4. Subdomains
-
A subdomain is an additional part of our main domain name. It is commonly used to logically separate a website into sections.
-
Each subdomain can have its own DNS records, independent of the root domain.
3.1.5. DNS Zones
-
A domain (like example.com) can be split into multiple zones, or all records can live in one zone.
-
You can delegate a subdomain to a different zone.
=> Manage in different authoritative name servers.
3.1.6. DNS Caching
-
A DNS cache (sometimes called a DNS resolver cache) is a temporary database, maintained by a computer’s operating system that contains records of all the recent visits and attempted visits to websites and other internet domains.
-
The Domain Name System implements a time-to-live (TTL) on every DNS record.
=> Store in local computer.
3.1.7. Reverse DNS
- Normally, DNS resolution goes:
domain → IP (via A/AAAA records).
- Reverse DNS does the opposite:
IP → domain (via PTR records).
- Look up in PTR (Reverse-lookup Pointer record)
192.0.2.10 -> 10.2.0.192.in-addr.arpa
10.2.0.192.in-addr.arpa. IN PTR mail.example.com
Result;
192.0.2.10 -> mail.example.com
-
Use cases: Email servers check and see if an email message came from a valid server before bringing it onto their network
-
If IP do not have DNS => it map the IP to NXDOMAIN.
-
IP can split by geographic area.
3.2. Load Balancer
We can add load balancer to multiple layers of the system.
3.2.1. Workload distribution
-
Host-based: Distributes requests based on the requested hostname.
-
Path-based: Using the entire URL to distribute requests as opposed to just the hostname.
-
Content-based: Parameter of the requests.
3.2.2. Layers
-
Network layer: Load balancing in layer 4, only route traffic by host-based and path-based routing.
-
Application layer: Load balancing in layer 7, can route traffic by content-based routing.
3.3.3. Type of load balancing
-
Software
-
Hardware
-
DNS
3.3.4. Routing algorithms
-
Round-robin: rotation distributed to application servers.
-
Weighted round-robin: round by weights.
-
Least connection: route to the least connection traffic.
-
Least response time: route to the fewest response time and active connections.
-
Least bandwidth: route to server with least bandwidth.
-
Hashing: distributed requests by hash key.
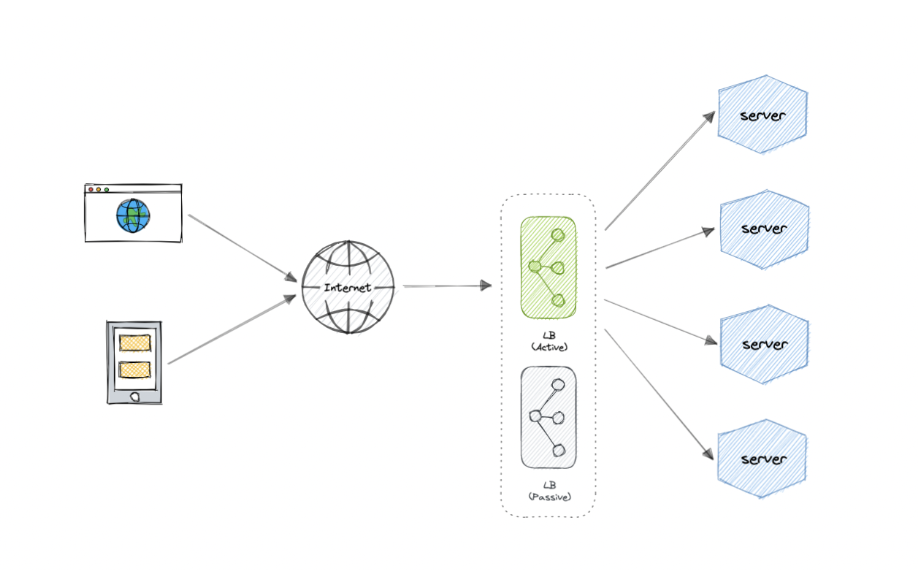
3.3.5. Load balancer is a single-point-of-failure ?
Solution: Apply active-passive strategy for load balancers.
3.3.6. Features
-
Health check.
-
Sticky session.
-
Auto scaling.
3.3. API Gateway
- Client -> API Gateway -> Load Balancer -> Service.
3.4. CDN
3.4.1. How does CDN work ?
- In a CDN, the origin server contains the original versions of the content of the edge servers.
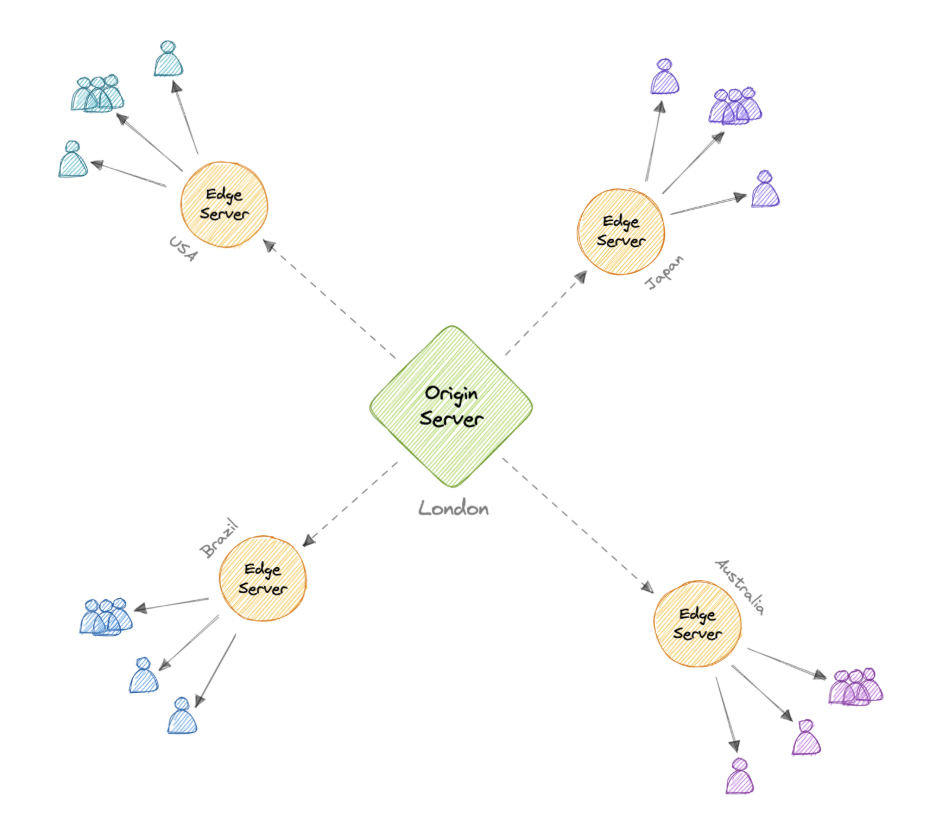
- Use IP-based geolocation from users requests => Find it in DNS authorization server with nearest location (Singapore).
3.4.2. CDN Types
- Push CDNs:
- Update new content when users update the resources in origin object servers
=> Same as write-through strategy.
- Pull CDNs:
- Client query CDN -> If CDN do not have data, it fetch the data in origin objects servers -> Update the CDN.
=> Same as cache-aside strategy.
3.5. Proxy
-
Client -> Proxy -> Make requests to server
-
Use to hide the IP of the server when calling to third-party server.
-
Notes: Nginx can be used to implement proxy or API gateway => Just a different of purpose.
3.5.1. Types
- Forward Proxy (VPN)
-
Client -> Proxy -> Server
-
The proxy is in client-side
-
Purpose: Hidden IP of client
-
Example: VPN
- Reverse Proxy
-
Client -> Proxy -> Server1, Server2, Server3
-
The proxy is in server side
-
Purpose: Hidden IP of server
-
Example: Load Balancer
3.6. Caching
3.6.1. CPU Cache & Memory
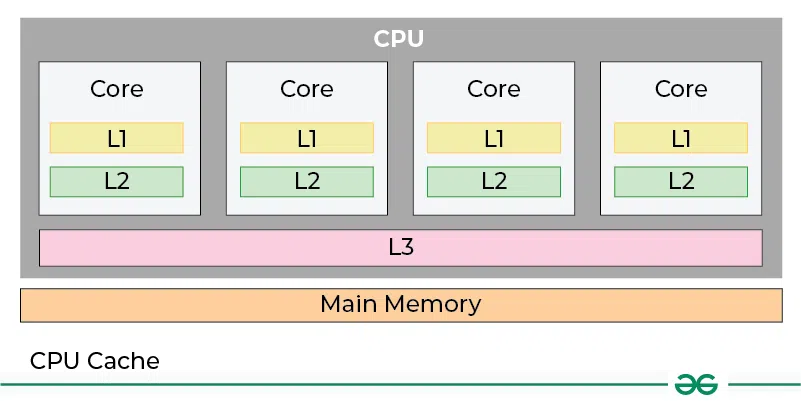
-
L1: stored in each CPU (per-core), store the frequent access data.
-
L2: stored in each CPU (per-code), store in a less frequent access data.
-
L3: shared by general all CPUs => store a large data of general keys.
=> Register > L1 > L2 > L3 > … > Ln > RAM.
Notes: Register store variables when calculate in CPU, but not cache.
3.6.2. Types
-
A hot cache: fastest possible access, data is retrieved from L1.
-
A cold cache: slowest possible access, data is retrived in the last caching layer, e.g. L3 or more.
-
A warm cache: the data is found in L2.
3.6.3. Cache Strategy
- Write-through: write in both cache and database
-
Pros: high consistency
-
Cons: higher latency in write.
- Cache-aside: client requests application, application fetch cache, if not found it query database and update cache.
-
Pros: Balance latency.
-
Cons: May have stale data.
- Read-through: same cache-aside, but cache pull database but not application
-
Pros: Balance latency.
-
Cons: May have stale data.
- Write-back cache: write cache first, asynchronously write database later
-
Pros: reduce latency.
-
Cons: Risk of loss data.
- Write-around cache: write database, not write cache, warm up later.
-
Pros: reduce latency
-
Cons: cache miss or stale data.
3.6.4. Policy
-
FIFO
-
LIFO
-
LRU: Least recently used.
-
MRU: Most recently used.
-
LFU: Least frequently used.
-
RR: Random replacement
3.6.5. Distributed Cache (usually cluster, less global cache)
Use cache cluster for center distributed cache with multiple nodes.
-
Pros: consistency cache
-
Cons: grow beyond the memory limits.
Notes:
-
Multiple nodes: cluster
-
Global cache: shared cache.
3.9. Reliability
3.9.1. Thundering Herd
- Multiple processes and threads is trigger for events
=> But only some of this proceses and threads works, and other threads are wasting resources.
Example: Linux, IOCP is work effectively than select/poll.
3.9.2. Circuit breaker
-
Have 3 states: Closed, Open, Half-open.
-
When a part of the system failed, it can isolate it and can not break the system.
-
Use cases: If a gateway of payment down, say “Payment system temporarily unavailable, please try again later.”
3.9.3. Rate Limiting
- Types:
- Leaky bucket: FIFO, and after a time a bucket is leaked
=> Manage requests for total requests to all service.
- Token bucket: the bucket requests after a period of time
=> Manage requests for total requests to all service.
-
Fixed Window: Each request increase the counter for the window.
-
Sliding log: track time-stamp log for the requests.
-
Sliding Window: Fixed Window + Sliding log
=> Manage requests for rate limiting requests per IP.
- Cons:
- Inconsistencies: Multiple nodes request to global rate limit => if rate limits per each node => users can make multiple requests to global rate limit.
=> Solution: Sticky session: 1 consumer -> 1 node.
- Race Conditions: error when “get-and-set” approach => race contidion.
=> Solution: Using distributed lock + “set-and-get” approach to increase the counter.
3.10. Database
3.10.1. Geohashing & Quadtrees
- Geohashing:
-
Store location in database.
-
Find the nearest neighbors through simple string comparisons.
Geohash length:
1 -> 5000 km x 5000 km 2 -> 1250 km x 1250 km 3 -> 156 km x 156 km …
Example: 9q8yy9mf and 9q8yy9vx is closer than they share the prefix 9q8yy9.
- Quadtrees:
- Enable to search point in two-dimensional range.
3.10.2. Database Federation
- Each requests to multiple database differently, but not only 1 database as datawarehouse.
For example:
-
A MySQL database for customer accounts
-
A MongoDB database for user activity logs
-
A Postgres database for orders
3.11. Message Queue
3.11.1. Message Queue
- Strategy:
-
Push or Pull Delivery:
- Pull means continuously querying the queue for new messages.
- Push means that a consumer is notified when a message is available
-
FIFO (First-In-First-Out) Queues
-
Schedule or Delay Delivery: schedule or delay time to receive message.
-
At-Least-Once Delivery
-
Exactly-Once Delivery
-
Dead-letter Queues
-
Ordering: Keep it in order.
-
Poison-pill Messages: can be received, but not processed => signal the consumer to end its work and never waiting for new messages => end the socket in a client/server model.
-
Security: encrypt message over the network.
-
Task Queues: queue for high computation-intensive jobs.
- Backpressure:
- Rejected to receive message when queue is full => Return HTTP 503 to the client.
- Exponent backoff:
This is retry strategy for client-side by increasing the times.
For example:
-
1st retry → wait 1 second
-
2nd retry → wait 2 seconds
-
3rd retry → wait 4 seconds
-
4th retry → wait 8 seconds
-
5th retry → wait 16 seconds
3.11.2. Message Broker
- Context:
- A Message Broker is middleware that routes, transforms, and delivers messages between producers and consumers.
=> Message Brokers is general concepts rather than message queue.
- Type:
-
Point-to-Point messaging: one-to-one relationship from sender to receiver.
-
Publish-Subscribe messaging: one-to-many relationship.
3.11.3. Enterprise Service Bus (ESB) - Design Pattern
- An Enterprise Service Bus (ESB) is an architectural pattern whereby a centralized software component performs integrations between applications.
3.11.4. Microservices, Monolithics and SOA
- Easy to answer, but need to compare pros and cons.
3.11.5. Event-Driven Architecture (EDA)
-
Event producers: Publishes an event to the router.
-
Event routers: Filters and pushes the events to consumers.
-
Event consumers: Uses events to reflect changes in the system.
3.11.6. Event-Driven Architecture (EDA)
-
Sagas
-
Publish-Subscribe
-
Event Sourcing: store data as event store to manage.
-
Command and Query Responsibility Segregation (CQRS)
3.11.7. Kafka
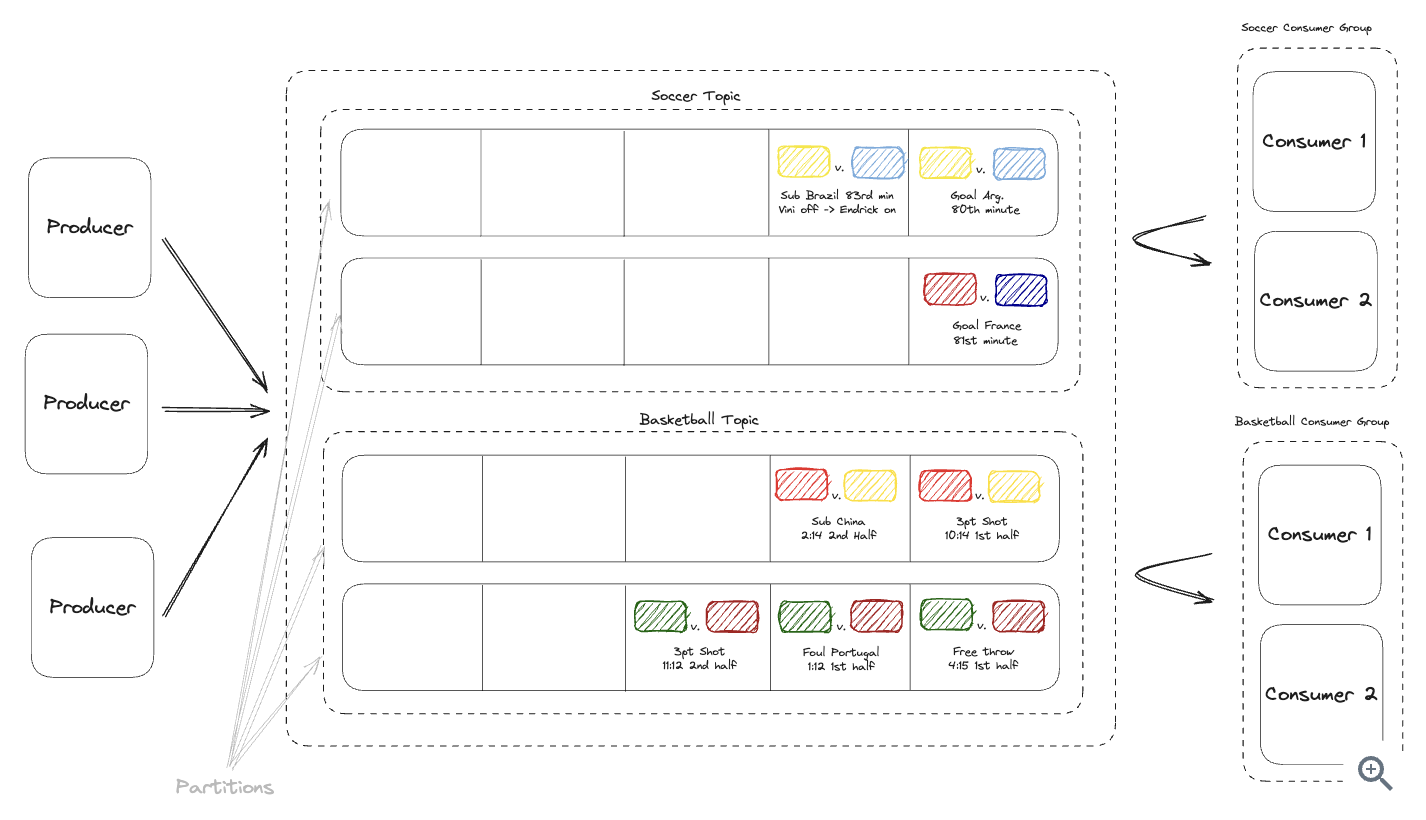
-
Topic: channel, 1 topic have multiple partitions.
-
Brokers: multiple brokers (server) => the more brokers you have, the more data you can store, the more clients you can serve
-
Partitions: an ordered, immutable sequence of messages that is continually appended to.
3.11.8. RabbitMQ
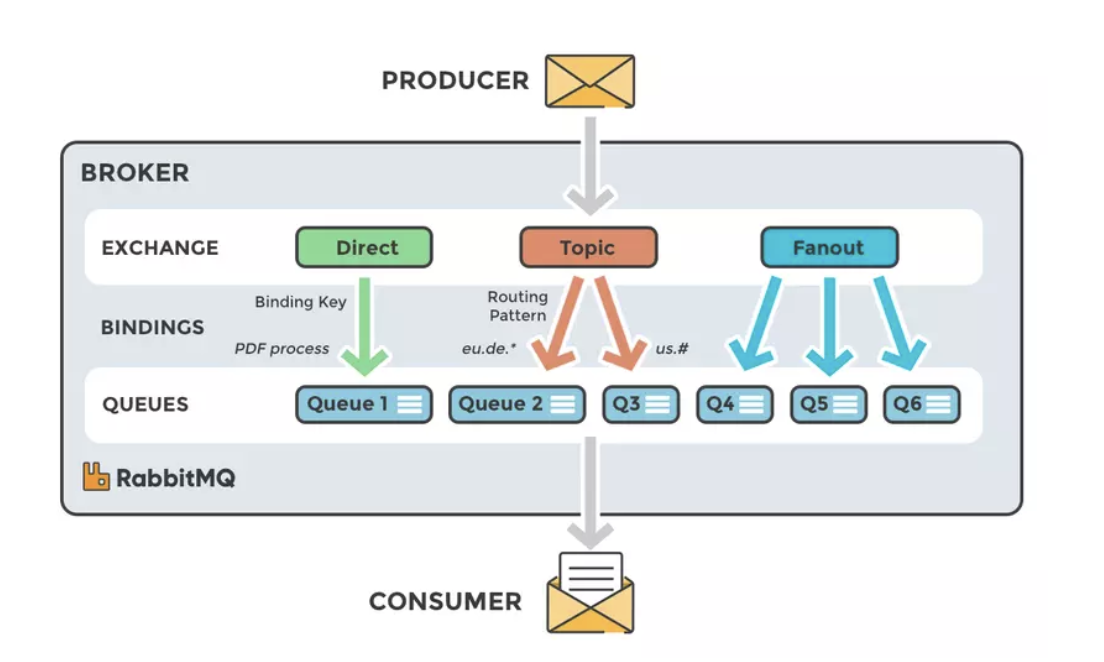
- RabbitMQ have different structure than Kafka.
Include:
-
Exchange: Direct, Topic, Fanout.
-
Queue: multiple queues, e.g. Queue 1, Queue 2, Q3, Q4,…
3.12. Security
3.12.1. OAuth2
- Components:
-
Resource Server: Merchant application, or the server that client requests to.
-
Authorization Server: the server receive client + requests access from resource server => create access token.
-
Resource Owner: tool to grant resources for oauth token.
-
Scopes: the scope that resource owner grant.
-
Access token: gen from scopes and client.
- How does OAuth 2.0 work:
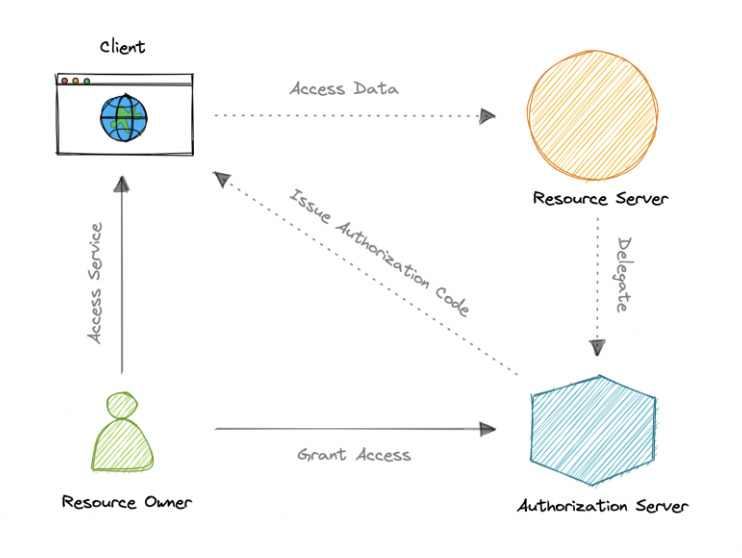
-
Step 1: Client access resource server => Make request to authorization server, send the scopes + fallback endpoint to send access token.
-
Step 2: The Authorization server verify the scopes and client are permitted.
-
Step 3: The Authorization Server call to resource owner to grant access.
-
Step 4: The Authorization Server redirects the access token to fallback URL, and refresh token.
-
Step 5: The Access token to access the resource server
- When to use OAuth2:
Example:
Step 1: You log into a fitness app and let it pull your step data from your Google Fit account.
Step 2: You don’t give the fitness app your Google username/password. Instead, you approve it via OAuth2.
=> In case merchant app Zalopay, you do not want to give username, password of Zalopay account to merchant app.
=> So you ask, do Zalopay trust user with username based on Zalopay OAuth service ?
3.12.2. OpenID Connect (OAuth2 underneath for Google Authentication)
- OpenID providers:
- OIDC: authenticate protocols for the web.
=> We use OpenID provider to check it.
-
Google → accounts.google.com
-
Microsoft Azure AD / Entra ID → login.microsoftonline.com
-
Apple → Sign in with Apple
-
Auth0 (Identity-as-a-Service)
- How it provides ?
OIDC adds authentication, OAuth2 for authorizations => OIDC add some information to the token.
-
sub → unique user ID
-
name, email, picture → profile claims
-
iss (issuer), aud (audience), exp (expiration)
=> Google: OAuth2 + OpenID
3.12.3. SSO
Single Sign-On (SSO): One login, many apps.
Different technologies can provide SSO:
-
OIDC (modern web/mobile apps).
-
SAML (common in enterprises).
-
Kerberos (Windows/AD environments).
-
CAS, Shibboleth, etc.
Notes: To be clearly, OIDC and SAML use to implement SSO
-
OIDC: OAuth2
-
SAML: XML.
3.13. Use cases login with Google (OAuth Design)
-
Resource Owner: You
-
Authorization Server: Google Accounts Server.
-
Resource Server: Google UserInfo API.
-
Scopes: Merchant App asking for.
-
Access Token: Token issues by Google
=> It means that Merchant App oauth with Google, and you are resource owner.
Question: How to implement it ?
Answer: Move to the diagram with the context
3.14. Hashing / Encryption
- Hashing:
-
One-way function: you can’t get the original data back.
-
Types: SHA-256 (256 bits), MD5 (128 bits) => some algorithm for hasing.
-
Use cases:
- Password storage (store only hash, not plain password).
- File integrity check (compare hash before/after download).
- Digital signatures.
- Encryption:
-
Two-way function: you can encrypt (lock) and decrypt (unlock).
-
Types:
- Symmetric encryption (same key for encrypt + decrypt): AES, DES.
- Asymmetric encryption (public/private key pair): RSA, ECC.
-
Use cases:
- Private communication.
- Why Hashing Cannot Roll Back but encryption can ?
Anwser:
=> Information Loss. Both inputs are very different lengths, but hashes are always 256 bits (in SHA-256).
=> Encryption can revese by bit shifting using private key and public key.
- HMAC encryption ?
-
Verify the checksum.
-
HMAC-SHA256(“secret-key”, “hello”) = f7bc83f430538424b13298e6aa6fb143ef4d59a14946175997479dbc2d1a3cd8
=> Same input + same key = same hash
Cons: Hashmap do not hide the message, RSA is long time encrytion.
- Usecase: Use to verify payload in payment system.
3.15. Use case: Money Transfer
- Encryption → Confidentiality
Your account number, balance, PIN, and transaction details must be hidden from attackers.
=> Encryption (AES, RSA, TLS) is used to secure the channel (HTTPS/TLS).
- Hashing → Integrity + Authentication
Add hashmap to HMAC payload used to:
-
To ensure data hasn’t been tampered with.
-
To verify messages are genuine.
=> HMAC used for verify the integrity of the payload.
3.16. SSL
-
Using asymetric encryption during handshaking phrase.
-
After handshanking phrase => Using symetric encryption.
4. System Design Dive Deep
4.1. Index
- What, Use case, Pros, Cons
4.2. Storage
- To do
4.3. Real-time data update
- To do
4.4. Concurrency control
- To do
4.5. Sharding
- To do
4.6. Distributed Transaction
- To do
4.7. Asynchronous Processing
- To do
4.8. Batch and Stream Processing
- To do
4.9. Lambda Architecture
- To do
4.10. Thundering Herd and Caching
- To do
4.11. Conflict Resolution
- To do
4.12. Timeout
- To do
4.13. Exponential Backoff
- To do
4.14. Buffering
- To do
4.15. Sampling
- To do
4.16. ID Generator
- To do
4.17. Compression
- To do
4.18. RabbitMQ, Kafka, Pub/sub
- To do
4.19. Pass Only Needed Data
- To do
4.20. Fail to Open
- To do
4.21. Cold Storage
- To do
4.22. Networking
- To do
4.23. Monitoring
- To do
4.24. Full-Text Search
- To do
4.25. Service Discovery and Request Routing
- To do
4.26. Microservice, Monolithics, SOA, Event Driven.
- To do
4.27. REST API, GraphQL, gRPC API
- To do